Clear Sky Science · it
FLASH-MM: analisi della espressione differenziale su singola cellula veloce e scalabile usando modelli lineari a effetti misti
Perché le cellule minuscole hanno bisogno di grande potenza di calcolo
La biologia moderna può ora leggere l’attività di migliaia di geni in centinaia di migliaia di singole cellule contemporaneamente. Questa visione a livello di singola cellula promette osservazioni più nitide su come il corpo combatte le infezioni, su differenze tra uomini e donne o su come si sviluppano le malattie. Ma trasformare questi enormi e rumorosi insiemi di dati in scoperte affidabili è dolorosamente lento e, se fatto ingenuamente, può fuorviare. Questo articolo presenta FLASH-MM, un nuovo modo di elaborare i dati a singola cellula che mantiene l’onestà statistica pur rendendo il calcolo sufficientemente veloce per gli studi più grandi di oggi.
La sfida dei dati cellulari rumorosi e affollati
Il sequenziamento dell’RNA a singola cellula misura quali geni sono “accesi” o “spenti” in ciascuna cellula, su molte persone e condizioni. Le cellule della stessa persona tendono a somigliarsi perché condividono geni e storia biologica, mentre le persone differiscono ampiamente l’una dall’altra. Questo crea una struttura stratificata nei dati: molte cellule all’interno di ciascuna persona e molte persone all’interno di ciascuna condizione, per esempio malati rispetto a sani. Se queste relazioni vengono ignorate, i metodi standard possono etichettare per errore migliaia di geni come differenti quando non lo sono, semplicemente perché trattano ogni cellula come un punto dati indipendente. Allo stesso tempo, i dataset a singola cellula sono esplosi in dimensione, includendo oggi centinaia di soggetti e fino a milioni di cellule, mettendo a dura prova gli strumenti statistici convenzionali sia in termini di tempo sia di memoria.
Un modo più intelligente per modellare persone e cellule
Per gestire queste complessità, gli statistici ricorrono spesso ai modelli lineari a effetti misti, che separano esplicitamente le differenze consistenti tra le condizioni (per esempio lo stato rispetto alla tubercolosi o il sesso) dalle differenze casuali tra individui. In linea di principio questi modelli sono ideali per gli studi a singola cellula perché possono tenere conto sia delle somiglianze tra le cellule della stessa persona sia della variabilità tra persone. In pratica, tuttavia, il software largamente usato per questi modelli rallenta molto o esaurisce la memoria negli esperimenti su larga scala. I ricercatori spesso ricorrono quindi a scorciatoie, come la media dei conteggi su tutte le cellule dello stesso tipo per ciascuna persona, che però elimina gran parte delle informazioni granulari cellula-per-cellula che rendono i dati a singola cellula così preziosi.
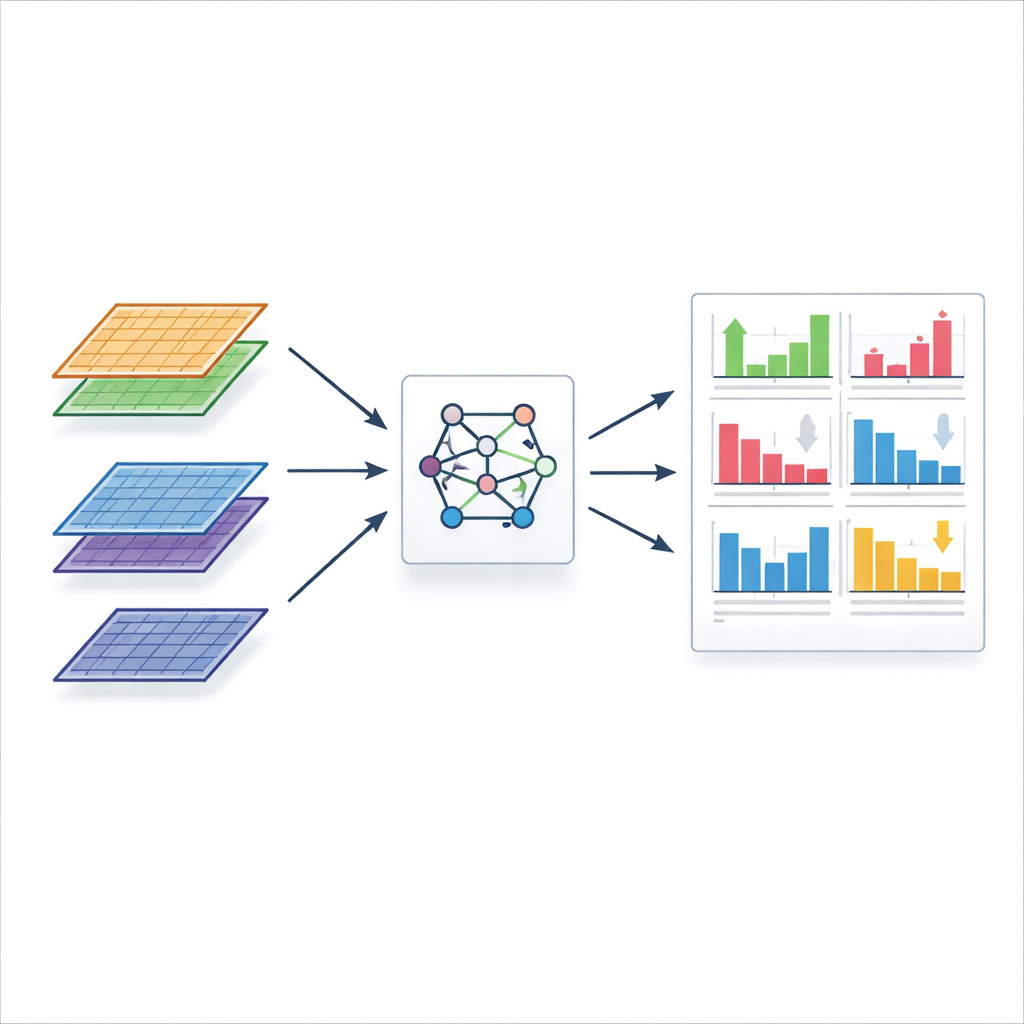
Come FLASH-MM accelera i calcoli pesanti
FLASH-MM conserva i punti di forza dei modelli a effetti misti rivedendo come vengono eseguiti i calcoli. Invece di ripetere l’elaborazione di gigantesche tabelle cellula-per-gene, FLASH-MM prima distilla ogni dataset in un insieme compatto di numeri riassuntivi che catturano come le cellule si rapportano a caratteristiche note come la dimensione della libreria, il tipo cellulare, il trattamento o il donatore. L’algoritmo centrale lavora poi solo con queste matrici più piccole, riducendo l’onere computazionale dal dipendere da ogni cellula al dipendere dal numero molto più limitato di ingredienti del modello. Gli autori modificano inoltre il modo in cui viene rappresentata la variabilità del modello in modo che i test statistici standard restino validi, permettendo semplici statistiche t e z per valutare sia gli effetti principali di interesse sia il beneficio di includere la variazione tra persone. Studi di simulazione con dati artificiali realistici mostrano che i risultati di FLASH-MM corrispondono a quelli del software di riferimento fino a diversi decimali, mentre l’esecuzione è da circa 50 a 140 volte più veloce e richiede molta meno memoria.
Applicare il metodo a tessuti reali
Per dimostrare l’impatto nel mondo reale, il team ha applicato FLASH-MM a due dataset a singola cellula impegnativi. In una mappa di oltre 27.000 cellule renali umane sane provenienti da 19 donatori, FLASH-MM ha cercato differenze nell’attività genica tra donatori maschi e femmine all’interno di ciascun tipo cellulare, trattando ogni persona come un fattore casuale per evitare conclusioni troppo sicure. Ha individuato i pattern più forti legati al sesso in un tipo specifico di cellula del tubulo renale, dove le cellule maschili favorivano vie metaboliche relative alla regolazione degli acidi e della pressione sanguigna, mentre le cellule femminili mostravano arricchimenti per processi di segnalazione e riciclo dei recettori. FLASH-MM ha completato questa analisi in circa un minuto, rispetto a quasi due ore per uno strumento standard. Il metodo ha inoltre analizzato circa mezzo milione di cellule T della memoria da 259 persone in una coorte di tubercolosi, identificando insiemi di geni e vie correlate allo stato di malattia in diversi stati attivati delle cellule T. Qui FLASH-MM ha terminato in meno di un’ora e mezza, contro più di due giorni per l’approccio convenzionale.
Che cosa significa per i futuri studi cellula per cellula
Dal punto di vista divulgativo, il messaggio è che ora possiamo sfruttare meglio l’ondata di dati a singola cellula senza tagliare angoli. FLASH-MM tiene conto di quali cellule provengono da quali persone e condizioni, così che i cambiamenti genici individuati sono più probabilmente espressione di biologia reale piuttosto che artefatti di campionamento o batch. Allo stesso tempo, i suoi calcoli snelli rendono fattibile analizzare centinaia di migliaia di cellule su computer standard, aprendo la strada a studi più ambiziosi su segnali di malattia sottili, differenze legate al sesso e stati cellulari rari. Poiché l’approccio è generale e disponibile sia in R che in Python, può essere esteso a tecnologie più recenti come la mappatura spaziale dei geni e misurazioni molecolari multilivello, aiutando i ricercatori a trasformare vasti dataset a livello cellulare in intuizioni robuste e rilevanti per la clinica.
Citazione: Xu, C., Pouyabahar, D., Voisin, V. et al. FLASH-MM: fast and scalable single-cell differential expression analysis using linear mixed-effects models. Nat Commun 17, 2384 (2026). https://doi.org/10.1038/s41467-026-69063-2
Parole chiave: sequenziamento dell'RNA a singola cellula, espressione differenziale, modelli lineari a effetti misti, genomica statistica, biologia computazionale