Clear Sky Science · it
Valutazione delle tecnologie di atlasing single-cell ATAC-seq usando modelli sequence-to-function
Leggere il manuale d’istruzioni della cellula
Ogni cellula del tuo corpo legge lo stesso DNA, eppure le cellule cerebrali, muscolari e del sistema immunitario si comportano in modo molto diverso. Questo articolo affronta un rompicapo fondamentale dietro a quella diversità: come brevi tratti di DNA chiamati enhancer funzionano come interruttori per accendere o spegnere i geni in tipi cellulari specifici. Gli autori mostrano che nuove tecnologie di laboratorio più economiche possono generare i grandi set di dati necessari per addestrare i moderni modelli di deep learning che leggono le sequenze di DNA e prevedono quali enhancer sono attivi in quali cellule, avvicinandoci alla decodifica della “grammatica” regolatoria del genoma.
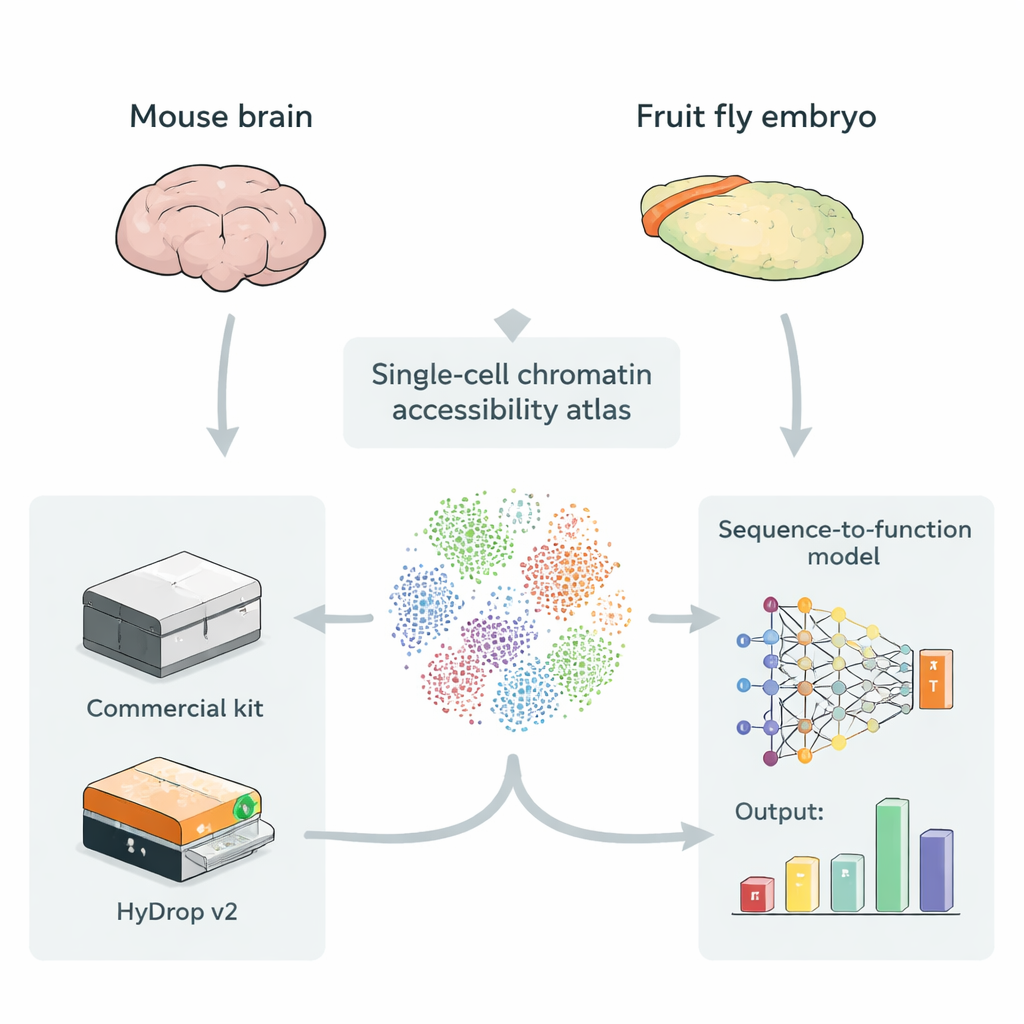
Costruire mappe del DNA accessibile nelle singole cellule
Gli enhancer si trovano di solito in tratti di DNA più aperti e accessibili, il che facilita il legame delle proteine regolatorie. Una tecnica chiamata single-cell ATAC-seq misura quali parti del genoma sono aperte in migliaia fino a centinaia di migliaia di singole cellule contemporaneamente, creando un “atlante” del DNA accessibile attraverso molti tipi cellulari. Questi atlanti sono carburante ideale per i modelli di deep learning che prendono in input la sequenza genomica grezza e apprendono a prevedere quanto ciascuna piccola regione funzioni come enhancer in ogni tipo cellulare. Finora, tuttavia, la maggior parte di questi atlanti si è basata su strumenti commerciali costosi, sollevando la domanda se metodi open-source e a basso costo possano fornire dati di addestramento di pari valore per questi modelli.
Un’alternativa open-source alle piattaforme commerciali
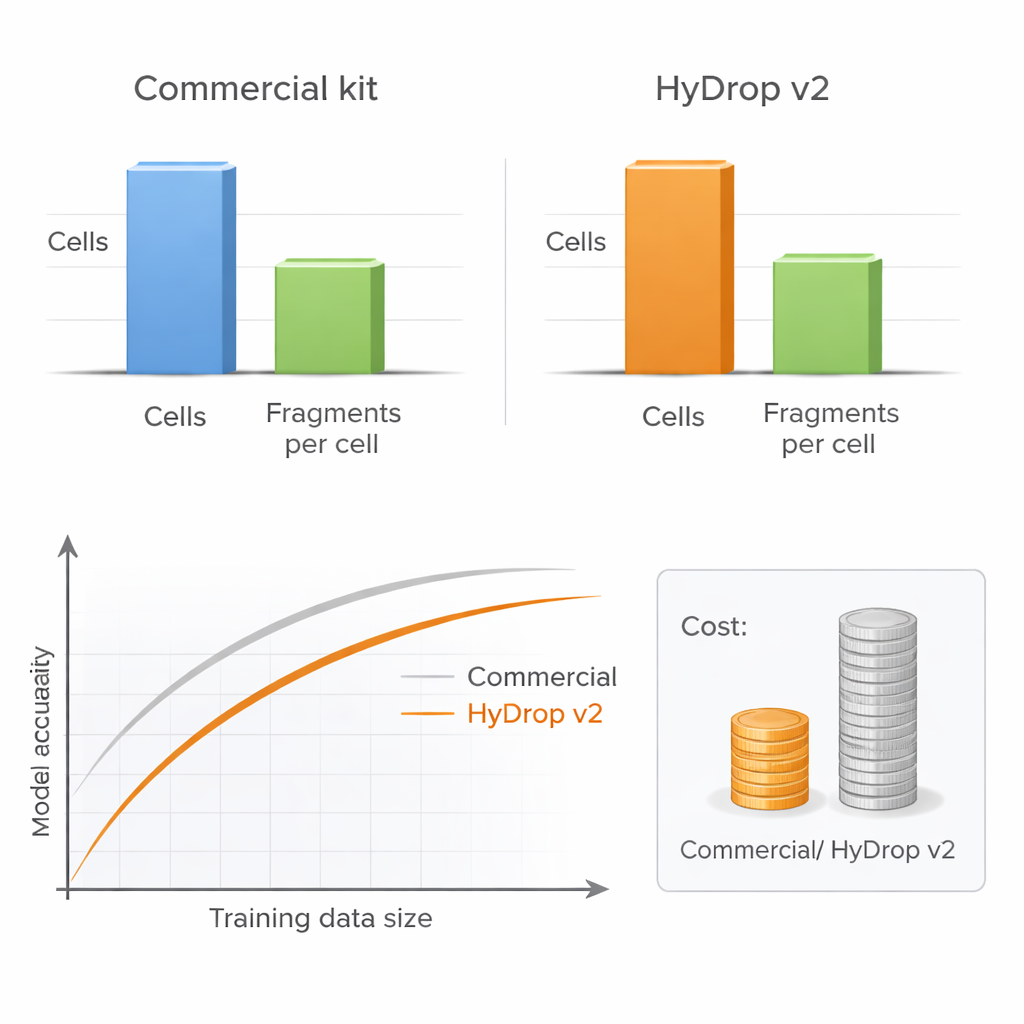
Gli autori presentano HyDrop v2, un metodo droplet-based migliorato per single-cell ATAC-seq che utilizza perle di idrogel personalizzate per barcodeare le singole cellule. Mettono a confronto HyDrop v2 con un kit commerciale ampiamente usato costruendo grandi atlanti a partire da due sistemi molto diversi: la corteccia motoria del topo adulto e embrioni di moscerino della frutta in stadio avanzato. HyDrop v2 genera una qualità dei dati comparabile—recuperando gli stessi principali tipi cellulari e set molto simili di regioni di DNA accessibile—pur costando circa quattordici volte meno per campione di cervello di topo. Importante, i dati provenienti da esperimenti HyDrop v2 si integrano senza problemi con quelli commerciali, permettendo ai ricercatori di mescolare piattaforme nella costruzione di atlanti molto ampi.
Addestrare modelli di deep learning per leggere la logica degli enhancer
Per verificare se i dati più economici siano sufficienti per la modellizzazione avanzata, il gruppo addestra modelli sequence-to-function di deep learning su atlanti ottenuti con piattaforme commerciali o con HyDrop v2. Questi modelli apprendono direttamente dalla sequenza del DNA a prevedere quanto ogni regione sia accessibile in ciascun tipo cellulare, e possono evidenziare brevi motivi di sequenza che probabilmente corrispondono a siti di legame per specifiche proteine regolatorie. Nella corteccia del topo, i modelli addestrati con i dati HyDrop v2 e quelli su dati commerciali hanno performance complessive simili e pari capacità di recuperare noti “interruttori” enhancer precedentemente validati in organismi vivi. Nell’embrione di moscerino, entrambe le piattaforme supportano modelli in grado di analizzare regioni di 2.000 paia di basi e di identificare i segmenti core di circa 500 paia di basi che guidano realmente l’attività enhancer specifica dei tessuti, come le regioni che controllano l’espressione genica nei neuroblasti o nei muscoli.
Più cellule possono valere più profondità
Una domanda pratica chiave per ogni laboratorio è se sequenziare ogni cellula molto in profondità o profilare più cellule a profondità inferiore. Variando in modo sistematico il numero di cellule e il numero di frammenti di DNA per cellula, gli autori mostrano che le prestazioni del modello risentono poco se la profondità di sequenziamento viene ridotta a un livello moderato, purché siano incluse abbastanza cellule. Al contrario, ridurre il numero di cellule danneggia chiaramente l’accuratezza del modello, specialmente quando si valuta la performance attraverso molti tipi cellulari contemporaneamente. Poiché HyDrop v2 è molto più economico per cellula, i ricercatori possono aggiungere facilmente decine di migliaia di celle extra, recuperando o addirittura superando le prestazioni di modelli basati su piattaforme commerciali a una frazione del costo.
Vedere le impronte proteiche sul DNA
Lo studio esamina anche se diverse piattaforme di laboratorio introducano bias sottili nel modo in cui l’enzima ATAC-seq taglia il DNA, che potrebbero fuorviare i modelli che cercano di dedurre dove le proteine si trovano sul genoma. Usando un tool basato su reti neurali separato che corregge le preferenze dell’enzima, gli autori dimostrano che HyDrop v2 e i kit commerciali producono schemi di attività enzimatica quasi identici sia nelle cellule di topo sia in quelle di moscerino. Dopo la correzione, entrambi i dataset rivelano “impronte” a scala fine dove proteine regolatorie e nucleosomi sembrano proteggere il DNA dal taglio, e queste impronte corrispondono ai motivi di sequenza evidenziati dai modelli sequence-to-function. Questo accordo suggerisce che piattaforme open-source e commerciali sono ugualmente adatte per studi dettagliati sull’interazione tra proteine e DNA.
Perché questo è importante per decifrare il genoma
Per i non specialisti, il messaggio principale è che ora possiamo costruire mappe molto ampie e accessibili di come il DNA viene utilizzato nelle singole cellule e addestrare potenti modelli di deep learning su queste mappe senza dipendere esclusivamente da costosi hardware proprietari. HyDrop v2 fornisce dati che supportano la predizione di enhancer, l’interpretazione di motivi di sequenza e le impronte di legame proteico comparabili ai migliori metodi commerciali, a condizione che vengano profilate un numero sufficiente di cellule. Questo apre la strada alla costruzione di atlanti su scala organismica degli elementi regolatori in salute e malattia, accelerando gli sforzi per leggere le istruzioni regolatorie del genoma e per progettare nuovi interruttori genetici mirati con precisione per la ricerca e le future terapie.
Citazione: Dickmänken, H., Wojno, M., Mahieu, L. et al. Evaluating single-cell ATAC-seq atlasing technologies using sequence-to-function modeling. Nat Commun 17, 1951 (2026). https://doi.org/10.1038/s41467-026-68742-4
Parole chiave: single-cell ATAC-seq, enhancer, modelli di deep learning, regolazione genica, genomica open-source