Clear Sky Science · it
Confronto completo di metodi per punteggi poligenici a singola e multi-ancestralità con la piattaforma PGS-hub
Perché il tuo punteggio di rischio genetico conta
I medici stanno diventando più abili nel leggere il nostro DNA per stimare chi è più probabile che sviluppi malattie comuni come malattie cardiache, diabete o schizofrenia. Queste stime, chiamate punteggi poligenici, combinano i piccoli effetti di molte varianti genetiche in un singolo numero. Esistono però oggi molte modalità concorrenti per calcolare tali punteggi, e non tutte funzionano allo stesso modo per persone di origini ancestrali diverse. Questo studio si è posto l’obiettivo di confrontare i metodi principali testa a testa e di creare un servizio online, PGS-hub, che permetta ai ricercatori di calcolare questi punteggi in modo coerente e semplice.
Un unico punto di riferimento per i calcolatori di rischio genetico
Gli autori hanno creato PGS-hub, una piattaforma web che nasconde gran parte della complessità tecnica dietro i punteggi poligenici. Gli utenti caricano i risultati degli studi genetici che riassumono come milioni di marcatori del DNA siano associati a una malattia o a un tratto. Poi scelgono lo sfondo ancestrale della popolazione di interesse — per esempio europeo o africano — e selezionano da un menu i metodi di scoring più diffusi. Dietro le quinte, PGS-hub converte l’input nei formati corretti, utilizza pannelli di riferimento precompilati che descrivono come i marcatori vicini del DNA siano correlati e lancia numerosi job su un sistema di calcolo ad alte prestazioni. L’output è un file compatto di pesi che può essere applicato ai singoli genomi per generare un punteggio per ciascuna persona. 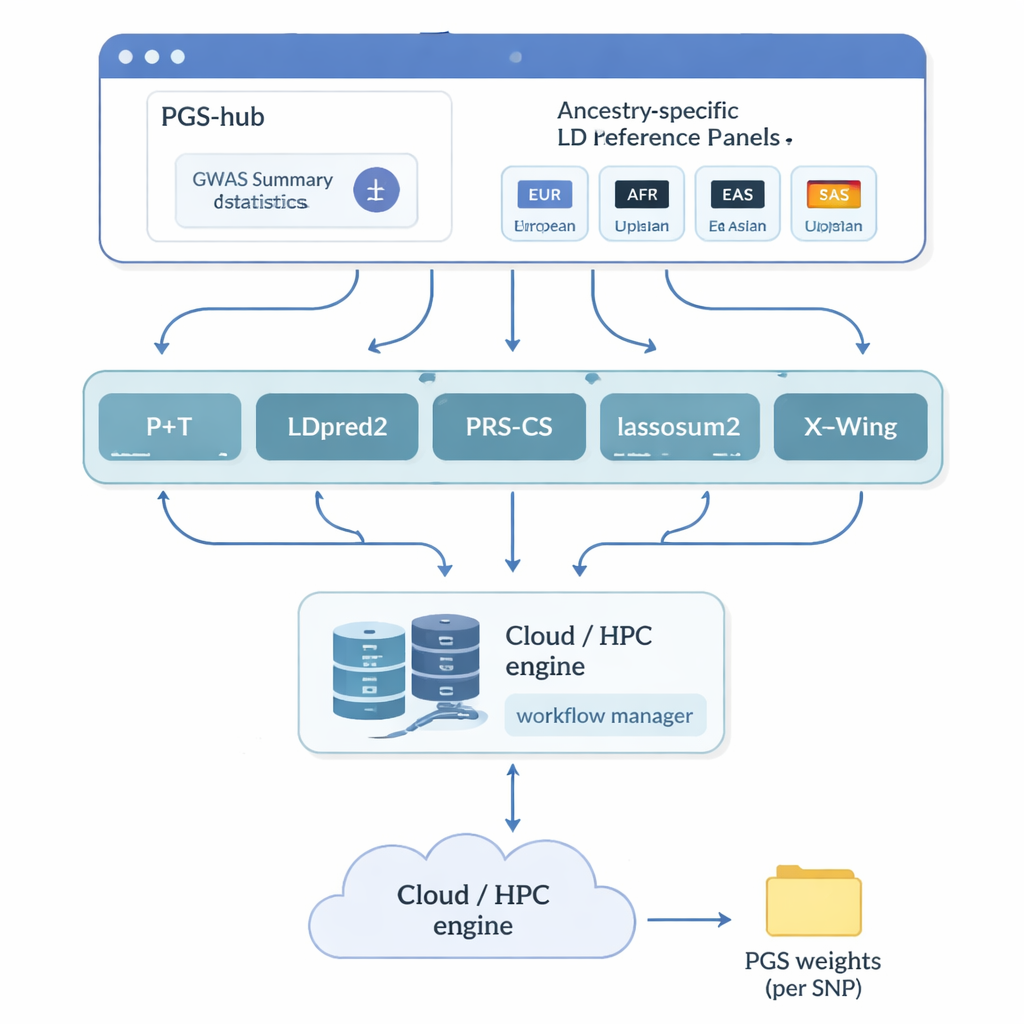
Mettere alla prova 13 metodi di scoring
Per valutare quali approcci funzionano meglio, il team ha confrontato 13 metodi all’avanguardia su 36 malattie e tratti in quasi 380.000 persone di ascendenza europea e poco più di 8.000 persone di ascendenza africana provenienti dall’UK Biobank. Hanno valutato non solo quanto bene ciascun punteggio predicesse chi aveva una malattia o un valore più alto di un tratto, ma anche quanta potenza di calcolo e memoria ciascun metodo richiedeva. Negli europei, un metodo chiamato LDpred2 ha generalmente fornito i punteggi più accurati, spesso superando gli altri con un margine netto. Alcune alternative — lassosum2, PRS‑CS e SDPR — hanno reso quasi altrettanto bene per molti tratti, mentre metodi più datati sono rimasti indietro. Per tratti come l’altezza o il morbo di Crohn, i migliori punteggi spiegavano una quota consistente del rischio genetico; per altri, come la funzione renale, tutti i metodi hanno faticato, riflettendo segnali genetici di base più deboli.
Indicazioni per popolazioni diverse e metodi combinati
Un tema centrale nella predizione genetica è che i metodi addestrati principalmente su popolazioni europee potrebbero non trasferirsi bene a persone con ancestrie diverse. Quando gli autori hanno ripetuto i benchmark usando studi genetici di soggetti di ascendenza africana, ogni metodo ha reso peggio, evidenziando la carenza di grandi studi in queste popolazioni. Tuttavia, LDpred2 e SDPR tendevano comunque a essere tra le opzioni migliori. Il team ha anche esaminato approcci “multi-ancestrali” che combinano esplicitamente informazioni tra popolazioni. Qui, una strategia relativamente semplice — combinare linearmente i migliori punteggi specifici per ciascuna ancestria derivati da LDpred2 in un singolo punteggio LDpred2-multi — ha superato modelli multi-ancestrali più elaborati come PRS‑CSx e X‑Wing sia per i gruppi europei sia per quelli africani. Inoltre, gli autori hanno mostrato che costruire un ensemble, che mescola i punteggi più forti provenienti da più metodi, migliorava ulteriormente la predizione su tutti i tratti, specialmente per malattie altamente ereditabili come la schizofrenia e la malattia coronarica. 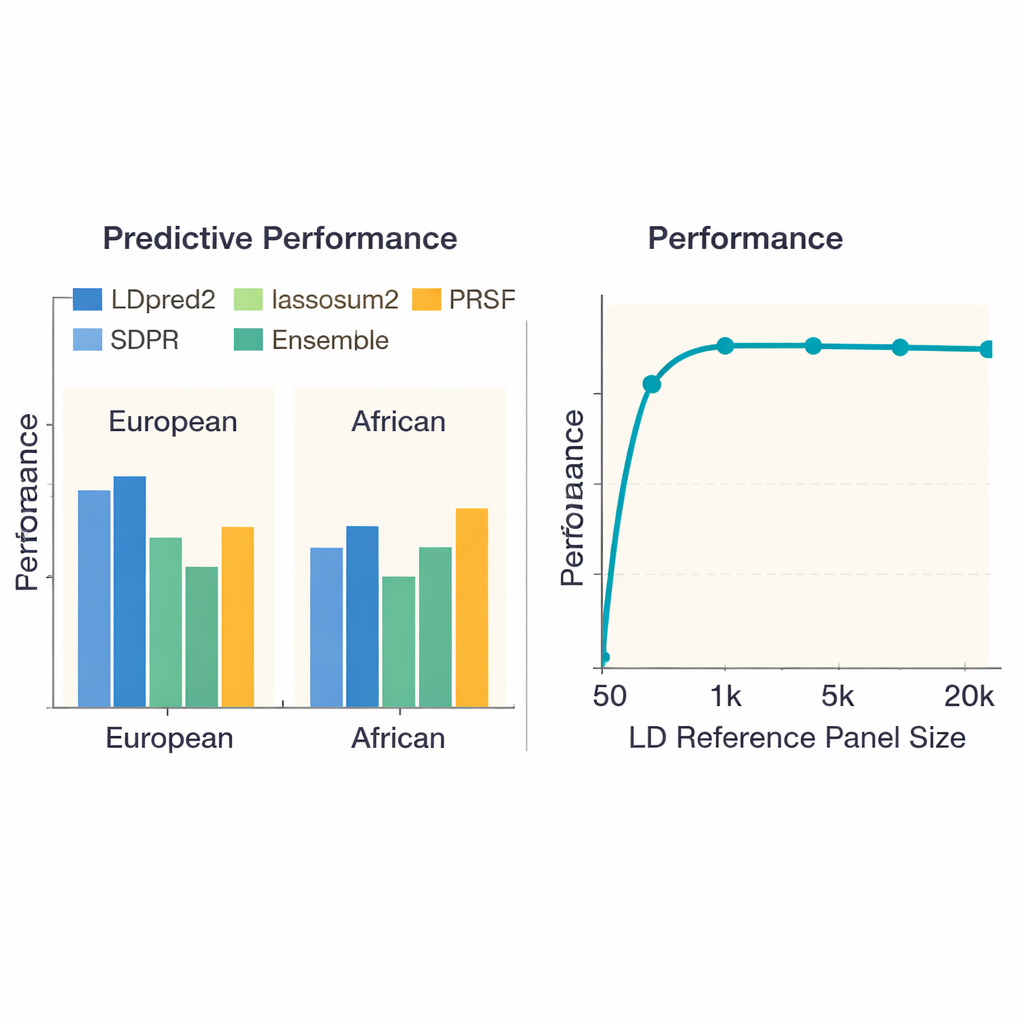
Come le scelte sui dati e i limiti di calcolo plasmano i punteggi
Lo studio ha indagato come la dimensione del pannello di riferimento — il gruppo di persone usato per apprendere come i marcatori vicini del DNA covariano — influisca sulle prestazioni. Quando questo pannello era molto piccolo (meno di 1.000 individui), i punteggi risultavano visibilmente meno accurati. Con un pannello di circa 5.000 persone le prestazioni miglioravano nettamente per poi stabilizzarsi, suggerendo che pannelli sempre più grandi producono rendimenti marginali decrescenti. Sorprendentemente, inserire semplicemente più marcatori del DNA non ha sempre aiutato: usare circa 6,6 milioni di varianti a volte peggiorava le predizioni rispetto a usare un insieme ben selezionato di circa 1,1 milioni, probabilmente perché i marcatori extra introducevano più rumore che segnale utile. Gli autori hanno anche documentato grandi differenze nei costi computazionali. Metodi semplici come il pruning-and-thresholding di base terminavano in meno di un’ora per tratto, mentre alcuni approcci bayesiani richiedevano centinaia di ore CPU, informazione rilevante per progetti su larga scala o gruppi con risorse limitate.
Cosa significa questo per il futuro della predizione basata sul DNA
Per i non specialisti, il messaggio principale è che non tutti i punteggi di rischio genetico sono uguali, e i dettagli della loro costruzione influenzano fortemente chi può beneficiarne. Questo lavoro offre indicazioni pratiche: metodi come LDpred2 e ensemble ben progettati tendono a fornire le predizioni più affidabili nei grandi dataset europei, e le combinazioni multi‑ancestrali possono superare modelli cross‑popolazione più complessi. Allo stesso tempo, la perdita di accuratezza per gli individui di ascendenza africana sottolinea l’urgenza di studi genetici più numerosi e più diversificati. Impacchettando molti metodi in un’unica piattaforma online standardizzata, PGS-hub abbassa la barriera per ricercatori di tutto il mondo nel generare e confrontare punteggi poligenici, passo importante verso un uso più equo ed efficace di tali punteggi in medicina.
Citazione: Chen, X., Wang, F., Zhao, H. et al. Comprehensive benchmarking single and multi ancestry polygenic score methods with the PGS-hub platform. Nat Commun 17, 2014 (2026). https://doi.org/10.1038/s41467-026-68599-7
Parole chiave: punteggi poligenici, predizione del rischio genetico, piattaforma PGS-hub, genomica multi-ancestrale, UK Biobank