Clear Sky Science · it
Affidabilità dei LLM come assistenti medici per il pubblico generale: uno studio randomizzato preregistrato
Perché il tuo telefono potrebbe non essere il miglior primo medico
Sempre più persone si rivolgono a chatbot basati su IA quando non si sentono bene, sperando di ottenere risposte rapide sul se preoccuparsi, sul significato dei sintomi e sull’opportunità di recarsi in ospedale. Questo studio pone una domanda semplice ma urgente: se persone comuni usano potenti modelli linguistici come assistenti medici a casa, prendono davvero decisioni più corrette sulla propria salute — o la tecnologia può dare un falso senso di sicurezza?
Testare macchine intelligenti con casi in stile vita reale
Per scoprirlo, ricercatori nel Regno Unito hanno progettato dieci storie mediche realistiche, come un improvviso mal di testa severo o difficoltà respiratorie, basate su condizioni comuni che molti di noi potrebbero affrontare. Un team di medici esperti ha concordato il “passo successivo” migliore per ciascuna storia — da rimanere a casa e curarsi da sé fino a chiamare un’ambulanza — e ha elencato le condizioni chiave che una persona attenta dovrebbe considerare. Poi 1.298 adulti in tutto il Regno Unito sono stati assegnati casualmente a una delle quattro opzioni: usare uno di tre chatbot IA leader, oppure usare ciò su cui si sarebbero normalmente affidati a casa, come la ricerca sul web o l’esperienza personale.
Come si sono comportati persone e macchine — separatamente e insieme
Quando i modelli linguistici sono stati valutati da soli, fornendo loro le descrizioni complete dei casi e chiedendo direttamente una diagnosi e l’azione raccomandata, si sono comportati in modo impressionante. Tra i tre sistemi, hanno suggerito correttamente almeno una condizione medica rilevante in circa il 95% dei casi e hanno scelto il livello giusto di urgenza in più della metà dei casi — molto meglio del caso. Su carta, questi sistemi apparivano candidati solidi per guidare i pazienti preoccupati.
Quando il consiglio dell’IA incontra persone reali
Ma una volta che sono entrati in gioco gli utenti quotidiani, il quadro è cambiato. I partecipanti che hanno usato l’IA non sono risultati più accurati del gruppo di controllo nel scegliere cosa fare dopo, e in realtà sono stati peggiori nell’indicare le condizioni sottostanti rilevanti. Le persone nel gruppo non-IA erano circa 1,8 volte più propense a identificare una condizione corretta rispetto a chi usava i chatbot. La maggior parte dei partecipanti in tutti i gruppi ha sottostimato la gravità della situazione. In altre parole, l’accesso a un avanzato modello linguistico non ha aiutato le persone a capire meglio i propri sintomi, né le ha chiaramente spinte verso scelte più sicure.
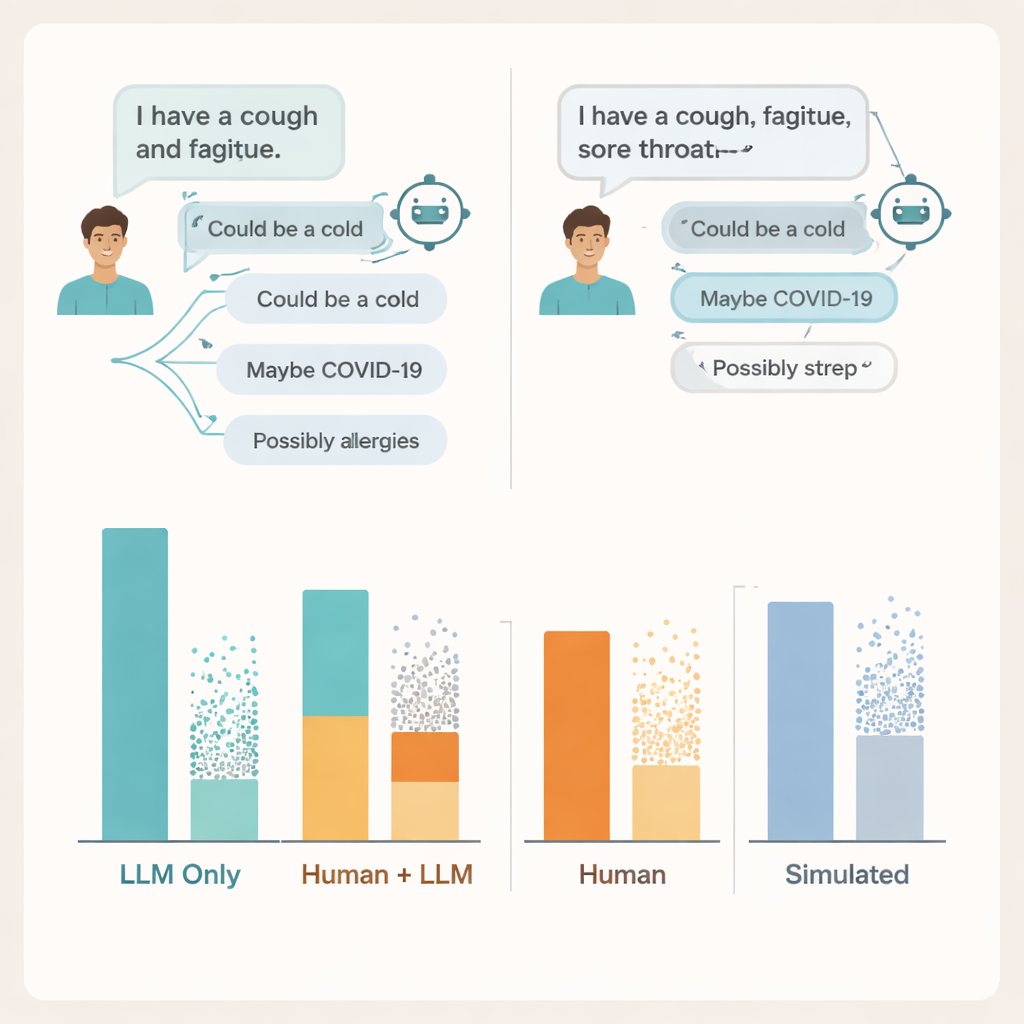
Dove si rompe la conversazione
Per capire perché, i ricercatori hanno analizzato le trascrizioni delle chat reali. Hanno trovato problemi su entrambi i lati della conversazione. Molti utenti non hanno fornito dettagli sufficienti sui loro sintomi perché l’IA potesse dare consigli solidi — proprio come i pazienti talvolta omettono informazioni chiave quando parlano con un medico. I modelli stessi spesso menzionavano almeno una condizione rilevante, ma aggiungevano anche diverse possibilità errate o fuorvianti, e gli utenti faticavano a capire quali suggerimenti contassero davvero. In alcuni casi, descrizioni di sintomi quasi identiche hanno portato a consigli molto diversi dallo stesso modello, rendendo difficile per le persone capire quando fidarsi di ciò che vedevano sullo schermo.
Perché i test standard non colgono i rischi reali
Il team ha anche confrontato questi risultati con due modi popolari di giudicare le IA mediche: domande d’esame a scelta multipla e chat completamente simulate con “pazienti” eseguite tra due modelli. In entrambi i casi, i sistemi sono sembrati nuovamente performanti, raggiungendo o superando i punteggi di superamento tipici nelle domande in stile esame e andando meglio con pazienti simulati che con pazienti reali. Eppure gli alti voti d’esame e le conversazioni simulate levigate non si sono allineati a come le persone reali se la cavavano usando gli stessi strumenti. I benchmark che testano la conoscenza in isolamento, sostengono gli autori, non colgono la natura disordinata e fragile delle interazioni umane-IA reali.
Cosa significa per i pazienti e i sistemi sanitari
Per ora, conclude lo studio, gli attuali modelli linguistici di uso generale non sono pronti a fungere da consulenti di prima linea non supervisionati per il pubblico. Contengono chiaramente una grande quantità di conoscenze mediche, ma tali conoscenze non si traducono automaticamente in scelte più sicure quando persone ansiose digitano domande parziali o confuse a casa. Rendere l’IA veramente utile in contesti ad alto rischio come la sanità richiederà più di migliori punteggi d’esame — serviranno progettazione attenta, test con utenti reali e diversi, e controlli più rigidi su come le informazioni vengono raccolte, spiegate e affidate nel continuo scambio della conversazione.
Citazione: Bean, A.M., Payne, R.E., Parsons, G. et al. Reliability of LLMs as medical assistants for the general public: a randomized preregistered study. Nat Med 32, 609–615 (2026). https://doi.org/10.1038/s41591-025-04074-y
Parole chiave: chatbot medici, autodiagnosi, IA per la salute, decisioni del paziente, modelli linguistici di grandi dimensioni