Clear Sky Science · it
Espansioni di ripetizioni GGC in nuovi frame di lettura vengono tradotte in proteine poliglicine tossiche nella miopatia oculofaringodistale
Messaggi nascosti nel nostro DNA
La maggior parte di noi ha imparato a scuola che solo una piccola porzione del nostro DNA codifica per proteine, mentre il resto veniva un tempo etichettato come “spazzatura”. Questo studio capovolge quell’idea. Mostra che brevi tratti trascurati di DNA ripetitivo possono inaspettatamente dare origine a nuove proteine che danneggiano muscoli e cervello, contribuendo a spiegare un gruppo di malattie neurologiche rare ma devastanti—and indicando una possibile via terapeutica.
DNA ripetitivo e misteriose malattie muscolari
Il nostro genoma è pieno di piccole sequenze ripetute, come sillabe di tre lettere copiate molte volte. Quando alcune di queste ripetizioni diventano troppo lunghe, possono causare oltre 60 malattie umane note. Nella miopatia oculofaringodistale (OPDM) e in un disturbo correlato con alterazioni cerebrali chiamato OPML, i pazienti sviluppano palpebre cadenti, difficoltà a deglutire, debolezza a mani e piedi e talvolta problemi nervosi e cerebrali più ampi. Al microscopio, i medici osservano aggregati proteici distintivi all’interno delle cellule muscolari e nervose, ma fino a ora non era chiaro come ripetizioni situate in regioni del DNA definite “non codificanti” potessero produrre proteine tossiche.
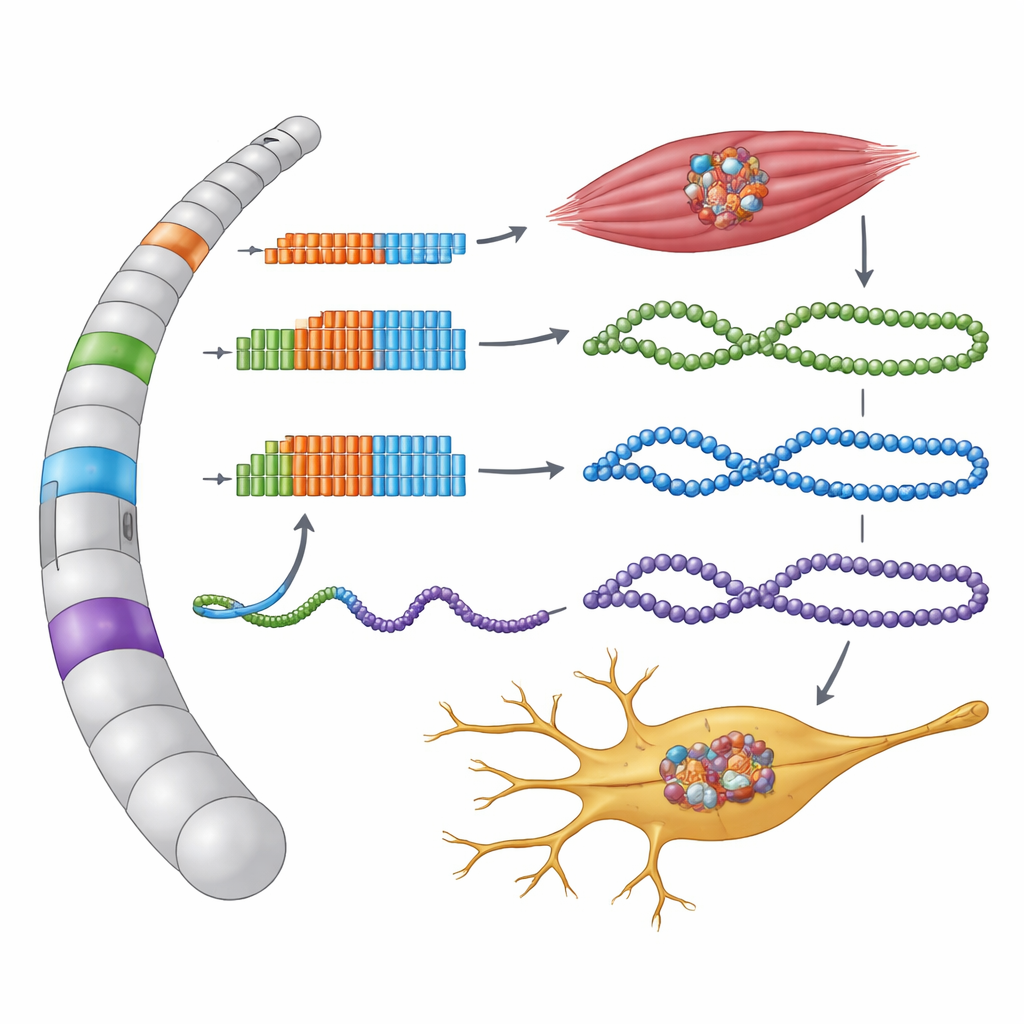
Regioni non codificanti che segretamente producono proteine
I ricercatori si sono concentrati su regioni di DNA dove la sequenza di tre lettere GGC è ripetuta molte volte all’interno di diversi geni associati a OPDM e OPML. Queste ripetizioni si trovano in aree annotate come non codificanti—code non tradotte dei geni o lunghi RNA ritenuti incapaci di produrre proteine. Riproducendo queste sequenze umane nelle cellule e tracciando come vengono lette, il gruppo ha scoperto che ogni tratto di GGC si trova in realtà all’interno di una piccola, precedentemente non riconosciuta unità codificante chiamata piccolo open reading frame. Quando le cellule leggono queste istruzioni nascoste, ogni ripetizione GGC viene tradotta nell’amminoacido glicina, formando insolite code lunghe di “poliglicina” su nuovi microproteine.
Nuove proteine tossiche che si aggregano e uccidono le cellule
Utilizzando anticorpi creati ad hoc, gli scienziati hanno dimostrato che queste microproteine portatrici di poliglicina sono presenti nei campioni muscolari dei pazienti e si concentrano esattamente dove si trovano i caratteristici aggregati proteici p62-positivi. Hanno quindi indotto cellule muscolari umane, mosche e topi a produrre gli stessi tipi di proteine poliglicine. In tutti e tre i sistemi, le proteine si condensavano in inclusioni tonde e dense nel citoplasma e nel nucleo, somigliando a quanto osservato nei tessuti dei pazienti. Le cellule che producevano queste proteine avevano maggiore probabilità di morire, e nei topi i muscoli interessati mostravano fibre ridotte, nuclei internalizzati e segni di infiammazione. Quando le proteine si accumulavano nel cervello e nel cuore, gli animali sviluppavano disturbi del movimento, neurodegenerazione, cardiomiopatia e una vita più breve, rispecchiando molti sintomi riportati nei pazienti.

Un nucleo tossico comune, molte sfumature locali
Sebbene queste microproteine condividano lo stesso elemento centrale—una lunga catena di residui di glicina—non sono identiche. Ciascuna deriva da un diverso piccolo frame di lettura in un gene diverso e quindi possiede segmenti amminoacidici unici che fiancheggiano il tratto di poliglicina. Il team ha riscontrato che questi segmenti circostanti influenzano fortemente il comportamento delle proteine: dove si accumulano nella cellula, quanto facilmente formano aggregati, con quali partner cellulari interagiscono e quanto sono tossiche per cellule muscolari e nervose. Alcune varianti risultavano particolarmente dannose, scatenando rapidamente la formazione di inclusioni e la morte cellulare, mentre altre erano relativamente più miti. Questo suggerisce un meccanismo tossico di base comune, modulato dal contesto sequenziale locale.
Un primo passo verso una strategia terapeutica condivisa
Elemento incoraggiante, i ricercatori hanno anche identificato una piccola molecola, la porfirina cationica TMPyP4, che può ridurre sia l’accumulo sia la tossicità di queste proteine poliglicine in cellule e in un modello di mosca della frutta. TMPyP4 sembra agire principalmente interferendo con la traduzione di regioni ricche di GC, riducendo la produzione delle proteine dannose senza spegnere in modo generale la sintesi proteica. Pur essendo ancora lontana dall’essere un farmaco pronto all’uso, offre una prova di principio che un singolo approccio terapeutico potrebbe un giorno aiutare pazienti con varie condizioni correlate guidate da espansioni di ripetizioni simili.
Cosa significa per la nostra comprensione delle malattie
Per un non specialista, il messaggio centrale è sorprendente: tratti di DNA a lungo considerati non codificanti possono nascondere piccole ricette proteiche che diventano pericolose quando certe ripetizioni si espandono. Nella OPDM, nell’OPML, nella malattia da inclusioni intranucleari neuronali e in disturbi correlati, quelle ripetizioni GGC espanse vengono tradotte in appiccicose proteine poliglicine che si aggregano all’interno delle cellule e compromettono progressivamente muscoli, nervi e cervello. Scoprendo questo meccanismo condiviso e un primo composto candidato in grado di attenuarlo, lo studio amplia la nostra visione di cosa debba essere considerato un gene e apre nuove strade per curare una famiglia in crescita di malattie neurologiche guidate dalle ripetizioni.
Citazione: Boivin, M., Yu, J., Eura, N. et al. GGC repeat expansions within new open reading frames are translated into toxic polyglycine proteins in oculopharyngodistal myopathy. Nat Genet 58, 517–529 (2026). https://doi.org/10.1038/s41588-026-02507-z
Parole chiave: miopatia oculofaringodistale, espansione di ripetizioni microsatellite, proteine poliglicine, traduzione del DNA non codificante, malattia neurodegenerativa muscolare