Clear Sky Science · it
Predire collegamenti mancanti nelle reti trofiche usando modelli impilati e tratti delle specie
Perché indovinare catene alimentari nascoste è importante
Gli ecologi spesso rappresentano la natura come una rete di “chi mangia chi”, dai minuscoli microrganismi del suolo ai predatori in mare. Ma anche le migliori reti trofiche sono piene di buchi: molte relazioni trofiche reali non vengono mai osservate. Questo articolo mostra come un approccio moderno di machine learning, chiamato model stacking, possa usare i modelli delle interazioni note insieme a semplici informazioni sulle specie — come la dimensione corporea e lo stile di vita — per prevedere quali collegamenti mancanti sono probabilmente reali. Migliori ipotesi sui collegamenti nascosti possono affinare la nostra comprensione della stabilità degli ecosistemi e aiutare a concentrare il lavoro sul campo scarseggiato sulle interazioni più informative.
Dalla natura disordinata ai diagrammi di rete
Le reti trofiche trasformano gli ecosistemi in reti: le specie sono nodi e le frecce mostrano chi mangia chi. In pratica, raccogliere ogni collegamento trofico è quasi impossibile. Le osservazioni sono faticose, eventi rari sono facili da perdere e il numero di collegamenti possibili cresce molto più velocemente del numero di specie. Gli strumenti tradizionali di predizione dei collegamenti presi dalle reti sociali funzionano ragionevolmente bene, ma di solito ignorano caratteristiche chiave delle reti trofiche: le frecce alimentari hanno una direzione (dal cibo al consumatore), i tratti delle specie restringono quali interazioni sono ecologicamente plausibili e la maggior parte delle reti trofiche presenta una forte gerarchia dalle piante fino ai predatori apicali. Gli autori pertanto adattano lo stacking — una tecnica che impara a combinare molte regole di previsione semplici — specificamente alle realtà delle reti trofiche.

Insegnare agli algoritmi il buon senso ecologico
Il modello impilato combina dozzine di predittori strutturali, che si basano solo sullo schema di chi mangia chi, con predittori basati sui tratti che usano proprietà delle specie come massa corporea, tipo di movimento e tipo metabolico. Le regole strutturali includono, per esempio, se due specie condividono molti vicini nella rete o quanto sono centrali. Gli autori rivedono queste regole per rispettare il flusso di energia lungo la catena alimentare: invece di chiudere triangoli non diretti, il loro motivo di “vicini comuni ecologicamente rilevanti” si concentra su motivi che assomigliano a catene trofiche realistiche. Le regole basate sui tratti catturano sia somiglianze sia contrasti. Alcuni tratti, come l’habitat, favoriscono interazioni tra specie simili, mentre altri, come il livello trofico, favoriscono collegamenti tra partner dissimili. Misure di distanza tra profili di tratti, e in particolare i rapporti di massa corporea, permettono al modello di sfruttare sia pattern assortativi sia disassortativi.
Mettere il metodo alla prova
Per verificare se lo stacking impari davvero a usare struttura e tratti, il team ha prima costruito reti trofiche artificiali con regole note. Hanno mescolato reti in cui i collegamenti dipendono solo da una struttura di gruppi nascosti con reti in cui i collegamenti sono determinati completamente dai tratti delle specie. In questi test controllati, un modello basato solo sulla struttura eccelleva quando i tratti erano irrilevanti e un modello basato solo sui tratti eccelleva quando i tratti dominavano. Crucialmente, il modello impilato completo ha performato tanto bene quanto il miglior modello specializzato in ciascuno degli estremi e ha fatto meglio di entrambi nei casi misti. Questo dimostra che, senza essere informato sulle regole vere, lo stacking può scoprire quanto peso assegnare a struttura rispetto ai tratti per ogni rete.
Come le reti trofiche reali rivelano i loro segreti
Gli autori hanno poi applicato il metodo a una raccolta globale di 290 reti trofiche empiriche provenienti da laghi, corsi d’acqua, oceani e habitat terrestri sopra e sotto il suolo, ciascuna annotata con un piccolo insieme di tratti. In questo corpus eterogeneo, tutti e tre i tipi di modello — solo struttura, solo tratti e completo — hanno performato molto meglio del caso casuale nel distinguere i collegamenti mancanti veri dalle assenze vere. In media, il modello completo ha raggiunto una discriminazione quasi perfetta, superando leggermente il modello solo struttura e battendo nettamente il modello solo tratti. Tuttavia, in circa una rete su dieci, un modello più semplice che usava solo tratti o solo struttura ha ottenuto i migliori risultati, sottolineando che diversi ecosistemi codificano le loro regole d’interazione in modo diverso. Le graduatorie interne delle caratteristiche del modello impilato evidenziano un piccolo numero di predittori particolarmente informativi: misure relative a consumatori e risorse generalisti, regole in stile «vicino più prossimo» che prendono partner da specie simili, sommari a basso rango della rete e rapporti di massa corporea tra consumatore e preda.
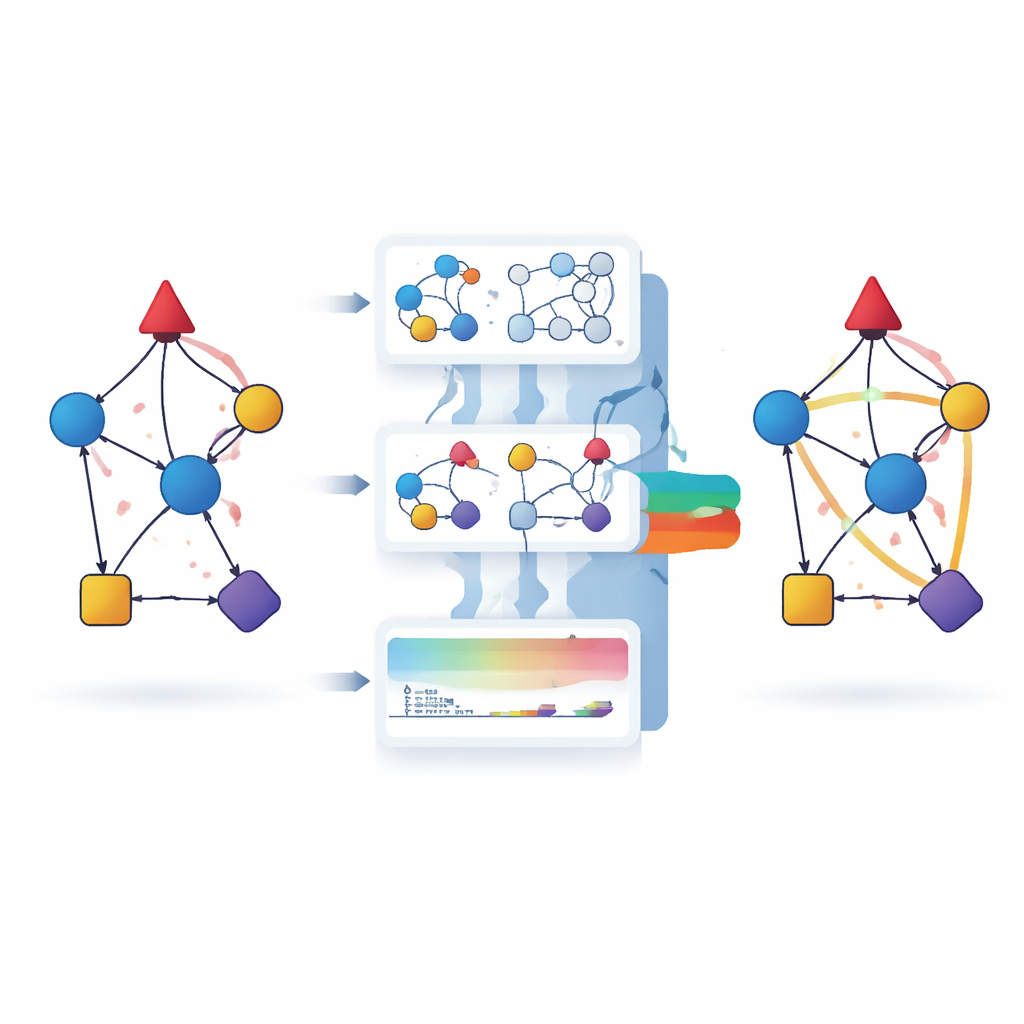
Quando e dove la predizione funziona meglio
Poiché il dataset copre molti ecosistemi, gli autori hanno potuto chiedersi cosa renda una rete trofica più facile da prevedere. Reti più grandi, più densamente connesse, con migliore risoluzione tassonomica e minore compartimentazione tendevano a fornire una maggiore accuratezza, probabilmente perché offrono al modello più segnali strutturali da cui apprendere. Le reti terrestri sotterranee, come le comunità del suolo, sono state le più facili da prevedere, mentre le reti marine e terrestri soprassuolo sono risultate un po’ più difficili. L’utilità relativa dei tratti rispetto alla struttura è variata anche per tipo di ecosistema, con la dimensione corporea che gioca un ruolo particolarmente forte nei sistemi marini. Queste differenze suggeriscono contrasti ecologici più profondi su come le interazioni sono organizzate nei diversi ambienti.
Cosa significa questo per la comprensione degli ecosistemi
Per i non specialisti, il messaggio chiave è che anche con dati parziali e rumorosi è ora possibile ricostruire con alta fiducia pezzi non osservati delle reti ecologiche. Combinando in modo intelligente molti indizi strutturali semplici con pochi tratti facilmente misurabili, il modello impilato può non solo colmare i collegamenti trofici mancanti più probabili, ma anche rivelare quali caratteristiche — come la dimensione corporea o il comportamento da generalista — modellano più fortemente chi mangia chi. Questo apre la strada a indagini di campo più efficienti, test più rigorosi della teoria ecologica e, a lungo termine, previsioni migliori su come gli ecosistemi potrebbero rispondere alla perdita di specie o ai cambiamenti ambientali.
Citazione: Van Kleunen, L.B., Dee, L.E., Wootton, K.L. et al. Predicting missing links in food webs using stacked models and species traits. Nat Commun 17, 2298 (2026). https://doi.org/10.1038/s41467-026-68769-7
Parole chiave: reti trofiche, tratti delle specie, predizione di collegamenti, reti ecologiche, apprendimento automatico