Clear Sky Science · it
Progressi e sfide nell'archiviazione dei dati con acidi nucleici non canonici
Perché ha senso conservare dati nelle molecole
Ogni foto, messaggio e filmato che creiamo deve essere conservato da qualche parte, e oggi quel “da qualche parte” sono per lo più enormi magazzini di unità disco che consumano molta elettricità e si usurano nel giro di decenni. Questo articolo esplora un approccio molto diverso: utilizzare molecole genetiche appositamente progettate come nastri dati microscopici. Modificando i mattoni familiari di DNA e RNA, gli scienziati puntano a creare sistemi di archiviazione più densi, più resistenti e più sicuri di qualsiasi chip di silicio o disco magnetico.
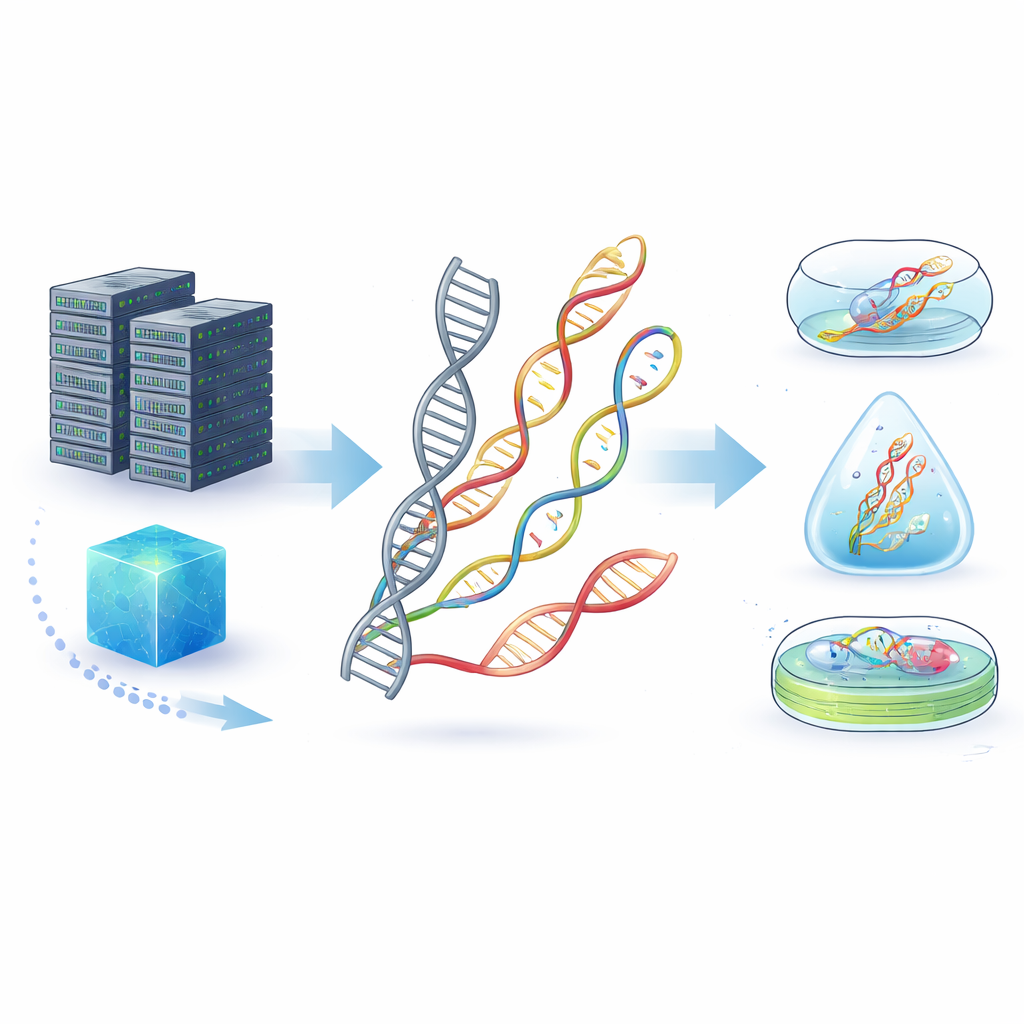
Dal DNA fragile a nuove molecole resistenti
Il DNA naturale è già un supporto di memorizzazione impressionante, capace di immagazzinare enormi quantità di informazione in uno spazio microscopico e di sopravvivere per decine di migliaia di anni nei fossili. Ma nelle condizioni quotidiane—calore, umidità, sostanze chimiche esterne o enzimi che degradano il DNA—può deteriorarsi rapidamente. Gli autori presentano gli “acidi nucleici non canonici” (ncNA): molecole simili al DNA e all’RNA le cui basi, zuccheri o spina dorsale sono state alterate chimicamente, o addirittura specchiate, per conferirgli nuove proprietà. Queste modifiche possono rendere le molecole più difficili da degradare per gli enzimi, più resistenti ad acidi o basi e migliori nel sopravvivere a condizioni avverse rispetto al DNA ordinario.
Aggiungere nuove lettere all’alfabeto genetico
Una delle idee più potenti della rassegna è espandere l’alfabeto genetico oltre le quattro lettere usuali A, T, G e C. I chimici hanno creato coppie di basi aggiuntive che si integrano nelle doppie eliche pur non essendo presenti in natura. Con 8, 12 o più lettere a disposizione, ogni posizione sulla catena può codificare più bit di informazione, aumentando la capacità di archiviazione ben oltre quanto offerto dal DNA standard. Alcune di queste nuove basi sono progettate per associarsi tramite interazioni idrofobiche invece dei consueti legami a idrogeno, dimostrando che le regole naturali di appaiamento possono essere piegate pur mantenendo l’informazione leggibile.
Ricostruire lo scheletro molecolare
Oltre a cambiare le “lettere”, i ricercatori ridisegnano anche lo zucchero e la spina dorsale che tengono insieme una catena genetica. Sostituire lo zucchero usuale con alternative come la treosio o l’esitolo, o rimpiazzare i legami fosfato caricati con legami neutri o contenenti zolfo, può modificare drasticamente il comportamento della catena. Molti di questi ncNA mostrano una stabilità sorprendente in condizioni di calore, acidità o ricche di enzimi dove il DNA naturale si disintegrerebbe rapidamente. Alcune versioni a immagine speculare, come l’L-DNA, sono invisibili agli enzimi normali e alle difese immunitarie, rendendole promettenti per l’archiviazione estremamente sicura e per messaggi nascosti, sebbene attualmente siano difficili e costose da sintetizzare e leggere.
Come i dati vengono scritti, conservati e letti
La trasformazione di file digitali in forma molecolare segue un ciclo in quattro fasi: codifica, scrittura, conservazione e lettura. I bit vengono prima tradotti in sequenze o strutture, che vengono poi sintetizzate come filamenti di ncNA mediante metodi chimici o enzimi appositamente ingegnerizzati. Questi filamenti possono essere conservati al di fuori delle cellule—incapsulati in vetro, silice o polimeri—o all’interno di cellule e persino di piante modificate, dove la macchina di riparazione naturale può contribuire a mantenerli. La lettura dei dati può avvenire con macchine per il sequenziamento del DNA familiari, dispositivi avanzati a nanopori che “percepisco” ogni unità mentre passa attraverso un buco microscopico, o microscopi che riconoscono forme in nanostrutture ripiegate. Poiché molti ncNA non possono ancora essere sequenziati direttamente, spesso vengono convertiti nuovamente in DNA normale prima della lettura, una fase che la ricerca attuale sta cercando di snellire e migliorare.
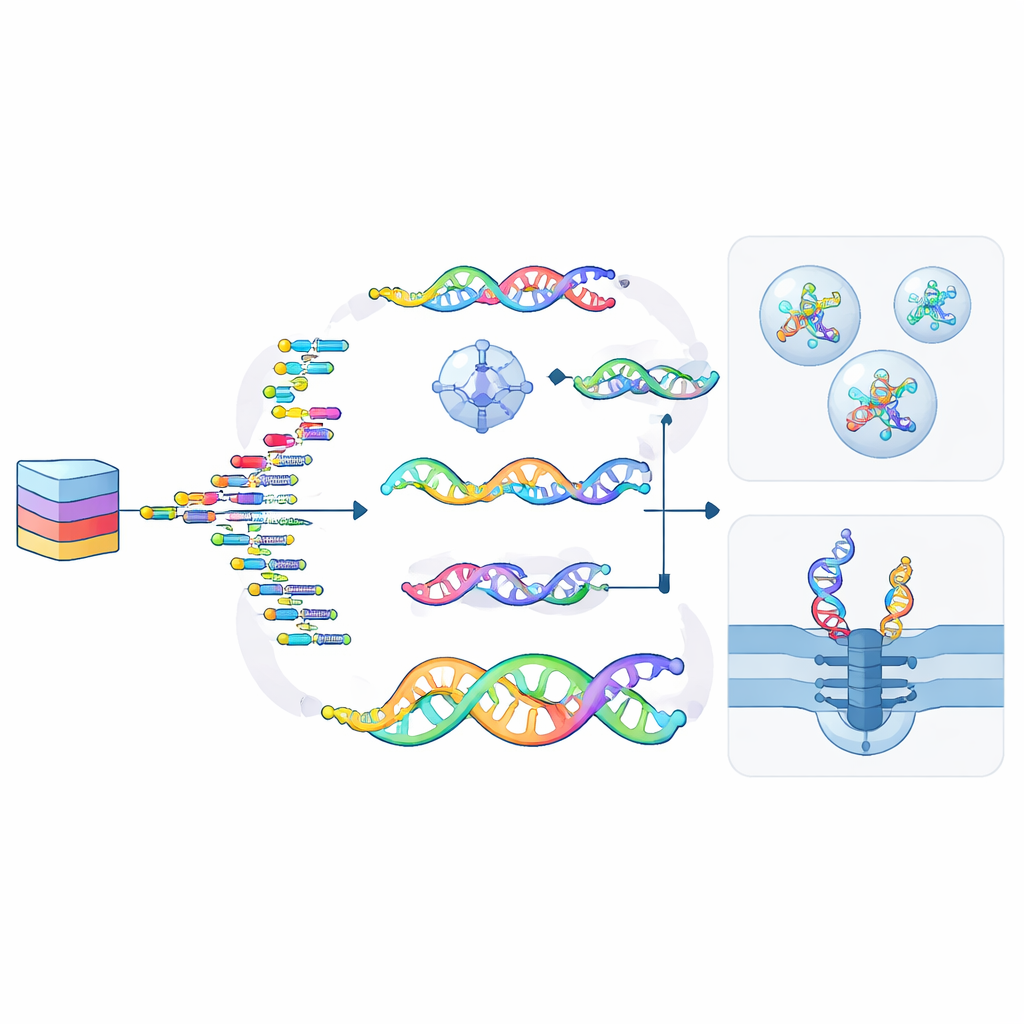
Nuove possibilità: calcolo, sicurezza e scrittura parallela
L’articolo sottolinea come gli ncNA facciano più che immagazzinare dati—possono anche elaborarli. Circuiti logici basati su DNA e reti neurali esistono già, e aggiungere alfabeti chimicamente distinti facilita l’esecuzione di molte operazioni in parallelo senza interferenze indesiderate. Alcune modifiche agiscono come inchiostro invisibile, permettendo di nascondere informazioni all’interno di filamenti o strutture che solo enzimi o condizioni particolari possono rivelare. Altre, come addotti chimici reversibili o pattern di gruppi metile, si comportano come caratteri mobili su una macchina da stampa: possono imprimere dati su filamenti esistenti in parallelo, cancellarli e riscriverli senza ricostruire l’intera molecola da zero.
Sfide future e cosa significherebbe il successo
Nonostante le promesse, gli autori sottolineano che l’archiviazione su acidi nucleici non canonici è ancora a uno stadio iniziale. Realizzare filamenti lunghi e privi di errori è costoso e tecnicamente complesso, e molte delle chimiche più interessanti non sono ancora compatibili con tecnologie di lettura veloci e a basso costo. Ci sono anche importanti questioni di sicurezza ed etiche sull’introduzione di molecole altamente stabili e parzialmente non naturali nei sistemi viventi. Ciononostante, la rassegna delinea una tabella di marcia in cui una sintesi più rapida, incapsulamenti più intelligenti e lettori a nanopori potenziati dall’intelligenza artificiale potrebbero rendere praticabile l’archiviazione basata su ncNA nelle prossime decadi. Se ciò avverrà, potremmo un giorno eseguire il backup della nostra civiltà digitale non su dischi rotanti, ma su minuscoli e robusti filamenti di molecole progettate.
Citazione: Wang, Y., Pei, Y., Tang, L. et al. Advances and challenges in non-canonical nucleic acids data storage. Nat Commun 17, 2354 (2026). https://doi.org/10.1038/s41467-026-68708-6
Parole chiave: archiviazione dati su DNA, acidi nucleici non canonici, memoria molecolare, coppie di basi non naturali, sequenziamento nanopore