Clear Sky Science · it
Predizione assistita da text mining e machine learning e convalida sperimentale delle lunghezze d’onda di emissione
Trasformare il testo scientifico in luce
Ogni anno gli scienziati pubblicano decine di migliaia di articoli su materiali che emettono luce — sostanze impiegate in schermi per telefoni, scanner medici e rivelatori di radiazione. Nelle pagine di questi lavori sono sepolte misure precise dei colori che i vari materiali emettono, ma le informazioni sono disperse, scritte in modo non uniforme e difficili da usare per i computer. Questo studio mostra come leggere automaticamente quella letteratura, trasformarla in un ampio e affidabile insieme di dati e quindi usare il machine learning per prevedere il colore della luce che nuovi materiali emetteranno — aiutando i ricercatori a progettare fosfori migliori molto più rapidamente.
Perché i materiali luminescenti sono importanti
I fosfori sono materiali che assorbono energia e la riemettono come luce visibile. Sono al centro di tecnologie come display ultra‑high‑definition, LED bianchi, diagnostica medica e rivelazione di radiazioni. Gli ingegneri cercano fosfori che brillino con colori molto specifici, rimangano luminosi a temperature elevate e sprechino il meno possibile energia. Negli ultimi due decenni la ricerca su questi materiali è esplosa, riempiendo la letteratura scientifica di resoconti dettagliati di ricette chimiche e lunghezze d’onda di emissione. Tuttavia questi dati sono per lo più chiusi in testo non strutturato — frasi in paragrafi, didascalie e sezioni sperimentali scritte per esseri umani, non per i computer. 
Insegnare ai computer a leggere gli articoli sui materiali
Gli autori hanno costruito una pipeline di text mining specializzata per la letteratura sui fosfori. Anziché usare strumenti linguistici generici, hanno creato regole che comprendono come i chimici scrivono realmente le formule, in particolare per i materiali “drogati” in cui una piccola quantità di un elemento è aggiunta a un host. Il loro sistema riesce a riconoscere correttamente nomi complessi come una rete cristallina ospite seguita da diversi ioni dopanti e le loro concentrazioni, e può collegare quei nomi ai numeri vicini che rappresentano le lunghezze d’onda di emissione. Affronta anche linguaggio insidioso, come frasi del tipo “emette a 630 nm” senza ripetere il nome del materiale, o paragrafi in cui sono menzionati insieme più materiali e più lunghezze d’onda. Classificando ogni frase in base a quante sostanze e proprietà contiene e poi scegliendo un algoritmo di corrispondenza adatto per quella situazione, la pipeline riduce notevolmente gli errori nell’associare quale numero appartiene a quale materiale.
Costruire una mappa pulita dalla composizione al colore
Applicando questa pipeline a 16.659 articoli di riviste, il team ha estratto circa 6.400 coppie “materiale–emissione” affidabili: la formula di un fosforo, la sua lunghezza d’onda di picco di emissione, l’unità e l’identificatore digitale dell’articolo. Test accurati hanno mostrato un’elevata accuratezza sia nel riconoscere formule complete di fosfori sia nel collegarle ai corretti valori di emissione. Con questo dataset strutturato a disposizione, i ricercatori si sono concentrati su una famiglia particolarmente importante: materiali drogati con ioni europio (Eu2+), che possono emettere su un’ampia porzione dello spettro visibile a seconda del cristallo ospite. Hanno calcolato descrittori fisicamente significativi per ogni host — come dettagli della struttura cristallina, lunghezze di legame e gap elettronico — e poi hanno usato metodi di selezione delle caratteristiche per ridurli alla manciata che conta di più per predire il colore.
Lasciare che il machine learning predica la luminescenza
Successivamente gli autori hanno addestrato e confrontato diversi modelli di machine learning per predire la lunghezza d’onda di emissione a partire da quei descrittori. Un algoritmo chiamato XGBoost ha ottenuto le migliori prestazioni, raggiungendo un coefficiente di determinazione (R²) di circa 0,91 su dati di test non visti — una forte evidenza che il modello cattura le relazioni chiave tra struttura e colore. Per verificare se l’approccio funziona nel mondo reale, hanno usato il modello per proporre nuovi promettenti fosfori solfuri e nitruri drogati con Eu2+, hanno sintetizzato quattro candidati in laboratorio e misurato la loro emissione. Le lunghezze d’onda osservate differivano dalle predizioni di soli circa 10 nanometri, il che significa che le “ipotesi” del modello erano molto vicine alla realtà sperimentale. 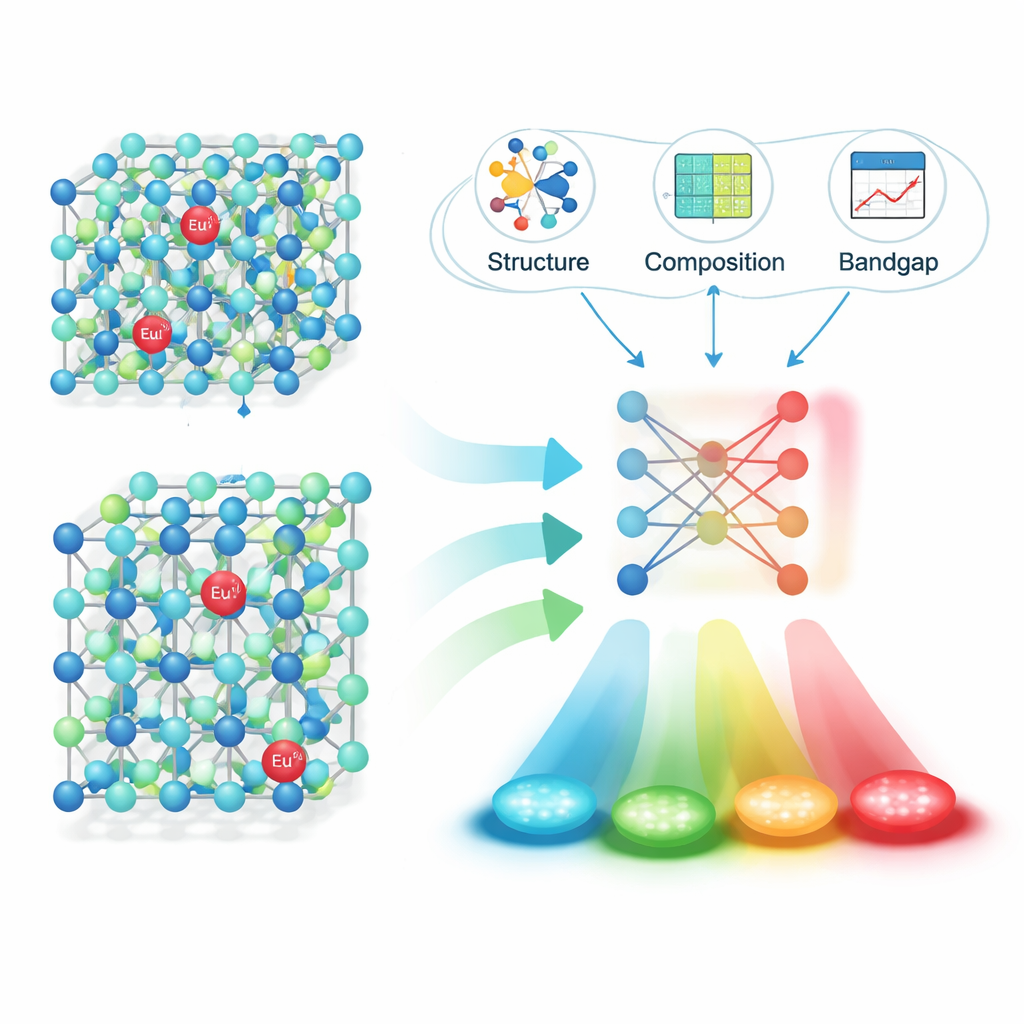
Dai paper ai progetti pratici
Per i non specialisti, il messaggio principale è che questo lavoro trasforma articoli sparsi e scritti per esseri umani in una mappa coerente e ricercabile che collega “di cosa è fatto un materiale” a “di che colore brilla”. Automatizzando i passaggi di lettura, organizzazione e apprendimento — e confermando poi le predizioni tramite esperimenti reali — lo studio delinea un circuito chiuso: testo → dati → modello → nuovo materiale. Questo quadro può essere esteso ad altre proprietà come luminosità e stabilità, e anche ad altre classi di materiali funzionali. Facendo così, indica un futuro in cui, anziché procedere per tentativi in laboratorio, gli scienziati potranno individuare rapidamente le ricette più promettenti, accelerando lo sviluppo di illuminazione, display e tecnologie di rilevamento migliori.
Citazione: Huang, L., Zhang, X., Li, S. et al. Text mining-assisted machine learning prediction and experimental validation of emission wavelengths. npj Comput Mater 12, 98 (2026). https://doi.org/10.1038/s41524-026-01967-5
Parole chiave: materiali luminescenti, text mining, machine learning, fosfori, predizione della lunghezza d’onda di emissione