Come il cervello trova regole nascoste in un mondo rumoroso
Ogni giorno riconosciamo modelli con facilità: un semaforo rosso significa fermarsi, una strada affollata invita a rallentare, una certa postura suggerisce che un animale sta per balzare. Dietro queste abilità c’è la capacità del cervello di scoprire strutture nascoste, o “latenti”, nel mondo e di riutilizzarle in compiti diversi. Questo articolo pone una domanda apparentemente semplice: cosa rende un particolare schema di attività di popolazione neurale migliore di un altro per risolvere rapidamente e con precisione molti compiti correlati?
I meccanismi nascosti dietro i codici neurali Figure 1.
Gli autori studiano l’attività cerebrale a livello di popolazione, considerando il firing di molte neuroni come punti in uno spazio ad alta dimensione. Si concentrano su compiti che condividono un insieme sottostante di variabili latenti — per esempio la forma, la dimensione e la posizione di un oggetto, o la posizione e la velocità di un animale. Un neurone o un circuito di lettura a valle interpreta questi schemi con una regola lineare semplice, simile a tracciare un piano attraverso la nuvola di punti per separare la “categoria A” dalla “categoria B”. Anziché simulare ogni singolo neurone nel dettaglio, gli autori derivano una formula analitica che predice quanto bene tale lettura generalizzerà a nuovi esempi, data la geometria dell’attività neurale. Sorprendentemente, trovano che le prestazioni sono governate da sole quattro statistiche che riassumono quanto fortemente i neuroni riflettano le variabili latenti, quanto chiaramente le diverse variabili siano separate, come è organizzato il rumore e quante dimensioni effettive occupa l’attività.
Quattro ingredienti semplici per una buona generalizzazione
Il primo ingrediente è la correlazione complessiva tra singoli neuroni e variabili latenti: quando piccole variazioni nelle variabili nascoste causano spostamenti chiari nelle risposte neurali, le letture downstream hanno più segnale su cui lavorare. Il secondo e il terzo ingrediente descrivono la “fattorizzazione”: idealmente, diverse variabili latenti sono codificate lungo direzioni indipendenti e il rumore casuale deriva in direzioni ortogonali a questi assi di segnale. Questo rende più facile per un singolo confine lineare trasferirsi attraverso molti compiti che dipendono dalla stessa struttura nascosta. Il quarto ingrediente è la dimensionalità effettiva, che cattura quante direzioni nello spazio delle attività la popolazione utilizza realmente. Una dimensionalità maggiore tende a diluire il rumore su più direzioni, migliorando l’affidabilità, ma deve essere bilanciata rispetto a quanto chiaramente il segnale si allinea con le variabili rilevanti per il comportamento.
Validare la teoria in cervelli artificiali e biologici Figure 2.
Per verificare la loro teoria, gli autori la applicano prima a reti neurali artificiali. In percettroni multistrato addestrati su molti problemi di classificazione correlati, e in una rete profonda addestrata a tracciare parti del corpo del topo nei video, misurano le quattro quantità geometriche ad ogni livello. Gli errori previsti si allineano strettamente con le prestazioni effettive delle semplici letture addestrate su quelle rappresentazioni interne. Poi passano a dati cerebrali reali. Registrazioni da aree visive di macachi mostrano che, man mano che i segnali procedono dagli occhi verso la corteccia visiva superiore, la geometria evolve in modo da ridurre l’errore di generalizzazione: aumentano le correlazioni con le variabili latenti, la variabilità di disturbo viene spinta lontano dalle direzioni di segnale e certe forme di dimensionalità vengono rimodellate. In ratti che apprendono un compito di alternanza spaziale, sia il comportamento sia le prestazioni di lettura migliorano nel corso dei giorni di addestramento, mentre la geometria dell’attività ippocampale e prefrontale cambia in modi sistematici che rispecchiano le previsioni della teoria.
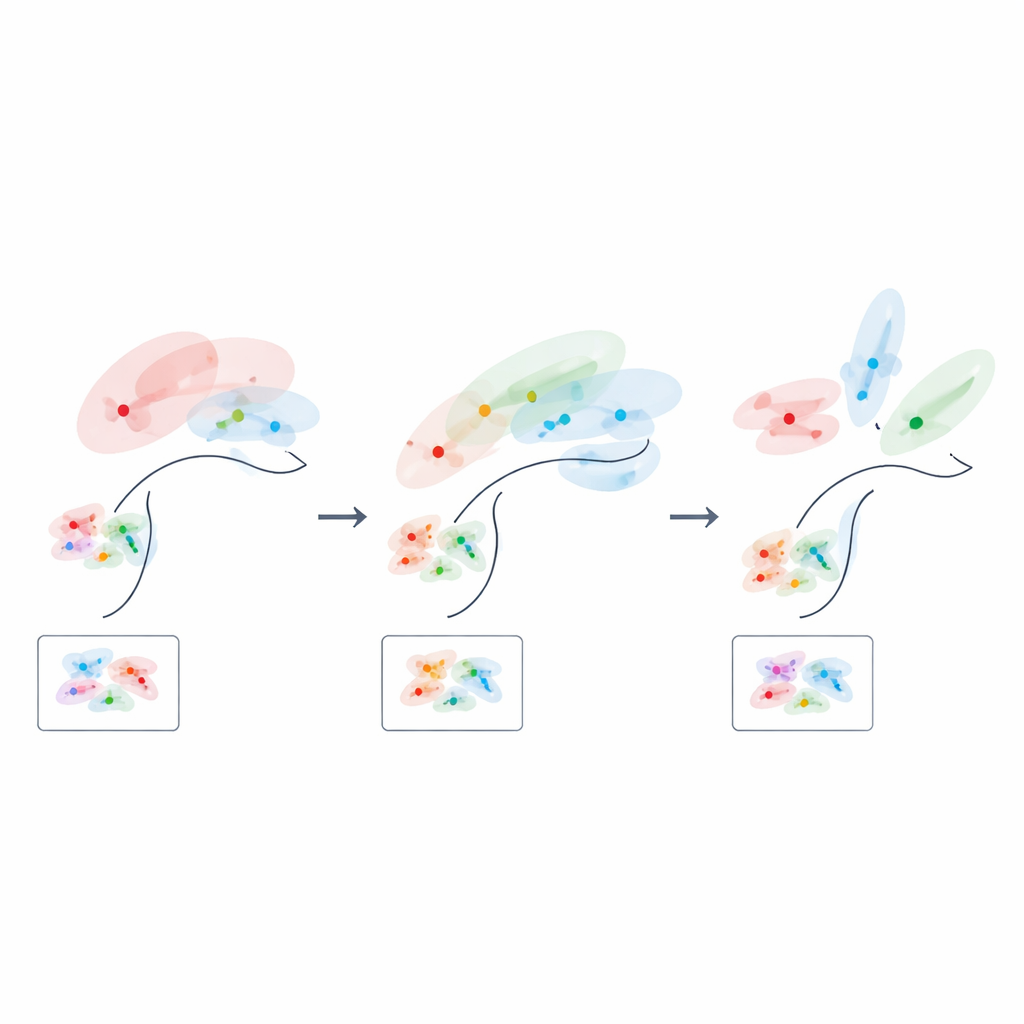
Come l’apprendimento riscrive lo spazio neurale
Poiché la loro formula collega la geometria direttamente alle prestazioni, gli autori possono chiedersi come dovrebbe apparire un codice neurale “ottimale” in diverse fasi dell’apprendimento. All’inizio, quando sono disponibili solo pochi esempi di addestramento, i codici migliori sono a bassa dimensionalità e fortemente allineati con le variabili latenti più informative, comprimendo di fatto le caratteristiche meno utili. Con l’accumularsi dell’esperienza, la soluzione ottimale cambia: la rappresentazione della struttura rilevante per il compito si espande in più dimensioni e la stretta correlazione tra singoli neuroni e variabili individuali si allenta. In altre parole, il cervello sembra partire da uno schizzo focalizzato e a bassa dimensionalità del compito e gradualmente riempire una mappa più ricca e distribuita man mano che impara.
Perché questo è importante per comprendere cervelli e macchine
Per un lettore non specialista, il messaggio chiave è che l’attività di popolazione cerebrale non è solo un groviglio di spike; ha una forma, e quella forma conta. Identificando quattro caratteristiche geometriche misurabili che controllano quanto bene letture semplici possono generalizzare attraverso compiti correlati, questo lavoro offre un linguaggio comune per confrontare reti neurali biologiche e artificiali. Suggerisce che, mentre animali e macchine imparano, riorganizzano la loro attività interna da codici compatti e altamente allineati verso codici a dimensionalità maggiore e meglio fattorizzati che continuano comunque a proteggere l’informazione rilevante per il compito dal rumore. Questa visione geometrica aiuta a spiegare come gli stessi circuiti cerebrali possano riutilizzare in maniera flessibile la struttura nascosta in molte situazioni, sostenendo la generalizzazione apparentemente senza sforzo che sta alla base dell’intelligenza quotidiana.
Citazione: Wakhloo, A.J., Slatton, W. & Chung, S. Neural population geometry and optimal coding of tasks with shared latent structure.
Nat Neurosci29, 682–692 (2026). https://doi.org/10.1038/s41593-025-02183-y
Parole chiave: geometria delle popolazioni neurali, codifica di variabili latenti, apprendimento multitask, rappresentazioni disentangled, generalizzazione nelle reti neurali