Clear Sky Science · it
SEA CDM: Modello di dati comune Study-Experiment-Assay e database per l'integrazione e l'analisi di dati trasversali
Perché organizzare i dati di laboratorio interessa a tutti
La medicina moderna è alimentata da montagne di dati sperimentali — da studi sui vaccini e sulle infezioni fino alla genomica del cancro. Tuttavia questi dati sono spesso chiusi in formati incompatibili, rendendo difficile per gli scienziati combinare risultati e individuare schemi rilevanti, come chi risponde meglio a un vaccino o perché alcune persone hanno più effetti collaterali. Questo articolo descrive un nuovo modo di organizzare e collegare esperimenti biomedici eterogenei in modo che i ricercatori possano porre domande più ricche e ottenere risposte più rapide e affidabili che, in ultima analisi, influenzano come preveniamo e curiamo le malattie.
Un linguaggio comune per gli esperimenti
Gruppi di ricerca e database diversi tendono a descrivere i loro studi a modo loro, anche quando svolgono lavori molto simili. Un database può concentrarsi su prove di vaccini, un altro sull'attività genica in singole cellule, e un terzo sugli esiti clinici, ognuno con etichette e strutture differenti. Il Study–Experiment–Assay Common Data Model, o SEA CDM, offre una «grammatica» condivisa e semplice per tutti questi sforzi. Suddivide qualsiasi progetto biomedico in tre passaggi collegati: lo studio generale che pone la domanda, gli esperimenti condotti su persone o animali, e le assay — come analisi del sangue o misurazioni dell'espressione genica — che generano i risultati. Attorno a questi passaggi, il modello standardizza anche elementi chiave come chi o cosa è stato studiato, quali campioni sono stati prelevati, quali trattamenti sono stati applicati e quali analisi sono state eseguite. 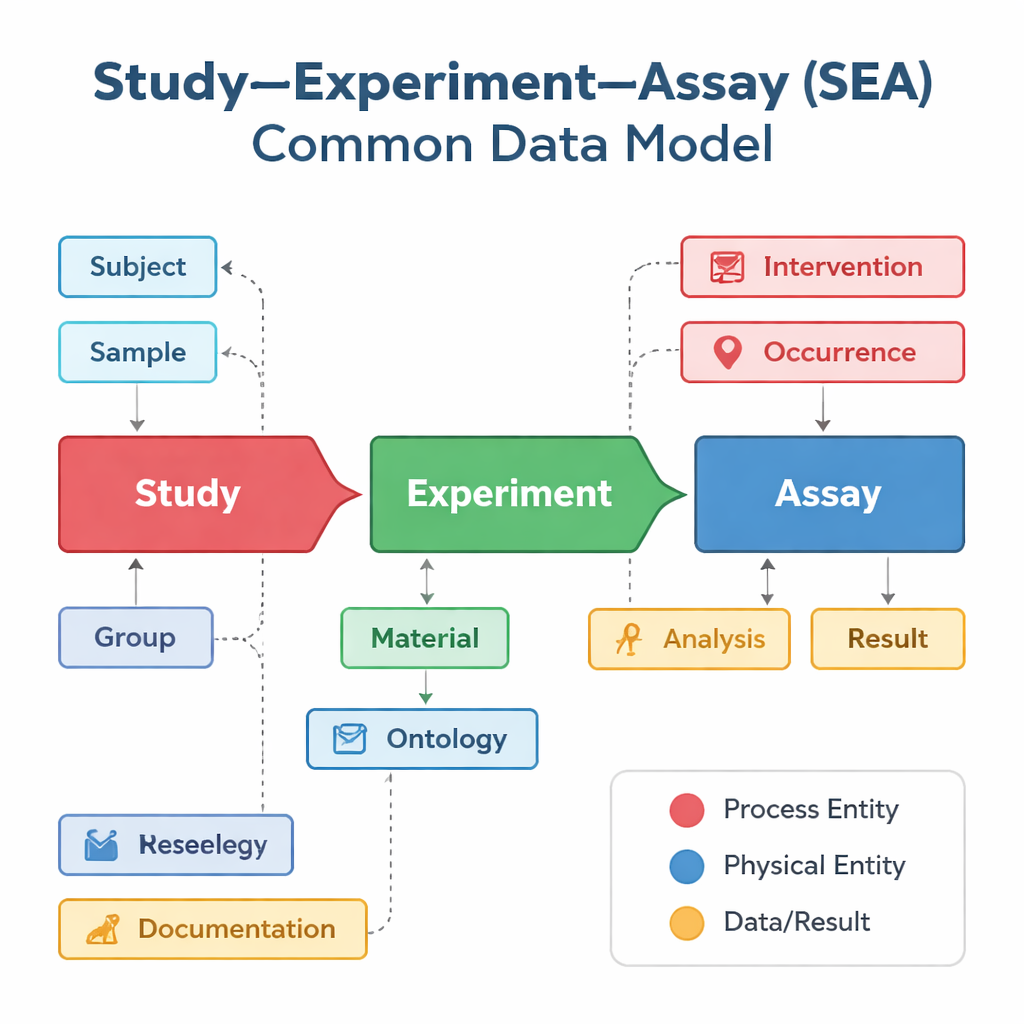
Ontologie: trasformare le etichette in conoscenza
Allineare semplicemente le intestazioni di colonna non è sufficiente; lo stesso concetto può essere chiamato in modi diversi in contesti differenti. SEA CDM si appoggia a vocabolari curati noti come ontologie per assicurare che «vaccino antinfluenzale», «vaccino trivalente inattivato per l'influenza» e un nome commerciale come «Fluzone» siano riconosciuti come idee correlate. Queste ontologie sono strutturate come alberi genealogici di termini medici e biologici. Poiché SEA CDM associa a ogni variabile un identificatore ufficiale preso da un'ontologia — per esempio per una malattia, un tipo cellulare o un vaccino — i computer possono seguire automaticamente questi alberi, trovare tutti i record rilevanti e persino inferire relazioni. Per esempio, una breve query può estrarre ogni studio che ha usato qualsiasi vaccino antinfluenzale trivalente da centinaia di prodotti nominati, abilitando ricerche semantiche potenti che vanno ben oltre la semplice corrispondenza di parole chiave. 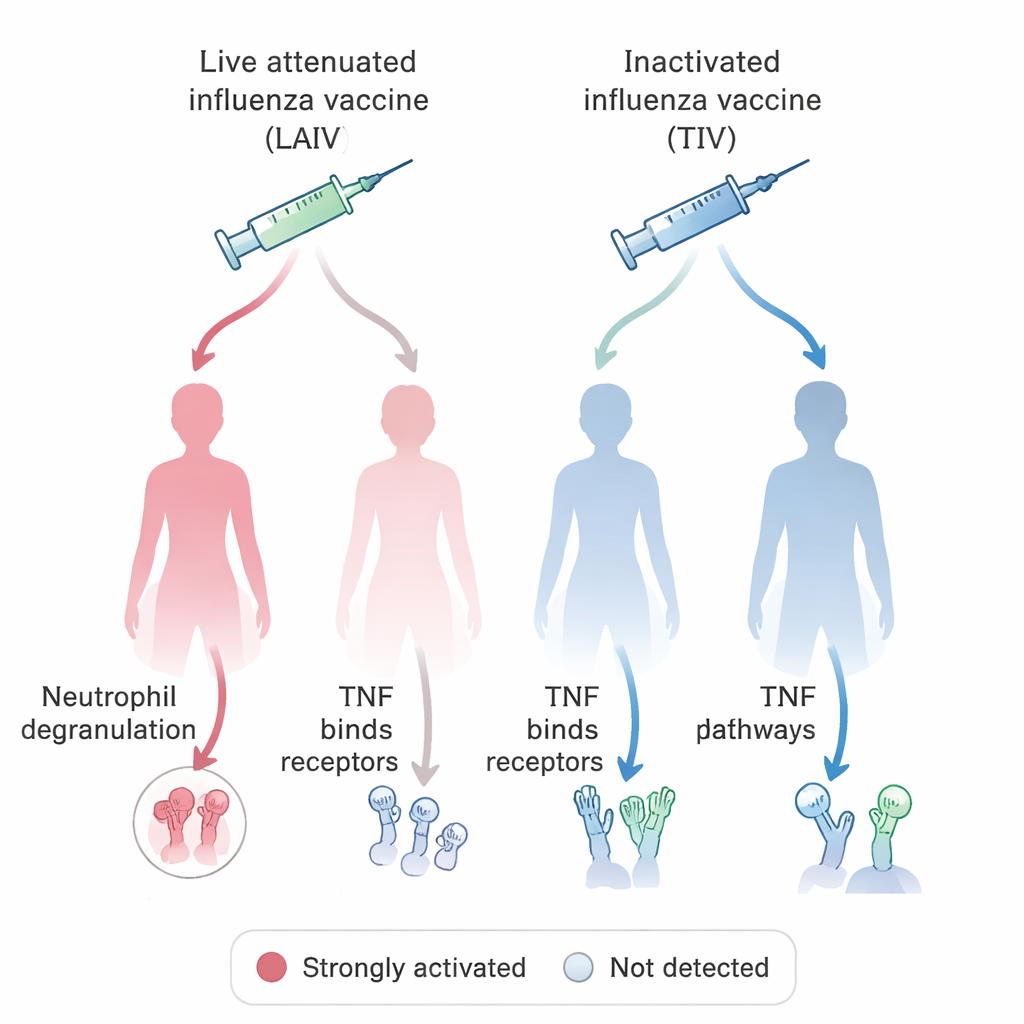
Da file sparsi a database connessi
Per testare il modello nel mondo reale, gli autori hanno costruito una famiglia di database e strumenti sotto il nome ombrello OSEAN. Hanno convertito tre grandi risorse pubbliche nella struttura SEA CDM: ImmPort, che ospita metadati di studi sulla risposta immunitaria; VIGET, che collega studi sui vaccini a dati sull'attività genica; e CELLxGENE, che si concentra su misurazioni a singola cellula. Utilizzando pipeline personalizzate, hanno tradotto dozzine di tabelle e formati di file originali in un insieme coerente di tabelle SEA CDM o nodi di grafo. Questo ha permesso loro di archiviare più di mille studi correlati al sistema immunitario, oltre due milioni di campioni e numerose descrizioni di vaccini, malattie e metodi di laboratorio in un unico framework coerente che può essere interrogato con lo stesso software.
Cosa può rivelare un dato unificato su vaccini e differenze legate al sesso
Con questo sistema unificato in funzione, il team ha posto una domanda biologica di rilevanza medica diretta: come stimolano il sistema immunitario diversi vaccini antinfluenzali nelle donne e negli uomini? Interrogando il database OSEAN basato su VIGET e applicando regole semplici su cosa conti come gene «stimolato», hanno identificato centinaia di geni la cui attività aumentava dopo la vaccinazione con vaccini antinfluenzali vivi attenuati (contenenti virus indebolito) o con vaccini inattivati, «uccisi». Hanno quindi confrontato le vie biologiche cui partecipano questi geni, separando i dati per sesso. Un modello interessante ha coinvolto i neutrofili, un tipo di globulo bianco che attacca i microbi rilasciando granuli tossici, e la segnalazione attraverso TNF, una molecola infiammatoria chiave. Nella maggior parte dei gruppi, la vaccinazione antinfluenzale era collegata a segnali di degranulazione dei neutrofili, ma questa firma mancava nelle donne che avevano ricevuto il vaccino vivo attenuato. Al contrario, la segnalazione legata a TNF era particolarmente evidente in queste donne ma non nei gruppi maschili paralleli. Questi risultati risuonano con studi su animali che suggeriscono che il comportamento dei neutrofili e le risposte ai vaccini possono differire sistematicamente tra maschi e femmine.
Costruire un ecosistema per scoperte future
Gli autori sostengono che il vero potere del SEA CDM risiede nel rendere i dati biomedici più FAIR — rintracciabili, accessibili, interoperabili e riutilizzabili. Fornendo agli esperimenti una struttura condivisa e ancorando ogni etichetta importante a un termine di ontologia ben definito, il loro sistema rende molto più semplice combinare dati provenienti da fonti diverse, tracciare come i campioni sono stati trattati e riprodurre le analisi. Lo studio sul virus dell'influenza mostra che anche query relativamente semplici, eseguite su un database armonizzato, possono scoprire schemi sottili e specifici per sesso nella risposta ai vaccini che potrebbero influenzare il dosaggio o la scelta del vaccino. Man mano che più risorse adottano questo modello comune e gli strumenti associati, i ricercatori saranno meglio attrezzati per collegare indizi attraverso malattie, tecnologie e popolazioni, trasformando dataset frammentati in un vero ecosistema integrativo di biodati.
Citazione: Huffman, A., Yeh, FY., Hur, J. et al. SEA CDM: Study-Experiment-Assay Common Data Model and Databases for Cross-Domain Data Integration and Analysis. Sci Data 13, 238 (2026). https://doi.org/10.1038/s41597-026-06558-z
Parole chiave: integrazione dei dati, ontologia biomedica, risposta ai vaccini, differenze legate al sesso, grafo della conoscenza