Clear Sky Science · it
Anticipazione e scoperta dei metaboliti dei mammiferi guidata da modelli linguistici chimici
Chimica nascosta all'interno dei nostri corpi
Ogni goccia di sangue o di urina contiene migliaia di piccole molecole che riflettono ciò che mangiamo, come viviamo e se stiamo per ammalarci. Eppure per la maggior parte di queste molecole gli scienziati non conoscono il nome né la funzione. Questo articolo presenta DeepMet, un sistema di intelligenza artificiale che legge il «linguaggio» di queste molecole e prevede quali siano quelle mancanti nelle mappe attuali della chimica umana e animale. Guidando gli esperimenti verso i candidati più promettenti, DeepMet aiuta i ricercatori a scoprire questa materia chimica oscura e a comprendere meglio il funzionamento del nostro organismo.
Perché così tante molecole restano sconosciute
Gli strumenti moderni possono pesare e parzialmente caratterizzare migliaia di molecole in un campione tissutale contemporaneamente. Ma trasformare queste «impronte» in strutture esatte è difficile. I database esistenti elencano molti metaboliti noti, tuttavia la maggior parte dei segnali osservati nei campioni reali non corrisponde a nulla in quei cataloghi. Questo divario suggerisce che le mappe attuali del metabolismo sono incomplete e che molte molecole naturali nei mammiferi non sono mai state descritte. Gli autori si sono proposti di costruire uno strumento in grado di apprendere dai metaboliti noti e poi immaginare quelli mancanti più plausibili, in modo analogo a come i modelli linguistici prevedono le parole probabili in una frase.
Insegnare a una macchina la grammatica del metabolismo
Il team ha addestrato una rete neurale chiamata DeepMet su circa 2.000 metaboliti umani ben caratterizzati, codificando ciascuno come una stringa breve che descrive la sua struttura. Dopo un addestramento iniziale su molecole con caratteristiche simili ai farmaci per apprendere regole chimiche generali, DeepMet è stato perfezionato su questo insieme di metaboliti. Quando è stato invitato a generare nuove strutture, il modello ha prodotto molecole che occupavano le stesse regioni dello spazio chimico dei metaboliti reali e ha persino riprodotto molti tipi noti di reazioni enzimatiche, pur non essendo stato istruito esplicitamente su tali regole. In altre parole, DeepMet sembra aver internalizzato la grammatica non scritta che collega mattoni fondamentali come zuccheri e amminoacidi in piccole molecole realistiche dal punto di vista biologico.
Prevedere quali nuove molecole probabilmente esistono
I ricercatori hanno quindi campionato un miliardo di molecole candidate da DeepMet e hanno contato quante volte appariva ciascuna struttura unica. Le strutture ripetute con frequenza tendevano a somigliare maggiormente ai metaboliti noti, a condividere nucleo chimico con essi e a corrispondere a trasformazioni enzimatiche plausibili. Per verificare se questi candidati ad alta frequenza corrispondessero a molecole reali, il team ha confrontato le previsioni di DeepMet con i metaboliti aggiunti all'Human Metabolome Database dopo la chiusura dei dati di addestramento del modello. DeepMet aveva già generato la maggior parte di queste scoperte successive e ne aveva classificate molte tra le candidate più probabili. Dalle migliaia di strutture assenti nei database ma classificate ai vertici, gli autori ne hanno acquistate o sintetizzate 80 e hanno controllato campioni umani reali mediante spettrometria di massa. Hanno confermato la presenza di diversi metaboliti precedentemente non riconosciuti, alcuni dei quali erano stati trascurati nonostante compaiano nella letteratura esistente.
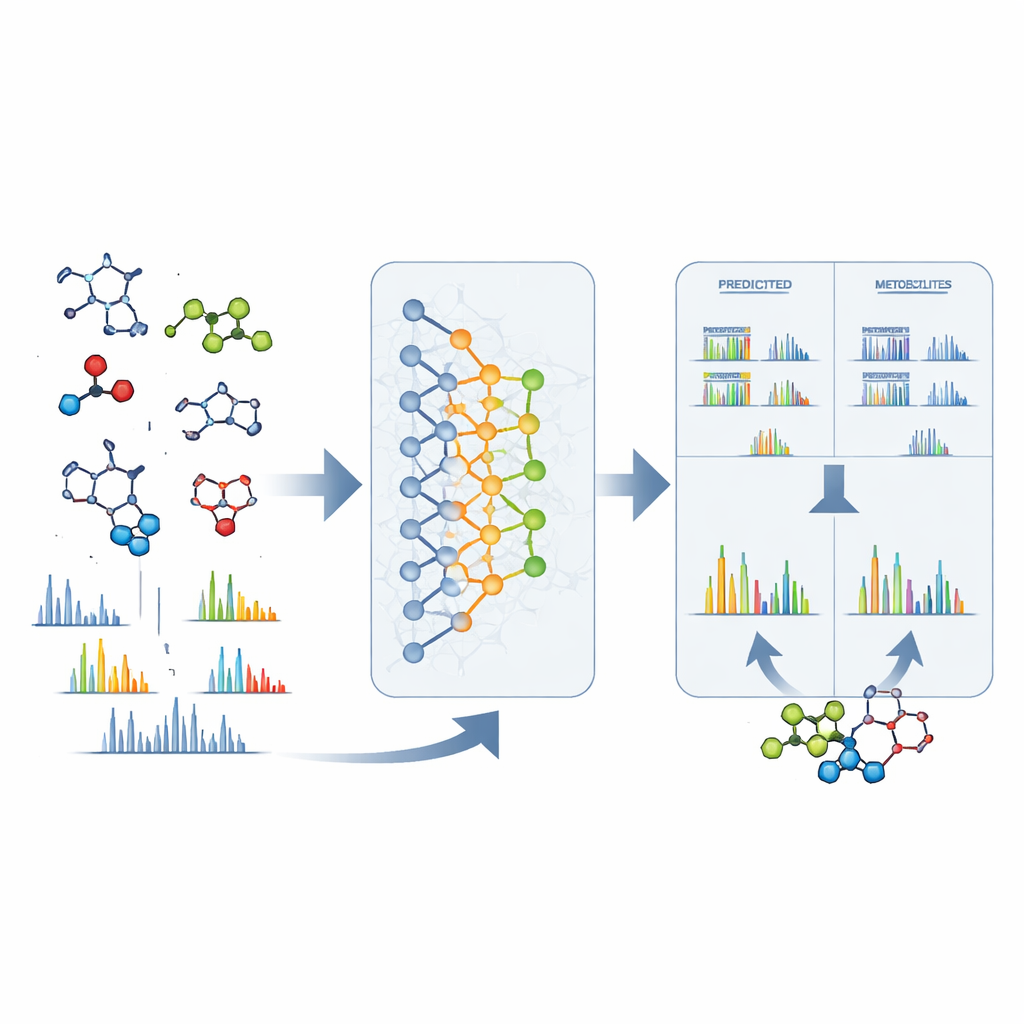
Da segnali grezzi a strutture concrete
DeepMet è utile anche quando in uno spettrometro di massa si osserva un picco sconosciuto. Avendo a disposizione solo la massa esatta di una molecola misteriosa, il modello può elencare molte strutture che peserebbero uguale e ordinarle in base a quanto appaiono simili a metaboliti. In quasi un terzo dei casi di test, la struttura corretta è risultata al primo posto; in molti altri casi è comparsa tra pochi candidati in cima alla lista ed era solitamente molto simile nella forma alla preferita del modello. Per restringere ulteriormente le possibilità, gli autori hanno combinato DeepMet con un software separato che predice come ciascun candidato si frammenterebbe in uno spettrometro di massa. Confrontare questi schemi previsti con spettri sperimentali reali ha raddoppiato approssimativamente l'accuratezza dell'identificazione. Cercare in grandi database pubblici con questo approccio combinato ha fornito strutture plausibili per molti segnali precedentemente anonimi e ha indicato metaboliti che differiscono tra malattie, diete e stati del microbioma.
Illuminare la materia oscura chimica della vita
Combinando l'intuizione chimica appresa dai dati con potenti corrispondenze di pattern contro spettri di massa, DeepMet offre una roadmap per scoprire nuovi metaboliti in modo mirato e pratico. Non può ancora rivelare ogni molecola sconosciuta: alcune strutture sono troppo distanti da quelle che ha visto e certi isomeri restano indistinguibili senza metodi specializzati. Ma lo studio mostra che strumenti in stile modelli linguistici possono non solo inventare molecole realistiche, ma anche anticipare composti reali che i biologi confermeranno successivamente in animali e umani. Per un lettore non tecnico, la conclusione è che l'IA può ora aiutare i chimici a scoprire sistematicamente la chimica nascosta nei nostri corpi, rivelando potenzialmente nuovi biomarcatori, tracciando i legami dieta–microbioma–ospite e trasformando gradualmente l'odierna materia oscura metabolica nella biologia ben mappata di domani.
Citazione: Qiang, H., Wang, F., Lu, W. et al. Language model-guided anticipation and discovery of mammalian metabolites. Nature 651, 211–220 (2026). https://doi.org/10.1038/s41586-025-09969-x
Parole chiave: metabolomica, modelli linguistici chimici, DeepMet, spettrometria di massa, materia oscura metabolica