Clear Sky Science · it
Colmare il divario di latenza con un framework di valutazione a flusso continuo nella percezione guidata da eventi
Perché una visione robotica più veloce conta
Immaginate un’auto a guida autonoma che individua un ostacolo improvviso o un robot che cerca di rispedire indietro una pallina da ping-pong in arrivo a tutta velocità. In queste situazioni di frazione di secondo, vedere rapidamente è importante quanto vedere nitidamente. Questo articolo esplora un nuovo modo di valutare quanto siano veloci e affidabili le avanzate “telecamere a eventi” quando tracciano oggetti in movimento, e mostra che i test di laboratorio abituali possono sovrastimare in modo significativo le prestazioni reali di questi sistemi.
Da istantanee a flussi
La maggior parte dei sistemi di visione artificiale odierni tratta il mondo come una presentazione a diapositive. Le telecamere tradizionali acquisiscono immagini a intervalli fissi e gli algoritmi elaborano un fotogramma alla volta. Anche quando gli ingegneri impiegano telecamere neuromorfiche, o basate su eventi, che rilevano variazioni di luminosità con risoluzione al microsecondo, spesso riconvertono quel ricco flusso continuo in fotogrammi grossolani. Questo approccio basato sui fotogrammi nasconde un problema cruciale: il ritardo. Ogni volta che il sistema aspetta il fotogramma successivo e poi lo elabora, preziosi millisecondi sfuggono. In compiti ad alta velocità come la guida autonoma o l’interazione uomo–robot, quel ritardo significa che il sistema reagisce sempre al passato recente anziché al presente.

Un nuovo modo di misurare la visione in tempo reale
Per colmare questo divario tra i risultati di laboratorio e le esigenze del mondo reale, gli autori introducono un framework chiamato STream-based lAtency-awaRe Evaluation, o STARE. Invece di forzare i dati a eventi in fotogrammi fissi, STARE alimenta un modello con gli eventi più recenti non appena ha terminato la sua ultima previsione. Questo “Campionamento Continuo” mantiene il modello occupato e spinge la sua frequenza di output fin dove l’hardware lo permette. Allo stesso tempo, STARE valuta l’accuratezza in modo nuovo: ogni posizione di ground truth di un oggetto in movimento è accoppiata con la previsione più recente disponibile in quell’istante. Se il modello è lento, la stessa previsione obsoleta viene riutilizzata su molti istanti temporali, e la sua accuratezza apparente cala. Questo incorpora direttamente il costo del ritardo nel punteggio finale.
Costruire un banco di prova ad alta velocità
Misurare tempistiche così fini richiede dati altrettanto dettagliati, che i dataset di telecamere a eventi esistenti non offrono. In genere registrano la posizione di un oggetto solo poche decine di volte al secondo. Perciò gli autori hanno creato ESOT500, un nuovo dataset in cui gli oggetti sono annotati 500 volte al secondo, sia con telecamere a eventi a bassa sia ad alta risoluzione e in scene varie come ventilatori in rotazione, uccelli in volo e veicoli in movimento. A questa densità, il ground truth segue movimenti rapidi e complessi abbastanza da evitare il “folding temporale” (temporal aliasing), cioè il problema per cui un campionamento lento fa sembrare un percorso tortuoso e veloce indebitamente semplice. ESOT500 funge quindi da stress test per qualsiasi metodo che dichiari di gestire dinamiche rapide e imprevedibili.
Cosa succede davvero quando la latenza conta
Armati di STARE ed ESOT500, gli autori hanno rivalutato una serie di tracker di oggetti allo stato dell’arte. Quando giudicati con i test tradizionali basati su fotogrammi, modelli più pesanti e complessi spesso appaiono i migliori. Con STARE, però, molti di questi sistemi lenti ma ad alta accuratezza perdono più della metà della loro accuratezza effettiva una volta che il ritardo è considerato. Modelli più leggeri e rapidi risalgono improvvisamente in classifica, perché forniscono previsioni più frequenti e aggiornate. Il team ha confermato questo risultato in un esperimento robotico di ping-pong: un robot ha usato una telecamera a eventi e un tracker per colpire palle in arrivo. Una percezione moderatamente più veloce ha quasi raddoppiato il tasso di colpi riusciti, mentre un modello più lento ma forte in modalità offline ha avuto scarse prestazioni. In altre parole, in tempo reale la velocità e la freschezza dell’informazione possono valere più della pura precisione.
Uso più intelligente dei flussi continui
Oltre alla valutazione, gli autori esplorano come progettare sistemi migliori per la visione continua. Una strategia, “Tracciamento Asincrono”, affianca un modello base lento ma accurato con un compagno più piccolo e agile che aggiorna continuamente la posizione dell’oggetto tra le passate complete del modello base. Questa configurazione doppia riusa caratteristiche condivise e sfrutta il flusso costante di eventi, aumentando la frequenza di output di quasi l’80% e migliorando l’accuratezza consapevole della latenza di circa il 60%. Una seconda strategia, “Campionamento Consapevole del Contesto”, monitora quanti eventi si verificano intorno all’oggetto tracciato. Quando la scena è calma e i cambiamenti sono pochi, il tracker riutilizza temporaneamente la sua ultima buona stima invece di ricalcolare, riducendo lavoro sprecato. Si riattiva poi quando il movimento aumenta, aiutando in particolare in condizioni di bassa attività o con eventi sparsi.
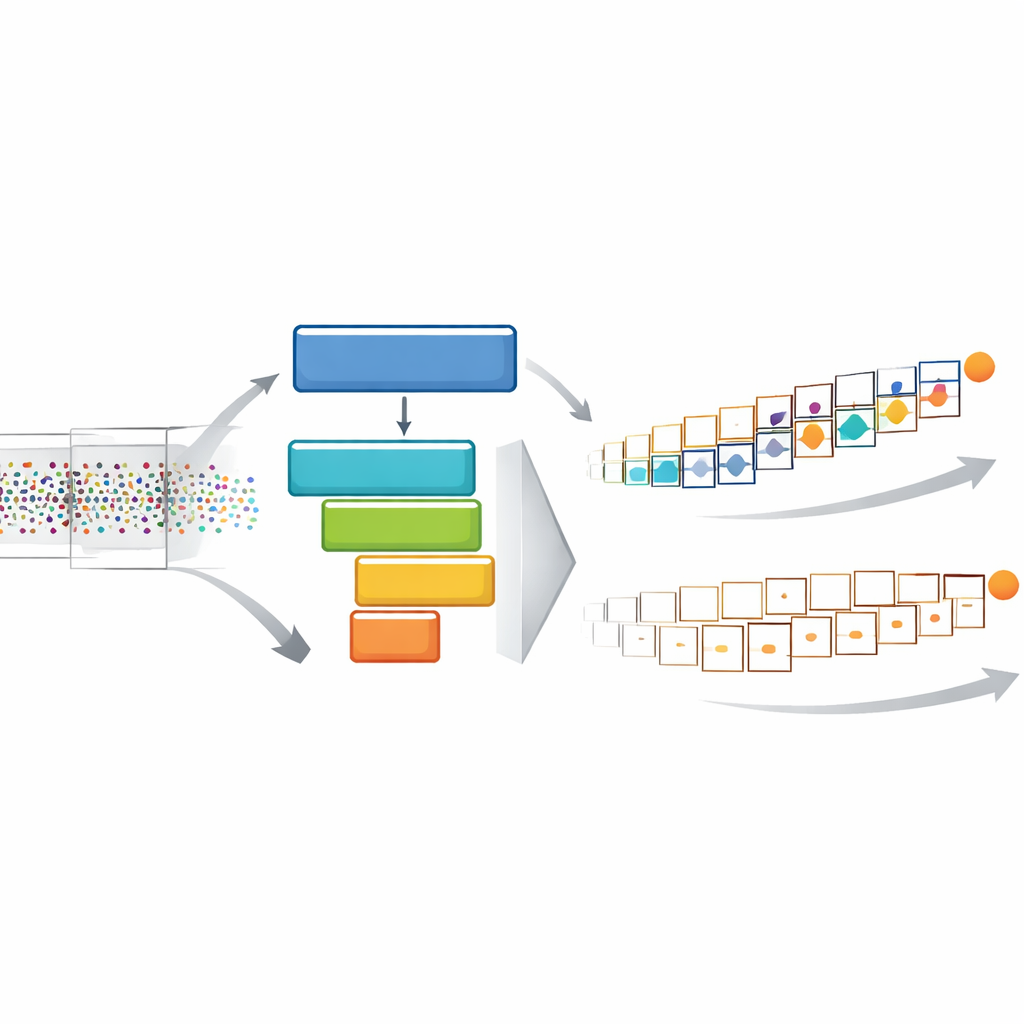
Colmare il divario tra laboratorio e vita reale
Per i non specialisti, il messaggio chiave è semplice: in situazioni ad alto movimento, quanto rapidamente un sistema di visione può aggiornare la sua comprensione del mondo conta tanto quanto quanto sia accurata ciascuna singola previsione. Trattando l’output della telecamera come un vero flusso e incorporando il ritardo direttamente nel punteggio, STARE mette in luce debolezze che i test convenzionali non rilevano e mette in evidenza progetti che funzionano davvero sotto pressione. Insieme al dataset ESOT500 e alle strategie di tracciamento proposte, questo lavoro indica la strada verso robot, veicoli e macchine interattive che non si limitano a vedere bene, ma vedono in tempo.
Citazione: Chu, J., Zhang, R., Yang, C. et al. Bridging the latency gap with a continuous stream evaluation framework in event-driven perception. Nat Commun 17, 2441 (2026). https://doi.org/10.1038/s41467-026-70240-6
Parole chiave: telecamere a eventi, tracciamento in tempo reale, visione robotica, valutazione consapevole della latenza, percezione neuromorfica