Clear Sky Science · it
Il diamante del DNA formula un modello decomponibile a costellazione di lettere per l'archiviazione di dati in DNA
Perché i dati del futuro potrebbero vivere nel DNA
I nostri telefoni, le aziende e gli strumenti scientifici stanno generando dati molto più rapidamente di quanto possano crescere i dischi rigidi e le cassette magnetiche. Il DNA — la stessa molecola che porta l'informazione genetica negli esseri viventi — può anche essere usato per conservare file digitali in una forma straordinariamente compatta e durevole. Questo articolo introduce un nuovo modo per concentrare ancora più informazione in filamenti di DNA sintetico mantenendo la lettura pratica e affidabile, potenzialmente rendendo l'archiviazione su DNA più economica e scalabile.
Dalle quattro lettere del DNA a miscele più ricche
L'archiviazione tradizionale su DNA utilizza le quattro basi naturali — A, T, G e C — per rappresentare bit digitali, un po' come zeri e uni su un disco. In quello schema, ogni posizione in un filamento di DNA può trasportare al massimo due bit di informazione, perché è limitata a una delle quattro scelte. Gli autori partono da un'idea emergente: invece di collocare una singola base in ogni posizione, creano miscele controllate di basi, chiamate lettere composite. Per esempio, una posizione potrebbe essere composta da una miscela 50:50 di A e T, oppure da una miscela 25:25:25:25 di tutte e quattro le basi. Quando vengono sintetizzate molte copie di ciascun filamento, il sequenziamento di queste miscele rivela le proporzioni delle basi e, a sua volta, un simbolo digitale che può rappresentare più di due bit.
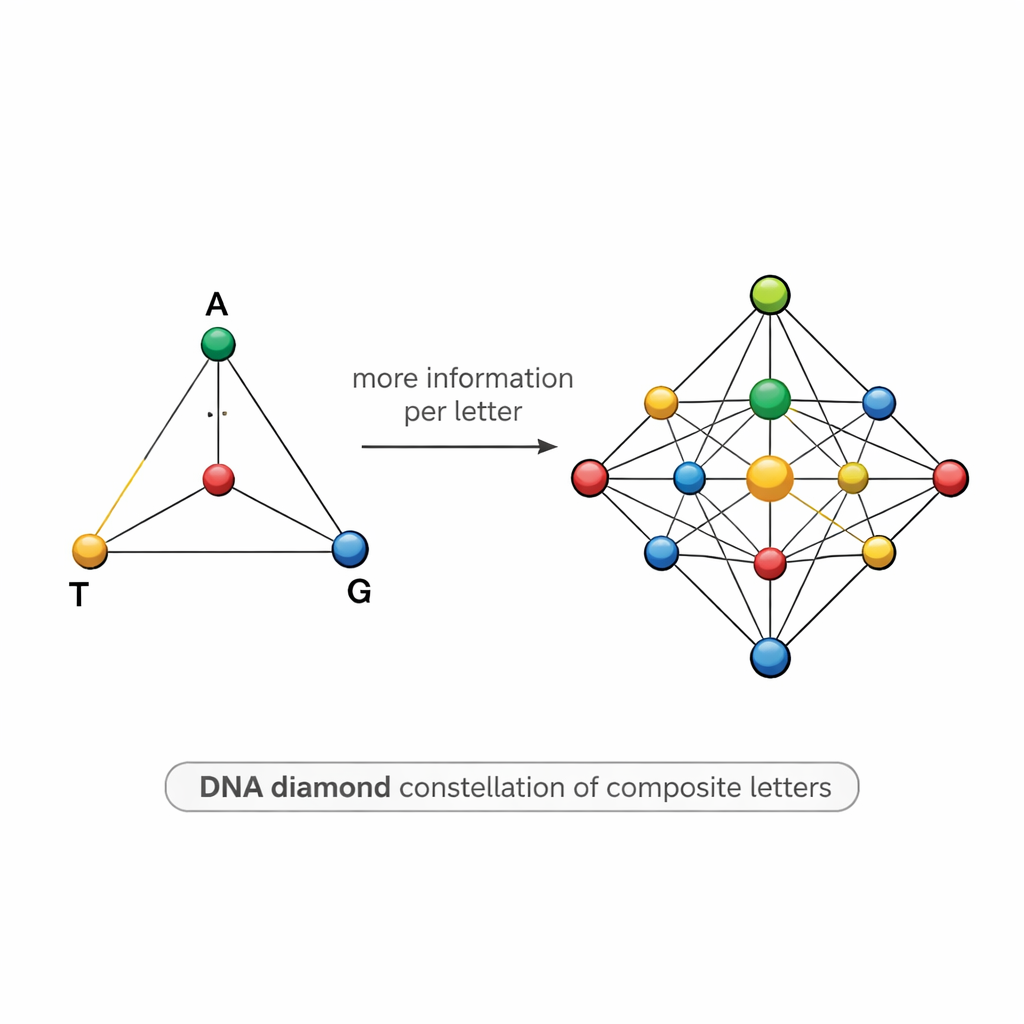
Una mappa a forma di diamante dei simboli del DNA
Progettare tali miscele è complesso. Se due simboli sono troppo simili — per esempio, uno è 50% A e 50% T e un altro è 55% A e 45% T — il rumore del sequenziamento può confonderli, causando errori e costringendo gli scienziati a sequenziare molte più copie di quanto sarebbe desiderabile. Per affrontare questo problema, il team propone un modello strutturato a “diamante del DNA”: un insieme di 15 lettere composite disposte come punti su un tetraedro i cui vertici sono A, T, G e C. L'insieme include basi pure ai vertici, miscele uguali di due basi lungo i lati, miscele di tre basi su ciascuna faccia e una miscela perfettamente uniforme delle quattro basi al centro. Questa costellazione accuratamente scelta innalza l'informazione teorica per posizione a circa 3,9 bit, mantenendo però i simboli sufficientemente distinti da poter essere separati nella pratica.
Decodifica più intelligente con entropia e indicizzazione
Leggere i dati dal DNA significa inferire quale lettera composita fosse intenzionata in ogni posizione a partire da misurazioni rumorose delle frequenze delle basi. Gli autori prendono in prestito una strategia dalle telecomunicazioni chiamata partizionamento dell'insieme. Prima valutano quanto una posizione risulti “mista”, usando una quantità chiamata entropia che è bassa per le basi pure e più alta per miscele complesse. Questo assegna rapidamente ogni posizione a uno dei quattro gruppi: basi pure, miscele di due basi, miscele di tre basi o la miscela delle quattro basi. Poi, all'interno del gruppo scelto, un calcolo di verosimiglianza più preciso individua la lettera più probabile. Questo approccio in due fasi riduce la confusione tra simboli e diminuisce il tempo di calcolo rispetto ai metodi precedenti. Per evitare che i filamenti vengano scambiati l'uno per l'altro, ogni pezzo di DNA porta sequenze di indice protette dagli errori a entrambe le estremità, e le letture di lunghezza errata — spesso causate da inserzioni o delezioni — vengono scartate prima della decodifica.
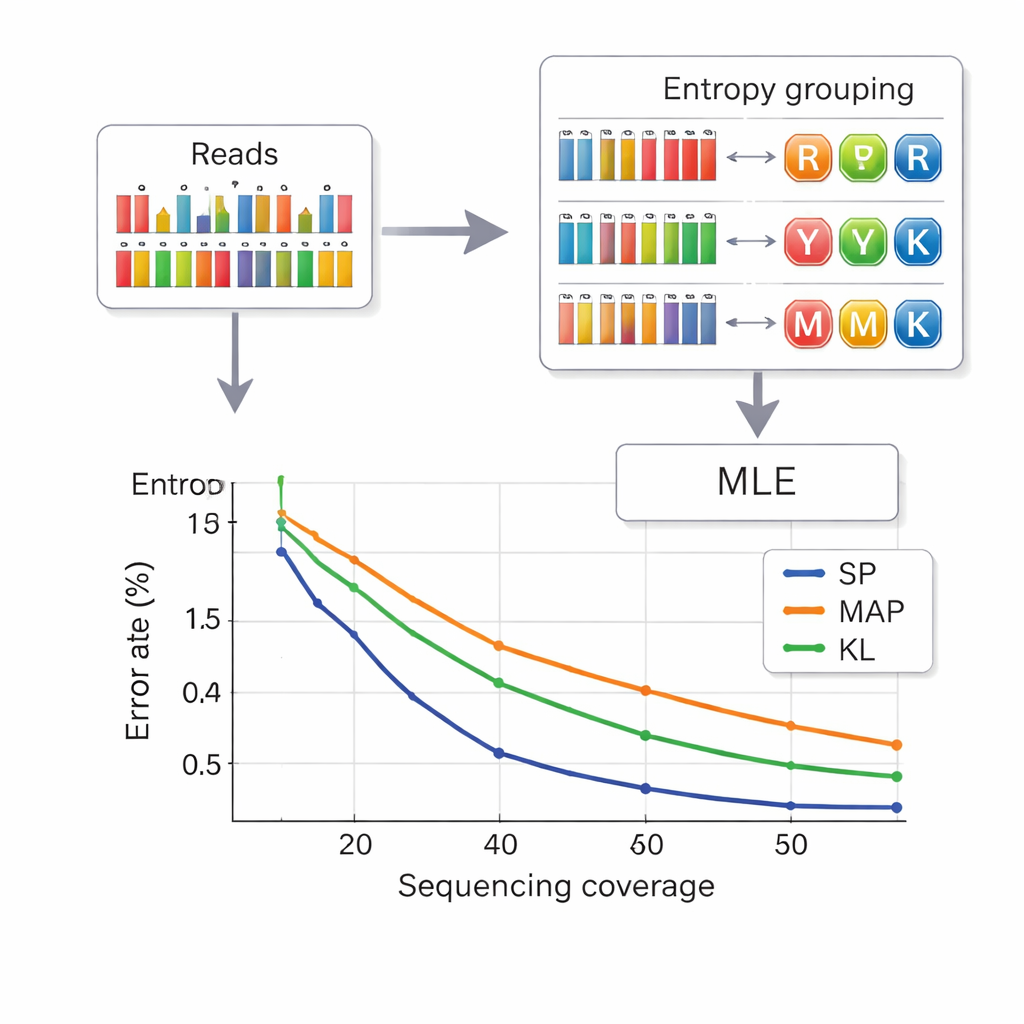
Inserire più dati con meno letture
I ricercatori hanno testato il loro sistema sia in pool di DNA piccoli sia grandi, usando piattaforme di sintesi commerciali. Con un alfabeto composito a otto lettere hanno raggiunto una densità di payload di 2,5 bit per posizione di DNA e sono riusciti a recuperare i file perfettamente con una media di 14 letture di sequenziamento per filamento — migliore densità rispetto a precedenti schemi a sei lettere e con meno letture necessarie. Con il pieno alfabeto a 15 lettere del diamante del DNA, hanno ottenuto 3,125 bit per posizione per i dati principali e hanno comunque recuperato tutto senza errori a una copertura di 33 volte. Simulazioni ed esperimenti hanno inoltre mostrato che il loro metodo basato sull'entropia si comporta quasi quanto l'approccio di decodifica più accurato, ma più lento, e nettamente meglio delle tecniche più vecchie, specialmente a profondità di sequenziamento inferiori.
Cosa significa per le memorie del futuro
Per un lettore non specialistico, il messaggio principale è che gli autori hanno trovato un modo per insegnare “nuovi trucchi” al DNA senza inventare nuova chimica: mescolando astutamente le quattro basi esistenti e decodificandole in modo più intelligente, possono immagazzinare più bit per molecola controllando i costi. Il loro alfabeto a forma di diamante, combinato con indicizzazione robusta e correzione degli errori, mostra che l'archiviazione di dati ad alta capacità su DNA è possibile con uno sforzo di sequenziamento relativamente modesto. Man mano che la sintesi e il sequenziamento del DNA continueranno a diventare più economici, tali progetti potrebbero aiutare a trasformare il DNA da curiosità di laboratorio in un mezzo realistico per archiviare le memorie digitali del mondo.
Citazione: Ge, Q., Ren, M., Qi, T. et al. DNA diamond formulates a decomposable composite letter constellation model for DNA data storage. Nat Commun 17, 1704 (2026). https://doi.org/10.1038/s41467-026-68861-y
Parole chiave: archiviazione dati in DNA, lettere composite, densità informativa, correzione degli errori, archiviazione digitale