Clear Sky Science · it
Svelare i picchi chiave per l’autenticazione dell’olio d’oliva mediante spettroscopia Raman e chemometria
Perché la storia delle frodi sull’olio d’oliva è importante
Quando paghi di più una bottiglia di olio d’oliva, ti aspetti il prodotto vero, non una miscela diluita con oli di semi più economici. Eppure, dato il valore dell’olio d’oliva e la complessità del commercio globale, frodi e etichettature errate sono problemi comuni. Questo studio propone un metodo rapido e non distruttivo per individuare questi inganni, illuminando gli oli con un laser e lasciando che programmi informatici intelligenti leggano le impronte chimiche nascoste. L’approccio mira a proteggere i consumatori, i produttori onesti e i regolatori, rendendo più semplice verificare se il contenuto della bottiglia corrisponde a quanto dichiarato in etichetta.
Illuminare per leggere le impronte dell’olio
I ricercatori hanno utilizzato una tecnica chiamata spettroscopia Raman, che consiste nel puntare un fascio di luce focalizzato su un campione e misurare come la luce si disperde. Diverse molecole vibrano in modi distinti, lasciando un pattern di picchi nello spettro risultante, un po’ come un codice a barre. L’olio d’oliva e adulteranti comuni come olio di girasole, colza e mais hanno mix diversi di acidi grassi e pigmenti naturali, perciò i loro spettri non sono identici. Studiando questi pattern su oli puri e miscele preparate con cura, il team è stato in grado di identificare un piccolo insieme di “picchi chiave” la cui forma e intensità cambiavano in modo affidabile all’aumentare o al diminuire della percentuale di olio d’oliva in una miscela.
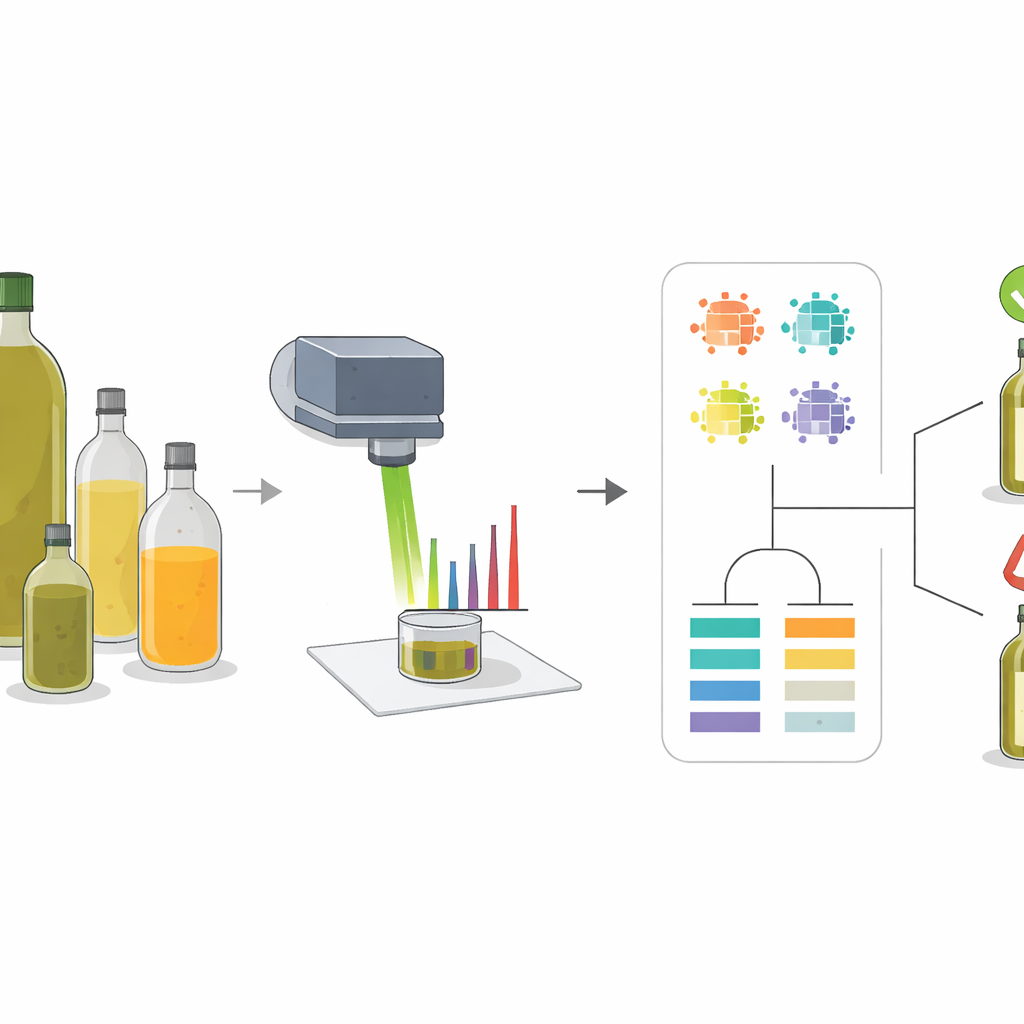
Trovare i segnali più rivelatori
Invece di basarsi su una singola misurazione, il gruppo ha estratto diversi descrittori da ogni picco importante: quanto era alto (intensità), quanta area occupava, quanto era largo a metà altezza e come la sua area si confrontava con quella di altri picchi. Hanno quindi utilizzato clustering e mappe di correlazione per osservare come questi descrittori raggruppassero i diversi oli e come si spostassero con l’aumentare del contenuto di olio d’oliva. I picchi collegati ai composti della colorazione come il beta-carotene e a particolari tipi di grassi insaturi si sono dimostrati particolarmente informativi. Per esempio, alcuni picchi si rafforzavano all’aumentare della quota di olio d’oliva, mentre altri si attenuavano perché legati all’acido linoleico, più abbondante nell’olio di girasole. Questa visione multi-caratteristica ha catturato differenze sottili che sarebbero sfuggite se si fosse utilizzato solo un valore di intensità.
Lasciare che gli algoritmi distinguano l’onesto dall’adulterato
Per trasformare questi fingerprint spettrali in decisioni pratiche, gli autori hanno addestrato diversi modelli di apprendimento automatico. Innanzitutto hanno chiesto ai modelli di classificare dieci tipi di olio, inclusi quattro oli puri e sei miscele binarie e ternarie. Metodi basati sugli alberi—random forest e gradient-boosted trees—hanno ottenuto i migliori risultati, assegnando correttamente quasi tutti i campioni alla categoria giusta quando veniva fornito l’insieme completo delle caratteristiche dei picchi. Successivamente, lo stesso approccio è stato impiegato per predizioni numeriche: stimare la percentuale effettiva di olio d’oliva in miscele di due e tre oli. Anche qui, gli approcci ad albero hanno superato i metodi più tradizionali, seguendo con precisione il contenuto di olio d’oliva anche quando i segnali di oli diversi si sovrapponevano fortemente negli spettri.
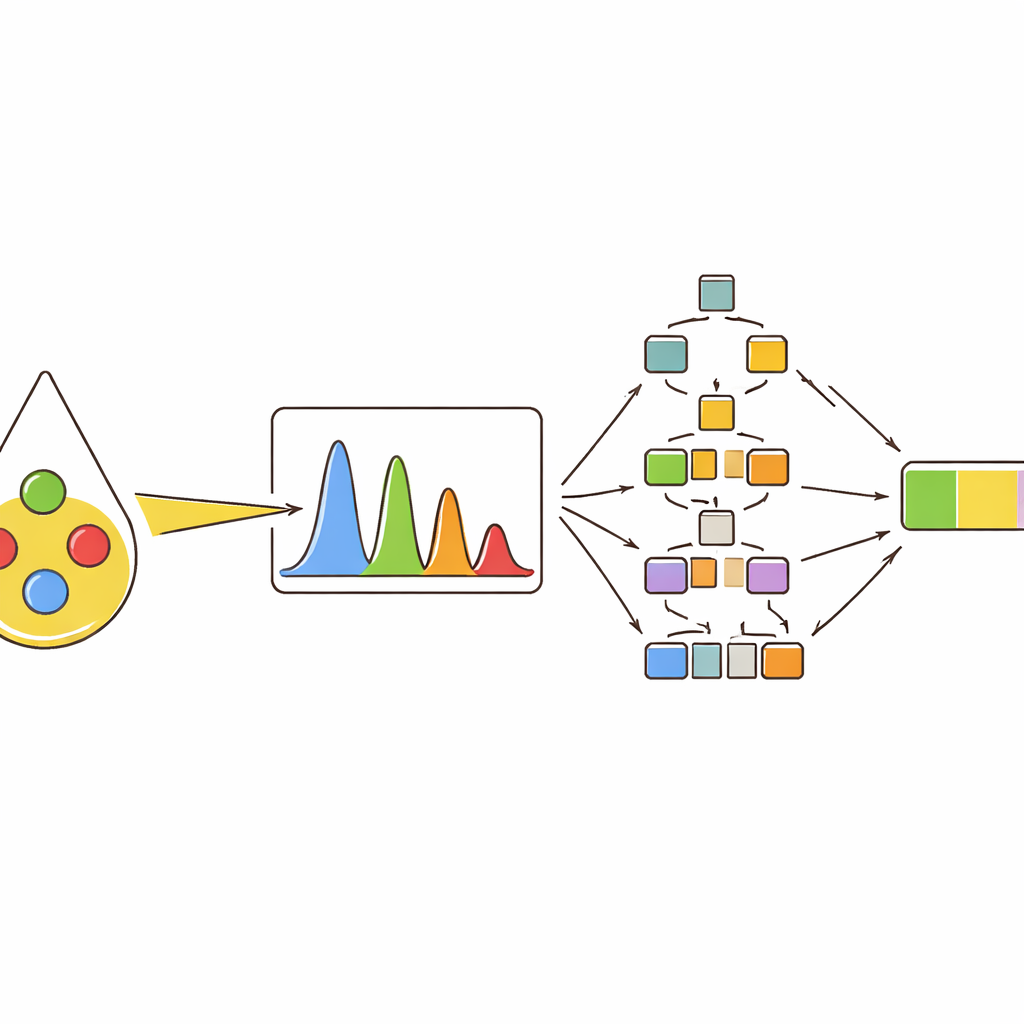
Aprire la scatola nera dei modelli intelligenti
Molti strumenti di machine learning potenti sono difficili da interpretare; possono dare buoni risultati ma offrire scarsa comprensione del perché abbiano preso una decisione. Per affrontare questo problema, lo studio ha utilizzato un metodo di spiegazione che assegna a ciascuna caratteristica di input un contributo alla previsione finale. Questo ha rivelato che pochi picchi specifici dominavano i giudizi dei modelli, spingendo coerentemente la stima del contenuto di olio d’oliva verso l’alto o verso il basso a seconda dei loro valori. Gli stessi picchi sono risultati tra i più importanti in diversi tipi di miscele e nei test su oli commerciali da supermercato, che contenevano solo una piccola quota di olio d’oliva. Per questi campioni reali, i migliori modelli hanno stimato il contenuto di olio d’oliva molto vicino al valore vero, supportando sia l’accuratezza sia la trasparenza dell’approccio.
Cosa significa per la tua bottiglia a casa
In termini pratici, il lavoro dimostra che una rapida scansione a luce, interpretata da modelli informatici ben progettati e spiegabili, può dire se un “olio d’oliva” è puro, fortemente diluito o da qualche parte nel mezzo. Focalizzandosi su una manciata di caratteristiche spettrali robuste e combinandole in algoritmi avanzati ma interpretabili, i ricercatori hanno costruito uno strumento che potrebbe essere integrato nei controlli di qualità di routine, potenzialmente anche in dispositivi portatili. Pur richiedendo test più ampi su regioni, varietà e tipi di frode diversi, questo quadro indica un futuro in cui verificare l’onestà di alimenti di alto valore come l’olio d’oliva diventa più rapido, semplice e affidabile per tutti.
Citazione: Chen, Y., Shao, R., Zeng, S. et al. Unveiling key peak features for olive oil authentication utilizing Raman spectroscopy and chemometrics. npj Sci Food 10, 88 (2026). https://doi.org/10.1038/s41538-026-00738-2
Parole chiave: autenticazione olio d'oliva, rilevamento frodi alimentari, spettroscopia Raman, apprendimento automatico, qualità degli oli alimentari