Clear Sky Science · it
Tre questioni aperte sulla trasferibilità dei punteggi poligenici
Perché prevedere la salute dal DNA è più difficile di quanto sembri
I medici e i ricercatori sperano sempre più di usare i «punteggi poligenici» basati sul DNA per prevedere il rischio di condizioni comuni come il diabete, le malattie cardiache o l’asma. Ma questi punteggi spesso funzionano bene soltanto nelle persone che somigliano ai volontari dello studio originale, solitamente di ascendenza europea. Questo articolo indaga perché queste predizioni non «viaggiano» in modo affidabile verso persone con contesti genetici o di vita diversi, e cosa ciò comporta per un uso equo dei punteggi genetici nella medicina.
Cosa promettono i punteggi poligenici — e dove non bastano
I punteggi poligenici combinano i minuscoli effetti di molte varianti genetiche su tutto il genoma in un unico numero pensato per predire un carattere, come l’altezza o la pressione arteriosa. Sono costruiti a partire da grandi studi di associazione genome-wide (GWAS) che collegano marcatori del DNA a tratti in centinaia di migliaia di volontari. Tuttavia, quando questi punteggi vengono applicati a nuovi gruppi di persone, la loro accuratezza varia drasticamente. Tipicamente, la predizione peggiora quanto più il nuovo gruppo differisce geneticamente o socialmente dai partecipanti del GWAS originale. Questo è noto come problema di trasferibilità: un punteggio che funziona in un contesto può fuorviare in un altro, potenzialmente approfondendo le disuguaglianze di salute se usato senza cautela.
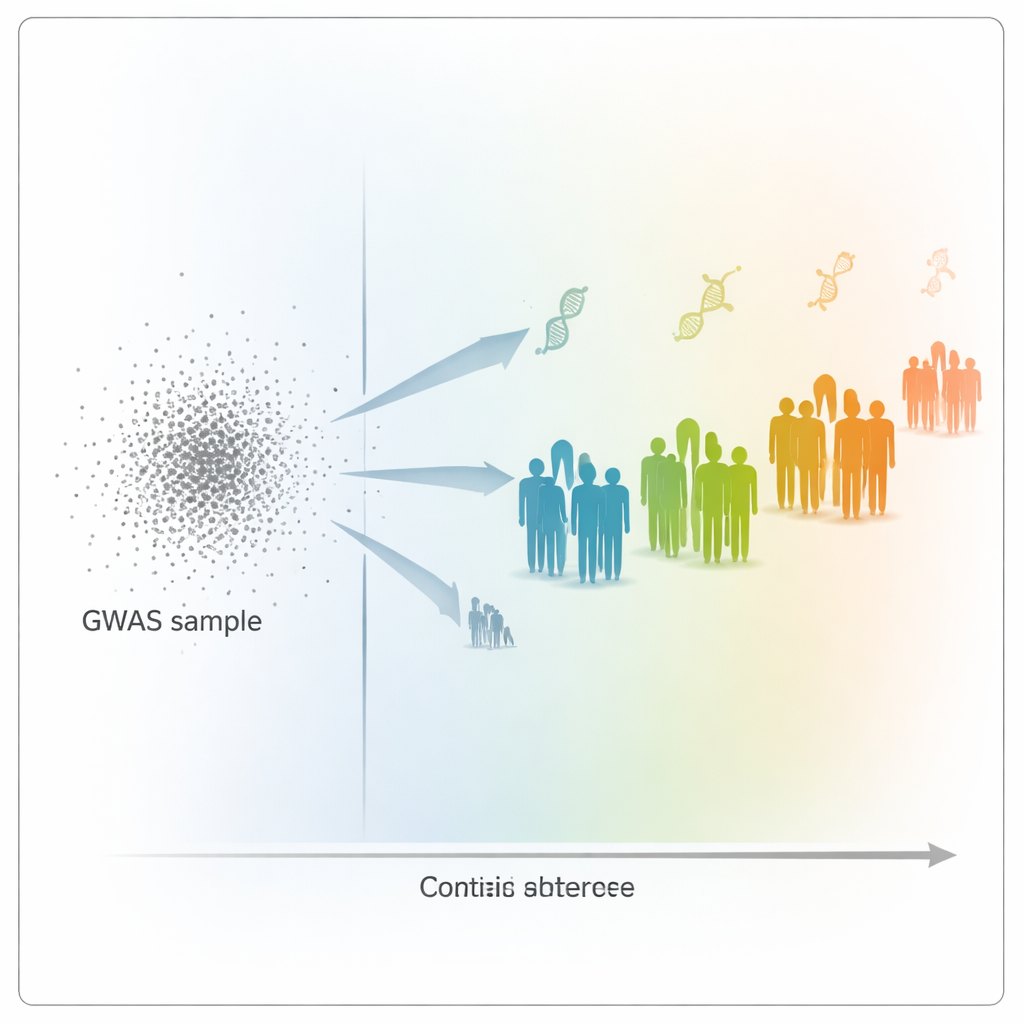
Oltre l’ascendenza: distanza sulla mappa genetica
Per indagare il problema, gli autori hanno usato i dati dell’UK Biobank, che includono informazioni genetiche e sanitarie di oltre 400.000 persone. Hanno costruito punteggi poligenici per 15 tratti altamente ereditabili, come altezza, peso, conteggi delle cellule del sangue e livelli di colesterolo, basandosi su un ampio gruppo di partecipanti prevalentemente britannici bianchi. Poi hanno testato quanto bene questi punteggi predicessero i tratti in 69.500 altri partecipanti, che spaziavano su un ampio spettro di origini genetiche. Invece di assegnare le persone a grandi categorie di ascendenza, il team ha collocato ogni individuo lungo una scala continua di «distanza genetica»: quanto il profilo del DNA di ciascuno si discostava dalla media dei volontari del GWAS quando proiettato in una mappa genetica basata su componenti principali.
Il potere predittivo svanisce — ma non in modi semplici o equi
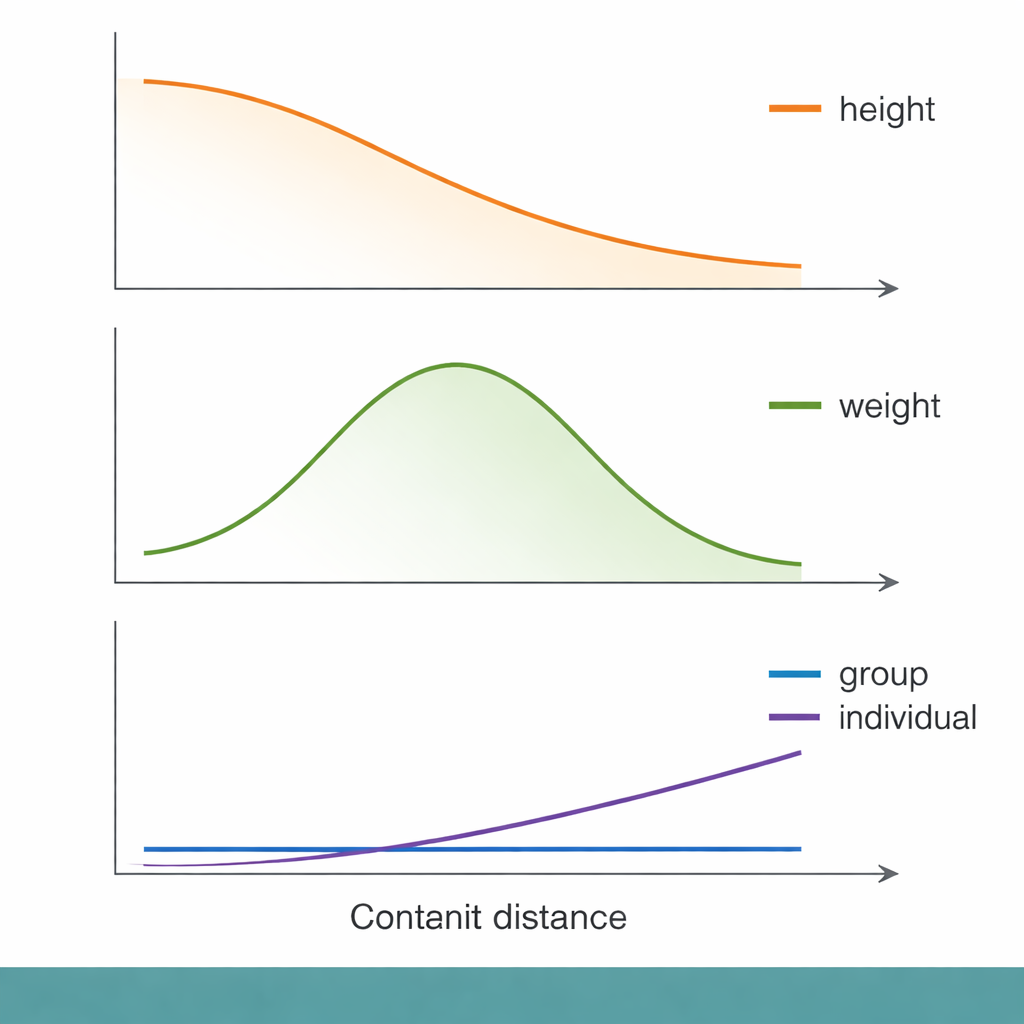
Su questa scala di distanza genetica sono emersi alcuni schemi familiari. Per l’altezza, ad esempio, l’accuratezza predittiva a livello di gruppo è diminuita in modo regolare man mano che le persone diventavano più distanti geneticamente dal gruppo GWAS. Tuttavia, quando i ricercatori hanno analizzato i dati a livello individuale, la distanza genetica spiegava solo una piccolissima frazione della qualità della predizione dei singoli tratti. Indicatori socioeconomici, come l’indice di deprivazione di Townsend (un indicatore di svantaggio materiale a livello di quartiere), hanno spiegato la variabilità delle predizioni altrettanto bene — o leggermente meglio. In altre parole, le persone con uno status socioeconomico più basso tendevano a ricevere predizioni genetiche meno accurate, anche all’interno della stessa fascia di distanza genetica, sottolineando che il contesto sociale può contare tanto quanto il DNA sulla utilità di un punteggio.
Tratti diversi, storie diverse, risposte diverse
Non tutti i tratti si comportano allo stesso modo. Per il peso corporeo e la percentuale di grasso corporeo, l’accuratezza predittiva è in realtà risultata massima a distanze genetiche intermedie prima di declinare, rompendo il semplice schema «più lontano significa peggio». I tratti legati al sistema immunitario, come il numero di globuli bianchi e dei linfociti, hanno mostrato comportamenti particolarmente strani. Per alcuni di questi tratti, l’accuratezza predittiva a livello di gruppo è scesa quasi a zero anche per persone non molto distanti geneticamente dal campione GWAS. Gli autori suggeriscono che i tratti immunitari possano essere modellati da pressioni evolutive rapidamente mutevoli — come infezioni passate — che modificano quali varianti del DNA sono rilevanti in popolazioni diverse. In questi casi, l’architettura genetica stessa può essere cambiata a tal punto che un punteggio basato su un gruppo diventa quasi inutile in un altro.
Il modo in cui misuriamo la performance può ribaltare il racconto
Il quadro diventa ancora più complicato se cambiamo il modo in cui si misura la «buona predizione». Gran parte dei lavori precedenti si è basata su una singola statistica chiamata R², che cattura quanta variazione di un tratto un punteggio spiega in un gruppo. Gli autori mostrano che altre metriche possono raccontare una storia diversa, specialmente per le malattie. Per l’asma, sia la precisione (quante delle previsioni di caso sono casi veri) sia il richiamo o sensibilità (quanti casi veri vengono individuati) sono diminuite con la distanza genetica in modi simili. Ma per il diabete di tipo 2, la precisione è rimasta abbastanza costante mentre il richiamo è effettivamente aumentato con la distanza — il che significa che il punteggio individuava una quota più ampia di casi veri in gruppi più distanti, nonostante fosse costruito in un gruppo più vicino. A seconda che una clinica dia più importanza a catturare tutti i pazienti ad alto rischio o a evitare falsi allarmi, si potrebbero trarre conclusioni opposte sulla trasferibilità del punteggio.
Cosa significa questo per l’uso dei punteggi genetici nella pratica
Nel complesso, lo studio sostiene che non possiamo giudicare l’utilità dei punteggi poligenici guardando solo a etichette ampie di ascendenza o a un unico numero di accuratezza. La qualità della predizione a livello individuale dipende da un mix di fattori: pattern sottili di somiglianza genetica, la storia evolutiva di ciascun tratto, gli ambienti e le condizioni sociali in cui le persone vivono e il modo particolare in cui il punteggio e la metrica di performance sono scelti. Per applicare i punteggi poligenici in modo equo ed efficace nella medicina, i ricercatori avranno bisogno di modi migliori per catturare la struttura genetica fine, per modellare le influenze sociali e ambientali e per abbinare le metriche di valutazione alle decisioni del mondo reale. Fino ad allora, i punteggi di rischio genetico dovrebbero essere usati con cautela, tenendo presente le persone — e i contesti — per cui funzionano male così come quelli per cui funzionano bene.
Citazione: Wang, J.Y., Lin, N., Zietz, M. et al. Three open questions in polygenic score portability. Nat Commun 17, 942 (2026). https://doi.org/10.1038/s41467-026-68565-3
Parole chiave: punteggi poligenici, predizione genetica, disparità di salute, ascendenza genetica, medicina di precisione