Clear Sky Science · it
Acceleratori neurali nanofotonici progettati per via inversa per il calcolo ottico ultra‑compatto
Perché è importante miniaturizzare i computer fatti di luce
L’intelligenza artificiale moderna gira su vasti hardware elettronici che consumano enormi quantità di energia e generano calore. Questo studio esplora una strada molto diversa: usare microstrutture di luce su chip, invece di flussi di elettroni, per eseguire parti del calcolo delle reti neurali. Gli autori dimostrano che «scolpendo» la luce su scala nanometrica è possibile costruire acceleratori ottici ultra‑compatti che riconoscono cifre scritte a mano e immagini mediche usando molto meno spazio e, in linea di principio, molta meno energia rispetto all’elettronica odierna.
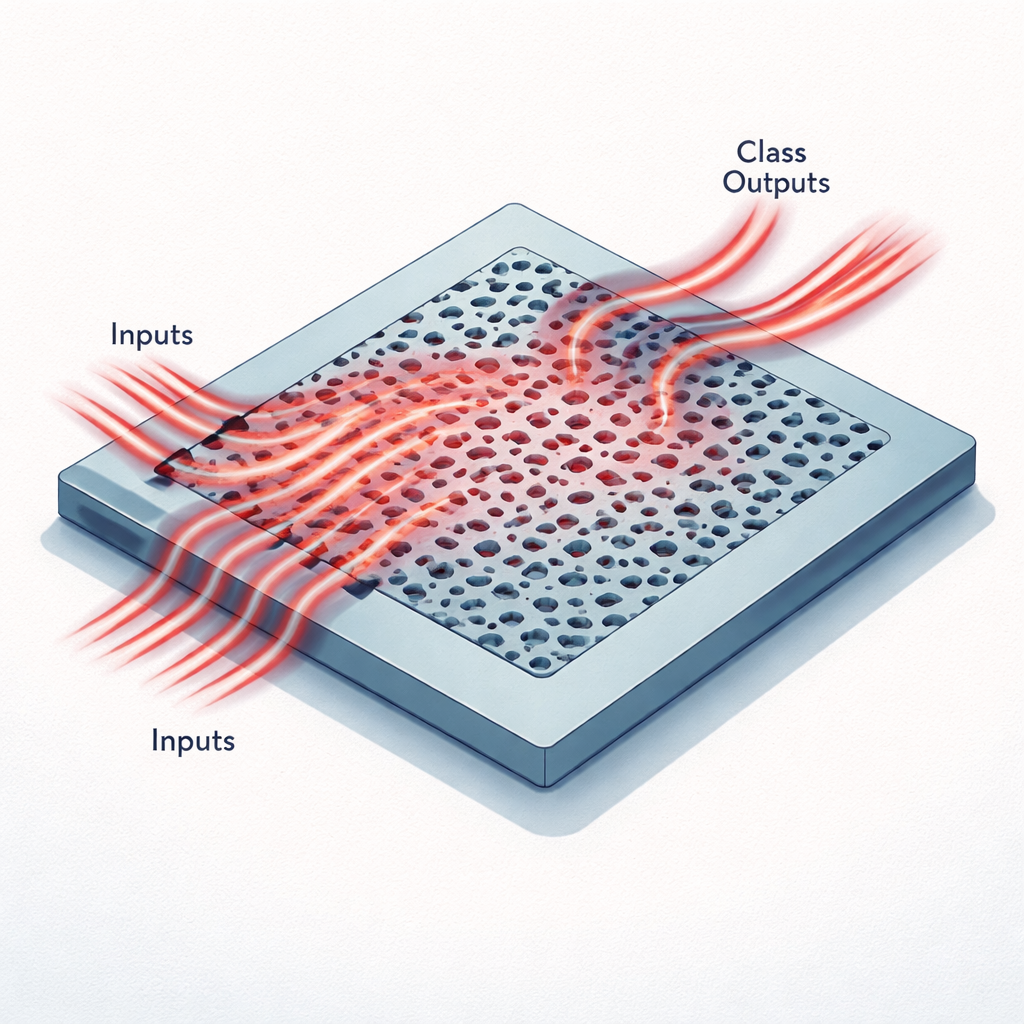
Chip minuscoli che pensano con la luce
Al posto di fili e transistor, questi acceleratori usano una lastra di silicio piatta modellata con fori e canali più piccoli della lunghezza d’onda della luce infrarossa. I dati di un’immagine vengono prima compressi in un piccolo insieme di numeri, poi codificati come intensità della luce che entra in diversi guide d’onda strette a una singola lunghezza d’onda telecom. Mentre questa luce attraversa la regione modulata, viene dispersa, interferisce con se stessa e viene deviata verso alcune guide d’onda di uscita. Ciascuna uscita corrisponde a una possibile classe, come una delle dieci cifre del dataset MNIST o una delle sei categorie nel set di immagini mediche MedNIST. Il pattern di potenza ottica alle uscite assume lo stesso ruolo dell’ultimo strato di una rete neurale digitale.
Lasciare che siano gli algoritmi a disegnare il progetto ottico
Progettare a mano una struttura del genere sarebbe praticamente impossibile, perché ogni minuscolo «voxel» di materiale può cambiare il comportamento della luce. I ricercatori usano invece un approccio di progettazione inversa: partono da un pattern casuale di silicio e vetro, simulano come la luce si propaga in tre dimensioni e poi aggiustano la geometria per ridurre una funzione di perdita che misura gli errori di classificazione. Sfruttano la linearità delle equazioni di Maxwell — le leggi che governano la luce — per rendere efficiente questo addestramento. Piuttosto che simulare ogni immagine di training separatamente, simulano ogni canale di ingresso una sola volta e poi ricostruiscono i campi per tutte le immagini come combinazioni lineari di questi campi precalcolati. Una tecnica matematica chiamata metodo aggiunto fornisce quindi gradienti esatti che dicono all’algoritmo come modificare ogni voxel per migliorare le prestazioni.

Classificatori di immagini compatti come un granello di sabbia
Con questa strategia, il team ha progettato due acceleratori neurali nanofotonici su una piattaforma standard silicon‑on‑insulator. Uno, di appena 20 per 20 micrometri, classifica cifre scritte a mano dal dataset MNIST; l’altro, 30 per 20 micrometri, classifica immagini mediche da MedNIST. Nelle simulazioni, questi minuscoli dispositivi hanno raggiunto accuratezze rispettivamente del 97,8% e del 99,1%. Le versioni fabbricate degli stessi progetti, testate con laser e rivelatori reali, hanno raggiunto l’89% di accuratezza per MNIST e il 90% per MedNIST — valori notevoli data la dimensione minima dei chip. Le strutture ottiche contengono grosso modo tra 160.000 e 240.000 parametri allenabili in aree più piccole di un granello di polvere, corrispondenti a circa 400 milioni di parametri per millimetro quadrato.
Progettati per velocità, efficienza e scalabilità
Poiché i dispositivi sono passivi — non ci sono parti mobili o elementi riprogrammabili durante l’inferenza — non necessitano di una sintonizzazione continua una volta fabbricati. I «pesi» della rete neurale sono incorporati nella geometria della nanostruttura, quindi il calcolo avviene alla velocità della luce con un’elaborazione essenzialmente in memoria: la luce entra con i dati codificati ed esce già miscelata in punteggi di classe. Anche il metodo di addestramento è progettato per essere scalabile. Ogni passo di ottimizzazione richiede solo un numero fisso di simulazioni full‑physics determinato dal numero di ingressi e uscite, non dalla dimensione del dataset, e queste simulazioni possono essere distribuite su più unità di elaborazione grafica. Gli autori descrivono inoltre come più di questi core ottici possano essere impilati con fotodetettori tra di essi, proprio come strati in una rete neurale profonda, e come il multiplexing in lunghezza d’onda o nel tempo possa aumentare la capacità di elaborazione.
Cosa significa per l’hardware dell’IA del futuro
In termini semplici, questo lavoro dimostra che è possibile «far crescere» pezzi su misura di vetro e silicio che si comportano come layer specializzati di reti neurali, il tutto entro un’area abbastanza piccola da ospitare centinaia o migliaia di essi su un singolo chip. Pur essendo i computer ottici completi ancora all’orizzonte, questi acceleratori nanofotonici progettati per via inversa potrebbero scaricare alcune delle parti più energivore dei carichi di lavoro IA dai processori elettronici. Se combinati con modulatori veloci, rivelatori e un design di sistema intelligente, indicano la strada verso hardware compatti e a basso consumo in cui la luce, più che l’elettricità da sola, svolge gran parte del lavoro pesante nell’apprendimento automatico.
Citazione: Sved, J., Song, S., Li, L. et al. Inverse-designed nanophotonic neural network accelerators for ultra-compact optical computing. Nat Commun 17, 1059 (2026). https://doi.org/10.1038/s41467-026-68648-1
Parole chiave: reti neurali fotoniche, nanofotonica, calcolo ottico, acceleratori hardware, progettazione inversa