Clear Sky Science · it
Database di nanoparticelle lipidiche per la modellazione struttura-funzione e il design guidato dai dati per la consegna di acidi nucleici
Perché le piccole bolle di grasso contano per le medicine del futuro
Le nanoparticelle lipidiche sono microscopiche bolle a base di grasso che trasportano in modo sicuro istruzioni genetiche—come i vaccini a mRNA—nelle nostre cellule. Hanno contribuito al successo dei vaccini contro il COVID-19, eppure gli scienziati non comprendono ancora pienamente come la loro composizione chimica dettagliata controlli l’efficacia. Questo articolo descrive una nuova risorsa online, il Lipid Nanoparticle Database (LNPDB), creata per raccogliere dati dispersi in un unico luogo in modo che i ricercatori possano progettare in modo sistematico medicinali a base di geni migliori e più sicuri.
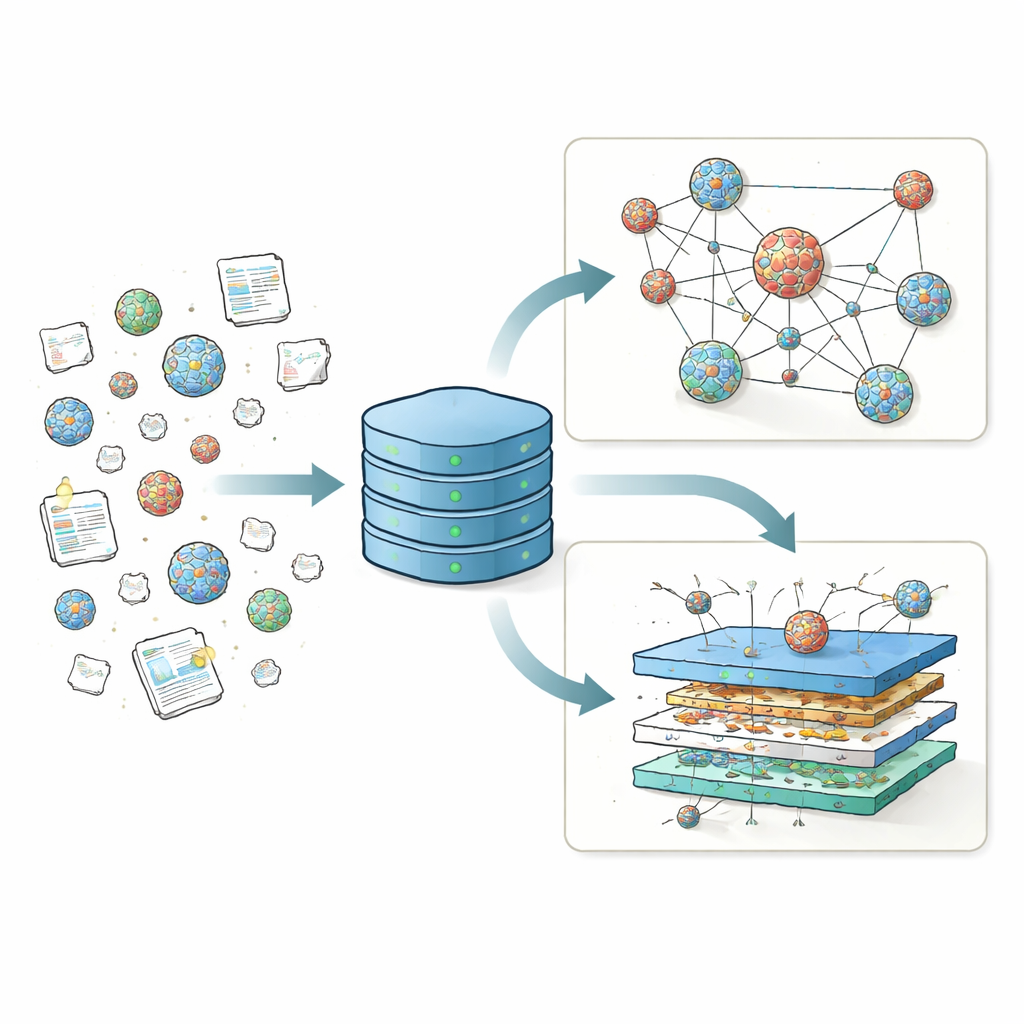
Riunire risultati dispersi in un unico archivio
Per anni diversi laboratori hanno testato migliaia di ricette per nanoparticelle lipidiche (LNP), variando il lipide carico principale, i lipidi ausiliari, il colesterolo e i lipidi con rivestimento protettivo per vedere quali combinazioni consegnano il materiale genetico in modo più efficace. Ma questi risultati sono stati riportati in molti formati e in decine di pubblicazioni, rendendo difficile confrontare gli studi o individuare tendenze generali. A differenza della scienza delle proteine, ancorata a una banca dati centrale come il Protein Data Bank che ha alimentato strumenti come AlphaFold, il campo delle LNP non aveva un repository unificato per dati di struttura e prestazione. LNPDB colma questa lacuna raccogliendo informazioni dettagliate su 19.528 formulazioni di LNP tratte da 42 studi e da un fornitore commerciale, e standardizzando il modo in cui gli ingredienti di ogni particella, le condizioni di prova e gli esiti sono codificati.
Cosa contiene il nuovo database
Ogni voce di LNP nel LNPDB è descritta lungo tre assi principali: composizione, esperimento e simulazione. I campi di composizione registrano quali lipidi sono stati usati, quanti atomi di azoto contiene il lipide carico principale e i rapporti di miscelazione esatti tra i quattro componenti principali: lipide ionizzabile, lipide ausiliario, colesterolo e un lipide con polietilenglicole (PEG). I campi sperimentali catturano che tipo di carico genetico è stato consegnato—più spesso mRNA che codifica per una proteina reporter—dove è stato inviato (ad esempio cellule in coltura, fegato, polmone o muscolo), come sono state preparate le particelle e come è stato misurato il successo. Infine, i campi di simulazione forniscono file pronti all’uso che descrivono il comportamento fisico di ciascuna molecola lipidica con sufficiente dettaglio per eseguire simulazioni atomiche delle membrane lipidiche. Insieme, questi descrittori standardizzati trasformano un mosaico di schermate individuali in un panorama coerente che la comunità può cercare, filtrare ed espandere.
Insegnare ai computer a riconoscere ricette di consegna migliori
Un uso immediato di LNPDB è migliorare i modelli di apprendimento automatico che predicono quali formulazioni consegneranno il materiale genetico in modo più efficace. Gli autori hanno riaddestrato il loro modello di deep learning esistente, chiamato LiON, con il dataset ampliato di LNPDB, raddoppiando più che il numero di esempi visti in precedenza. LiON apprende schemi che collegano le strutture chimiche dei lipidi ionizzabili, la miscela di componenti ausiliari e il contesto sperimentale a quanto bene ha funzionato ciascuna formulazione. Con dati più ricchi, le predizioni di LiON hanno corrisposto meglio ai risultati sperimentali per la maggior parte dei set di test e hanno superato un modello concorrente chiamato AGILE su diversi dataset indipendenti. Questo suggerisce che un set di addestramento ampio, diversificato e in continua crescita è fondamentale per costruire strumenti di progettazione di uso generale per le future medicine a base di LNP.
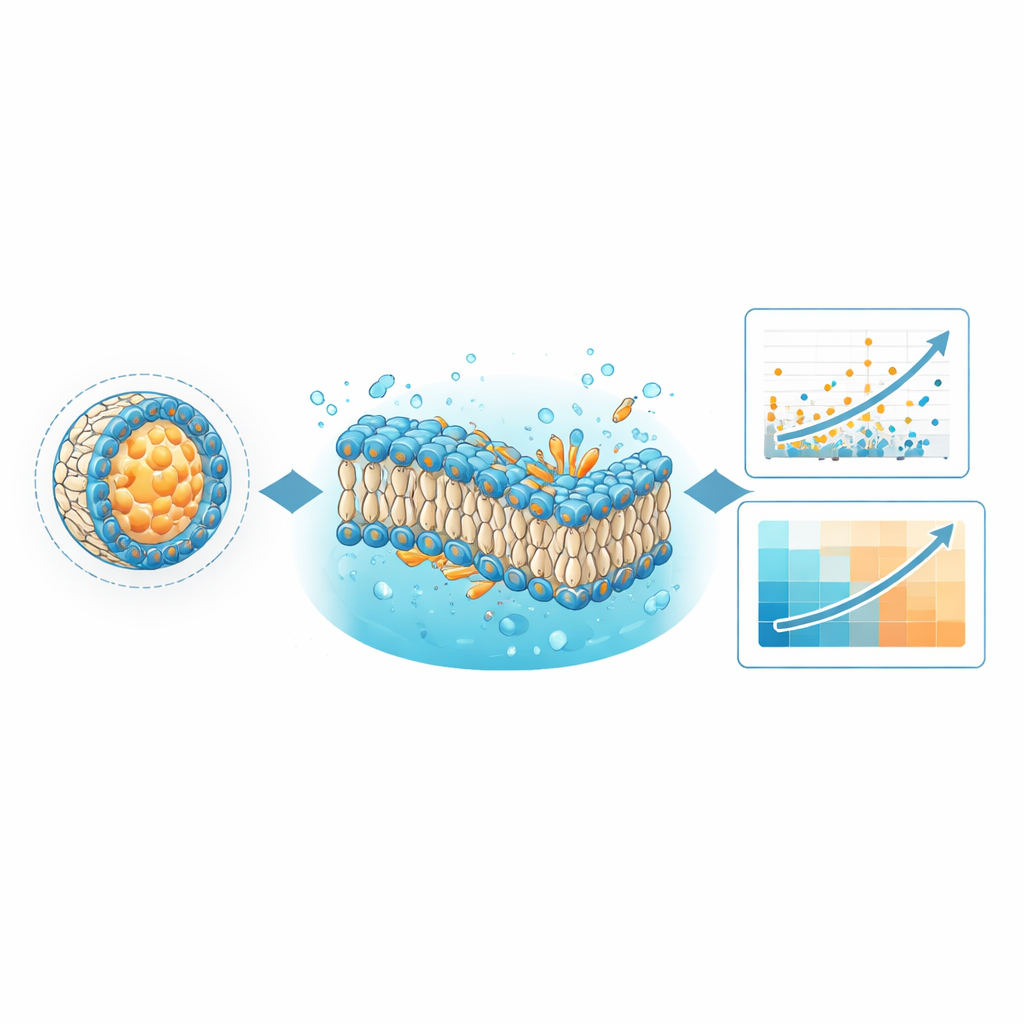
Osservare membrane modello per scoprire regole nascoste
Il database è progettato anche per un tipo molto diverso di calcolo: le simulazioni fisiche basate sulla dinamica molecolare. Usando i file di simulazione forniti con LNPDB, il team ha costruito membrane semplificate che rappresentano formulazioni LNP selezionate e ne ha osservato il comportamento per microsecondi di tempo simulato. Si sono posti due domande: le doppie membrane lipidiche modellate rimangono integre, e quale forma complessiva assumono i lipidi chiave all’interno della membrana? Le simulazioni hanno rivelato che le formulazioni le cui membrane restavano stabili avevano maggiori probabilità di avere successo sperimentalmente. Hanno inoltre quantificato una caratteristica chiamata “parametro critico di impaccamento”, che riflette se un lipide è più a forma di cono o di cono invertito nella membrana. In diverse librerie testate, i lipidi la cui forma favoriva curvature negative—pensate per aiutare le particelle a fondersi con e a disturbare le membrane endosomiali—mostravano una consegna più efficace, a volte correlando con la prestazione meglio dello stesso modello di deep learning.
Una nuova base per una nanomedicina più intelligente
Per un non specialista, il messaggio principale è che questo lavoro costruisce una “mappa” condivisa e in crescita di come gli ingredienti e la struttura delle piccole bolle di grasso si collegano alla loro capacità di consegnare terapie genetiche. Raccogliendo decine di migliaia di esperimenti passati, abilitando modelli predittivi potenti e fornendo strumenti per simulare il comportamento delle particelle a livello molecolare, LNPDB pone le basi per un design più razionale anziché il tentativo ed errore. Col tempo, questo approccio guidato dai dati potrebbe accelerare la creazione di vaccini più efficaci, terapie di editing genetico e altre terapie a base di acidi nucleici, aiutando nel contempo i ricercatori a capire perché certe ricette di nanoparticelle funzionano—e altre no.
Citazione: Collins, E., Ji, J., Kim, SG. et al. Lipid Nanoparticle Database towards structure-function modeling and data-driven design for nucleic acid delivery. Nat Commun 17, 2464 (2026). https://doi.org/10.1038/s41467-026-68818-1
Parole chiave: nanoparticelle lipidiche, consegna di mRNA, nanomedicina, apprendimento automatico, dinamica molecolare