Clear Sky Science · it
Un dataset fMRI a 7T di immagini sintetiche per la modellazione out-of-distribution della visione
Perché questo è importante per comprendere la visione e l’IA
I nostri occhi ricevono ogni giorno una grande varietà di immagini, dalle foreste e dai volti ai segnali stradali e al rumore sullo schermo. Eppure la maggior parte degli studi sul cervello e sull’intelligenza artificiale si basa su una fetta ristretta di questo mondo visivo: fotografie di scene naturali. Questo articolo presenta un nuovo tipo di dataset cerebrale che rompe volontariamente questa zona di comfort, usando immagini sintetiche progettate ad arte per mettere sotto stress sia le nostre teorie della visione umana sia i modelli di IA ispirati ad essa.
Costruire un nuovo banco di prova visivo
Gli autori estendono l’influente Natural Scenes Dataset (NSD), che aveva registrato attività cerebrale a ultra‑alta risoluzione con risonanza magnetica a 7 Tesla mentre i partecipanti osservavano decine di migliaia di fotografie. Quel dataset originale ha già alimentato alcuni dei modelli più accurati su come la corteccia visiva risponde alle immagini. Ma poiché tutte quelle immagini sono fotografie relativamente ordinarie, è difficile sapere se un modello che funziona bene su NSD catturi davvero principi generali della visione o si sia semplicemente specializzato su quel particolare repertorio di immagini. Per affrontare questo problema, il team ha scansionato di nuovo gli stessi otto volontari, mostrandogli questa volta 284 immagini “sintetiche” che escono deliberatamente dal consueto mondo delle foto.
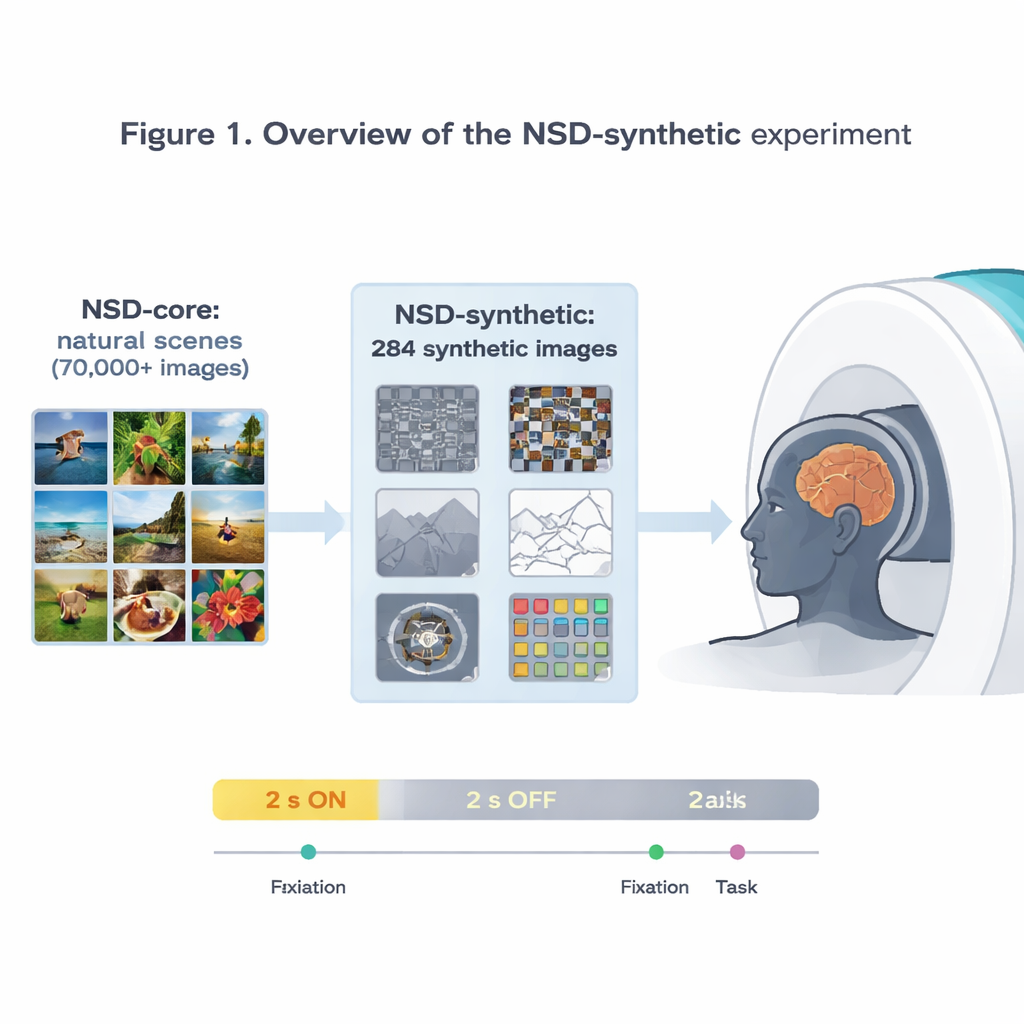
Immagini strane, risposte cerebrali affidabili
Le immagini sintetiche coprono otto famiglie: diversi tipi di rumore visivo, semplici scene naturali e loro versioni alterate (come capovolte o come disegni a linee), scene con contrasto ridotto o fase mescolata, singole parole posizionate in varie locazioni, reticoli a spirale che sondano la sensibilità a motivi fini, e macchie colorate di rumore. Mentre i soggetti o si concentravano su un minuscolo punto lampeggiante o eseguivano un semplice compito di comparazione delle immagini, i ricercatori hanno misurato l’attività cerebrale ogni 1,6 secondi. Dimostrano che questi stimoli dall’aspetto bizzarro producono comunque segnali forti e affidabili, specialmente nelle aree visive precoci che rispondono a tratti basilari come i bordi, il contrasto e il colore. I pattern di attività sulla corteccia corrispondono a preferenze ben note di regioni specializzate, come un’area selettiva per le parole che risponde di più a parole poste centralmente e un’area selettiva per le scene che risponde maggiormente a immagini di ambienti.
Dimostrare che i dati sono davvero “out of distribution”
Perché questo nuovo dataset possa sfidare i modelli, le risposte cerebrali devono essere realmente diverse da quelle evocate dalle fotografie naturali. Gli autori comprimono i pattern di attività sia della NSD originale sia della sessione sintetica in una mappa bidimensionale che riflette quanto siano simili le risposte tra le immagini. In quello spazio, le risposte alle immagini sintetiche si raggruppano separatamente rispetto a quelle alle foto naturali, anche tenendo conto delle differenze tra le sessioni di scansione. Inoltre, le immagini sintetiche si raggruppano naturalmente per tipo visivo—rumore con rumore, reticoli con reticoli, e così via—mostrando che il cervello organizza questi stimoli in base alla loro struttura sottostante, non solo al loro aspetto superficiale.
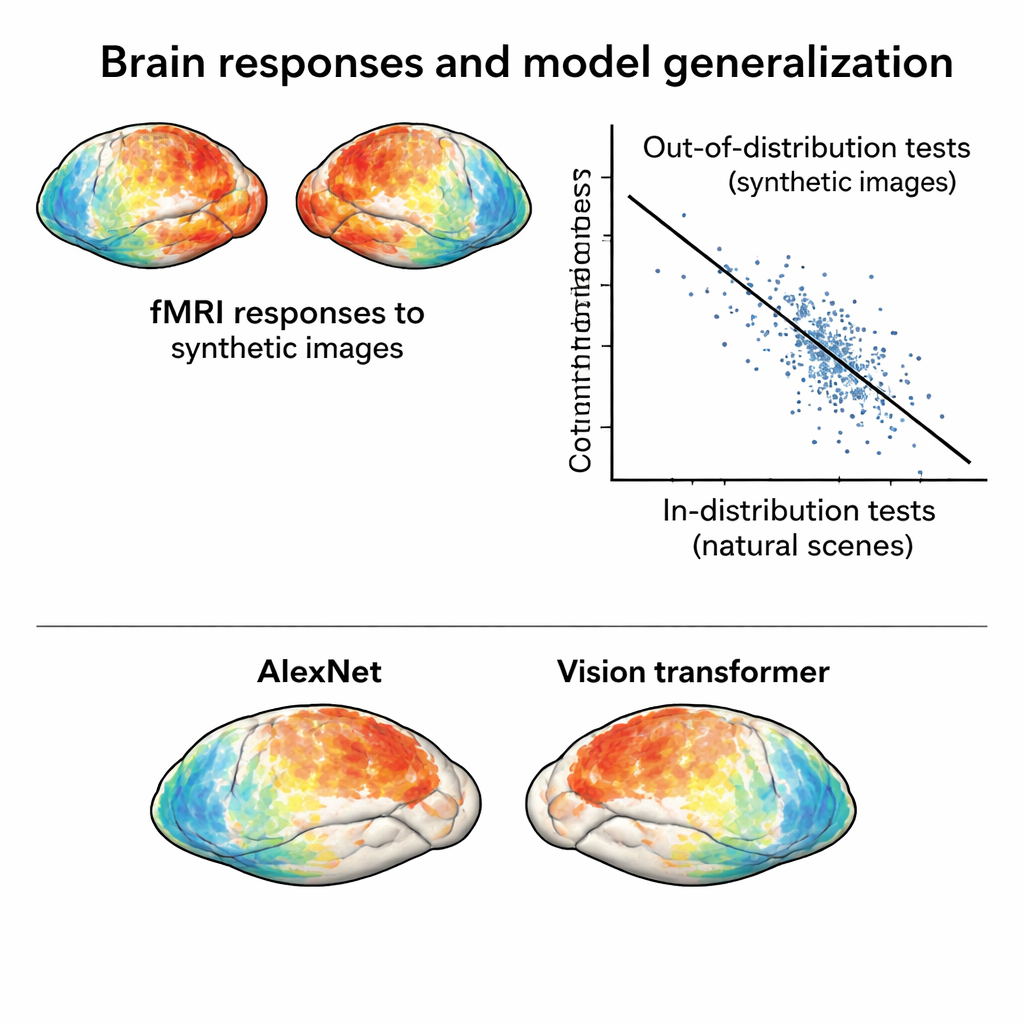
Mettere alla prova il cervello e i modelli di IA in modo più severo
Con questo nuovo dataset “out‑of‑distribution” a disposizione, il team allena modelli di encoding standard: strumenti matematici che prevedono le risposte cerebrali a partire da caratteristiche delle immagini estratte da reti neurali profonde. I modelli addestrati solo sulle foto naturali funzionano bene quando sono testati su foto simili, ma la loro accuratezza cala sensibilmente nel predire le risposte alle immagini sintetiche. Questo calo non è dovuto a dati rumorosi—le risposte sintetiche sono in realtà molto pulite—ma a fallimenti reali dei modelli. Crucialmente, confrontare diverse architetture di reti neurali in queste condizioni più dure rivela contrasti che a malapena emergono nei test in‑distribution. Per esempio, un moderno vision transformer e una rete auto‑supervisionata sovraperformano entrambe le reti convoluzionali classiche di fronte alle immagini sintetiche, suggerendo che il modo in cui un modello è addestrato influisce fortemente sulla sua robustezza.
Quanto possono allontanarsi le immagini dai modelli familiari?
Gli autori vanno oltre e trattano la “distanza” dal set di addestramento come un continuum, non come un’etichetta sì‑o‑no. Misurano quanto la risposta cerebrale a ogni immagine si discosta dalla nuvola di risposte alle scene naturali. Più lontana è un’immagine sintetica in questo spazio, peggio i modelli tendono a performare e meno accuratamente possono essere usati per identificare quale immagine una persona abbia visto basandosi solo sull’attività cerebrale. Mostrano anche che, persino all’interno del mondo delle fotografie ordinarie, set di test scelti con cura possono comportarsi come “lievemente out of distribution”: i modelli rendono al meglio su immagini tratte dallo stesso cluster del loro set di addestramento, meno bene su scene naturali distanti, e peggio sulle stimolazioni sintetiche. Questo quadro graduato trasforma il nuovo dataset in uno strumento per sondare precisamente quali tipi di struttura visiva i modelli attuali non colgono.
Cosa significa per la ricerca futura su cervello e IA
Per i non specialisti, il messaggio chiave è che una buona performance su immagini familiari non garantisce che un modello di IA ispirato al cervello abbia davvero catturato come vediamo. Rilasciando NSD‑synthetic insieme alla NSD originale, gli autori forniscono una “pista di crash test” pubblica per i modelli di visione: un modo per vedere dove si rompono quando le immagini diventano più astratte, più colorate o meno naturali. Poiché il dataset è disponibile pubblicamente e strettamente integrato con una risorsa esistente e ampiamente usata, è probabile che diventi un benchmark di riferimento per testare e migliorare le teorie della visione umana e le reti artificiali che cercano di imitarla.
Citazione: Gifford, A.T., Cichy, R.M., Naselaris, T. et al. A 7T fMRI dataset of synthetic images for out-of-distribution modeling of vision. Nat Commun 17, 1589 (2026). https://doi.org/10.1038/s41467-026-69345-9
Parole chiave: corteccia visiva, dataset fMRI, immagini sintetiche, out-of-distribution, reti neurali profonde