Clear Sky Science · it
Un modello linguistico genomico attenua artefatti chimerici nel sequenziamento diretto dell’RNA con nanopore
Perché è importante pulire le letture di RNA
Le nostre cellule leggono continuamente le istruzioni genetiche codificate nell’RNA, e le nuove tecnologie di sequenziamento permettono ora agli scienziati di osservare questo processo con un dettaglio senza precedenti. Uno degli strumenti più potenti, il sequenziamento diretto dell’RNA con nanopore, può leggere intere molecole di RNA in una singola passata—ma introduce anche errori che possono far sembrare i geni spezzati e ricombinati in modi che non avvengono nella realtà. Questo studio presenta DeepChopper, un software che funziona come un modello linguistico per il genoma, correggendo questi errori affinché i ricercatori possano fidarsi dei dati di RNA.
Quando il sequenziatore inventa fusioni geniche false
Le moderne macchine nanopore trascinano singoli filamenti di RNA attraverso pori minuscoli e ne leggono la sequenza direttamente. Questo offre grandi vantaggi rispetto ai metodi precedenti, come la conservazione delle modificazioni chimiche e la cattura di trascritti a lunghezza intera in una sola lettura. Ma il processo si basa anche su brevi frammenti di aiuto chiamati adattatori, che vengono incollati alle molecole di RNA durante la preparazione delle librerie. Talvolta, due o più molecole di RNA vengono accidentalmente unite tramite questi adattatori, creando apparenti chimere—molecole ibride che sembrano fondere geni diversi. Gli strumenti di analisi standard possono interpretare erroneamente questi residui tecnici come eventi biologici reali, come fusioni geniche correlate al cancro o modelli di splicing insoliti, portando a risultati fuorvianti.
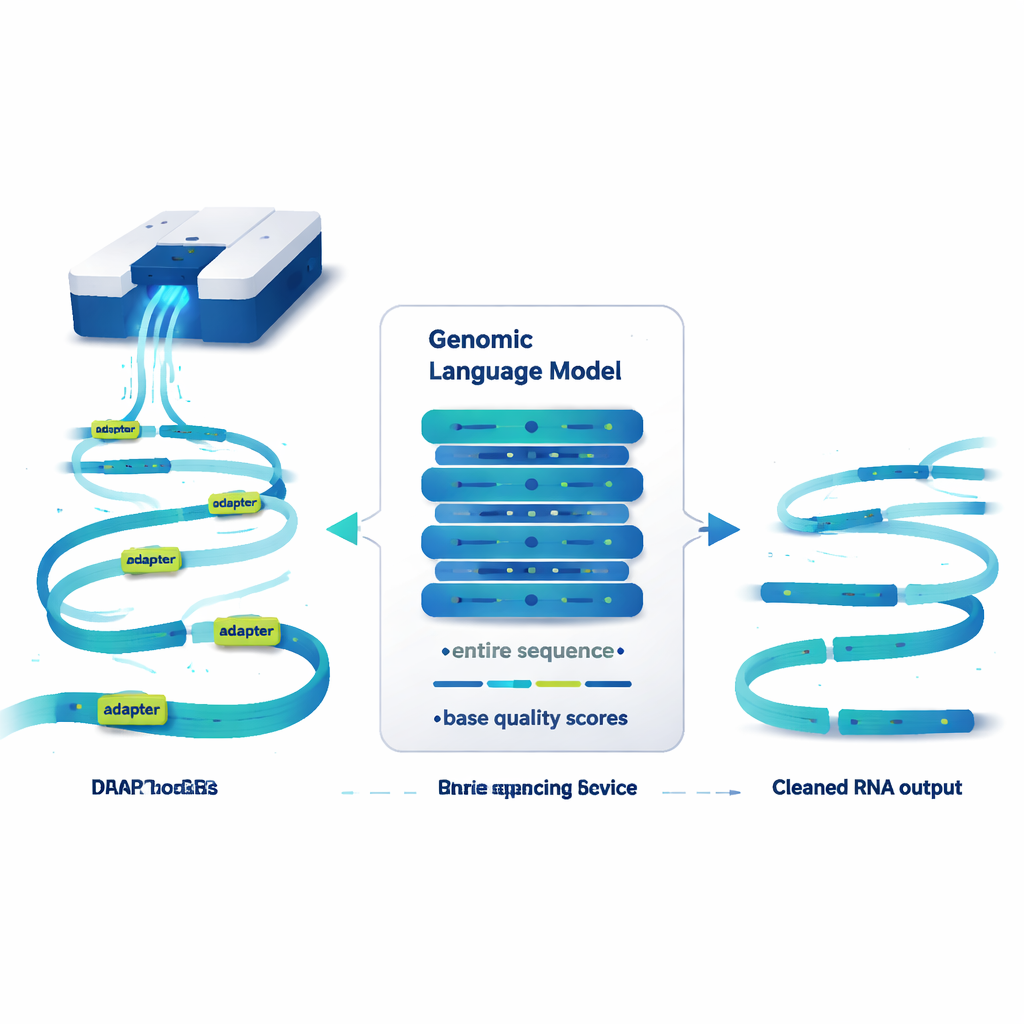
Un modello linguistico che legge genomi, non frasi
DeepChopper tratta le sequenze genetiche un po’ come se fossero testo e applica idee provenienti dai grandi modelli linguistici. Invece di parole, legge le sequenze di RNA una lettera alla volta, insieme a un punteggio di qualità per ogni lettera che indica quanto sia affidabile la lettura. Costruito su un’architettura compatta chiamata HyenaDNA, può scandire fino a 32.000 basi in una volta—abbastanza da coprire di fatto qualsiasi RNA umano. Per ogni singola posizione, DeepChopper stima se quella base faccia parte di una sequenza di RNA genuina o di un adattatore. Un passaggio di raffinamento poi smussa queste previsioni in modo che gli adattatori siano marcati come blocchi continui anziché come spot sparsi.
Eliminare le giunzioni errate senza buttare via i dati
Una volta che DeepChopper individua gli adattatori all’interno di una lettura, fa qualcosa di cruciale: invece di scartare l’intera lettura, la “taglia” in corrispondenza di quei siti di adattatore e conserva i frammenti reali. In questo modo, una fusione artificiale di due RNA può essere ricomposta nelle sue parti originali. Nei test su milioni di letture nanopore provenienti da diverse linee cellulari tumorali umane e cellule staminali, DeepChopper ha largamente superato gli strumenti esistenti per la rimozione degli adattatori, che non erano stati progettati per questo contesto di RNA diretto. Ha riconosciuto correttamente gli adattatori con oltre il 99% di precisione e richiamo sui benchmark sintetici, e si è scalato in modo efficiente a dataset con più di 20 milioni di letture utilizzando processori grafici.
Separare le vere fusioni geniche dai miraggi di sequenziamento
Gli autori hanno quindi verificato se DeepChopper potesse distinguere eventi biologici genuini dagli artefatti nei dati reali sul cancro. Confrontando letture di RNA diretto con dataset corrispondenti prodotti da metodi indipendenti (come il sequenziamento di cDNA diretto su piattaforme Oxford Nanopore e PacBio), hanno potuto etichettare quali apparenti chimere erano sostenute da altre tecnologie e quali no. DeepChopper ha ridotto gli allineamenti chimerici non supportati fino al 62–91%, arricchendo al contempo la frazione confermata da altri metodi. Ha anche ridotto di quasi il 90% il numero di chiamate sospette di fusione genica, in particolare quelle che coinvolgevano geni ribosomiali che si sono rivelati artefatti frequenti. Allo stesso tempo, gli eventi di fusione veri supportati dal sequenziamento short-read sono stati preservati.
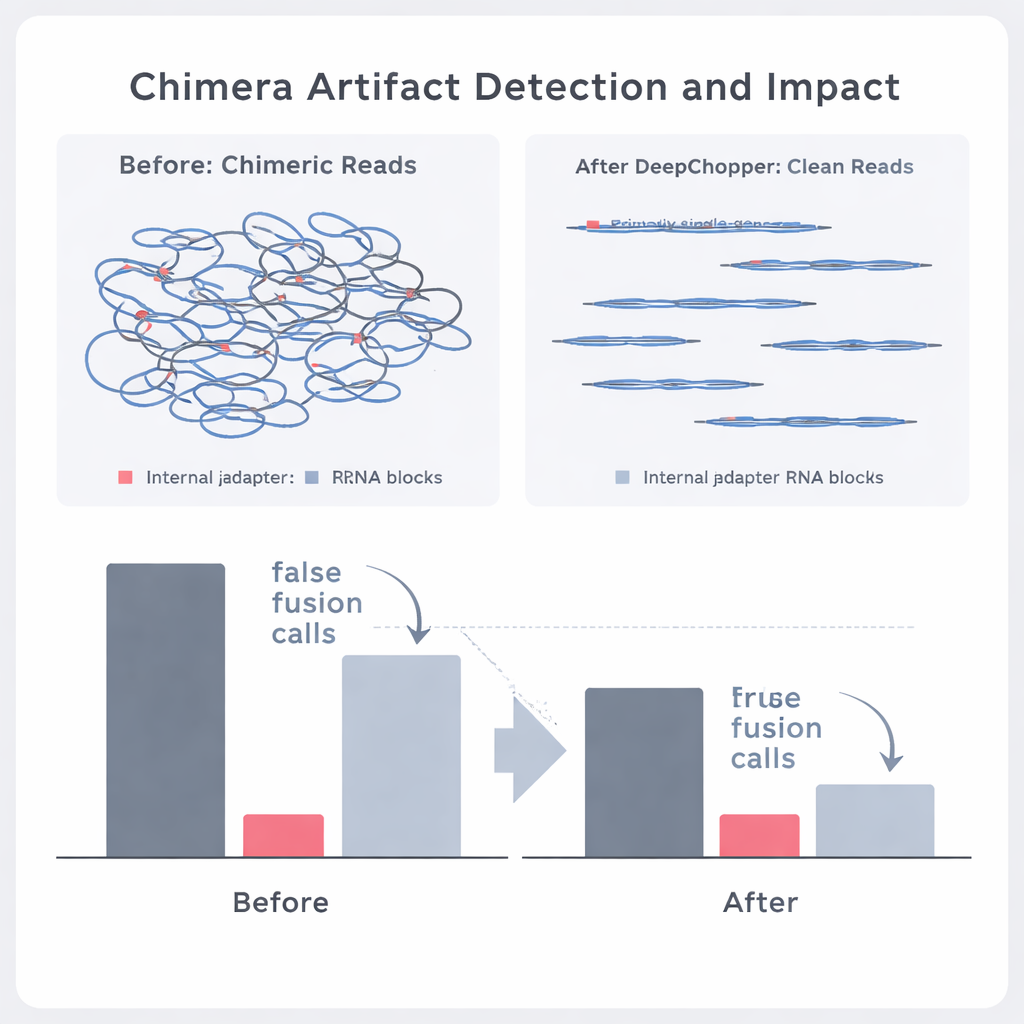
Una chimica migliore aiuta—ma gli artefatti restano
Oxford Nanopore ha recentemente rilasciato un kit di sequenziamento aggiornato (RNA004) progettato in parte per ridurre gli artefatti tecnici. DeepChopper è stato applicato “out of the box” ai dati generati con questa nuova chimica e ha comunque rilevato che una frazione piccola ma significativa di letture conteneva adattatori interni e giunzioni chimeriche. Anche senza ulteriore addestramento, il modello ha ridotto le chimere artifatte di circa un quinto; dopo un fine-tuning sui nuovi dati ha reso leggermente meglio, preservando sempre i segnali genuini. Attraverso tutte le chimiche e i tipi cellulari, correggere questi artefatti ha permesso agli strumenti a valle di rilevare molte più isoforme a lunghezza intera e trascritti alternativi, offrendo una visione più chiara del paesaggio dell’RNA cellulare.
Cosa significa per i futuri studi sull’RNA
Per i non specialisti, il messaggio chiave è che non ogni collegamento sorprendente tra RNA segnalato da un sequenziatore corrisponde a biologia reale—alcuni sono errori introdotti dalla tecnologia stessa. DeepChopper agisce come un correttore di bozze altamente addestrato per i dati RNA nanopore, individuando le sequenze di adattatori che uniscono molecole non correlate e rimuovendole con precisione a livello di singola base. Il risultato sono mappe più pulite e affidabili di quali molecole di RNA esistono in una cellula e di come sono assemblate. Poiché i laboratori si affidano sempre più al sequenziamento long-read dell’RNA per studiare il cancro, i disturbi cerebrali e altre malattie complesse, strumenti come DeepChopper saranno essenziali per trasformare letture grezze rumorose in conoscenze biologiche attendibili.
Citazione: Li, Y., Wang, TY., Guo, Q. et al. Genomic language model mitigates chimera artifacts in nanopore direct RNA sequencing. Nat Commun 17, 1864 (2026). https://doi.org/10.1038/s41467-026-68571-5
Parole chiave: sequenziamento dell’RNA con nanopore, letture chimeriche, artefatti di fusione genica, modello linguistico genomico, DeepChopper