Clear Sky Science · it
Mappatura completa della dinamica e dell’interazione delle modificazioni dell’RNA tramite deep learning e sequenziamento diretto dell’RNA con nanopore
I segni di punteggiatura nascosti dell’RNA
Le molecole di RNA delle nostre cellule non sono semplici catene di A, C, G e U. Sono decorate da decine di minuscole modifiche chimiche che agiscono come segni di punteggiatura, contribuendo a controllare quali geni sono attivi, come vengono prodotti le proteine e come le cellule rispondono a stress e malattie. Tuttavia, fino a oggi gli scienziati sono riusciti a studiare per lo più queste modifiche una alla volta, rendendo difficile comprendere come agiscano in sinergia su tutto il genoma. Questo articolo presenta ORCA, un sistema di deep learning che legge direttamente molecole di RNA native e costruisce una mappa globale e multilivello di questi segni chimici e delle loro interazioni.
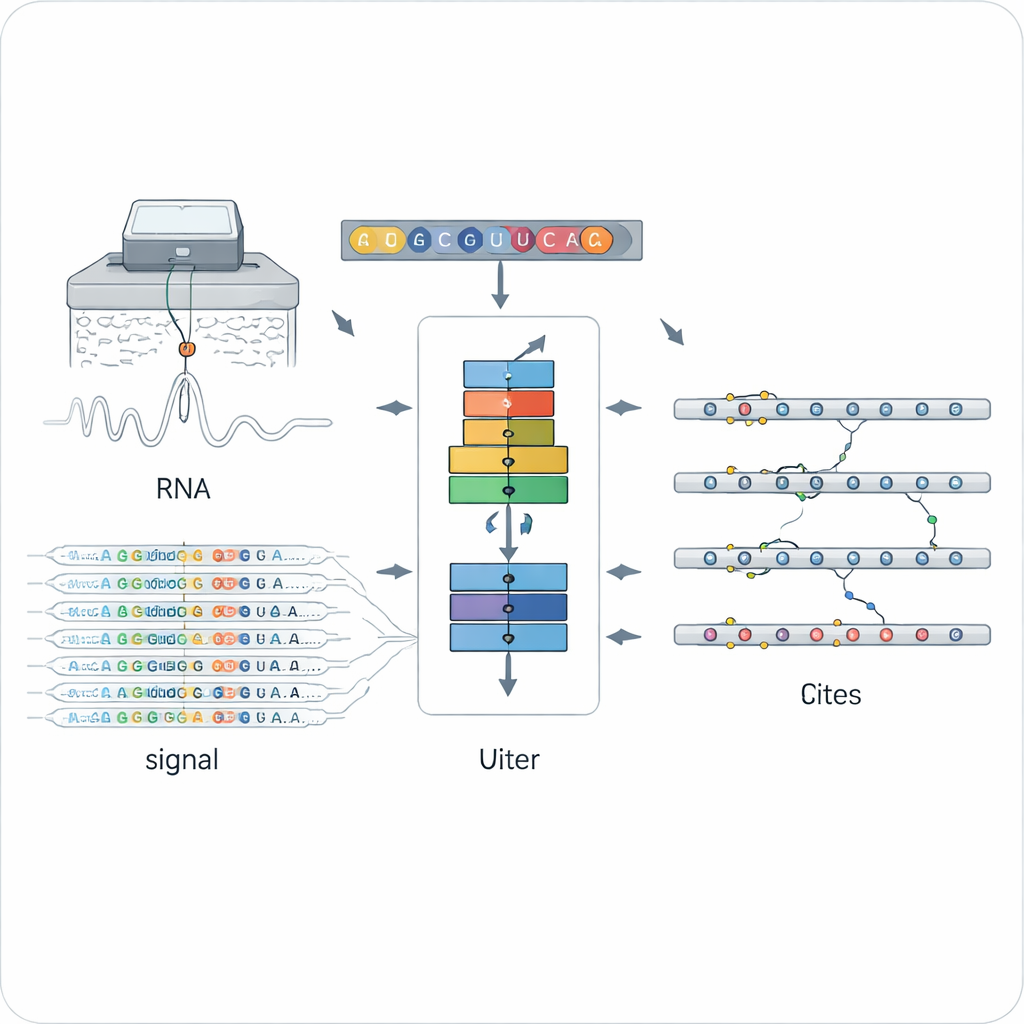
Un nuovo modo di leggere le modifiche chimiche sull’RNA
I metodi tradizionali per individuare le modifiche dell’RNA si basano solitamente su anticorpi speciali o reazioni chimiche mirate a un singolo tipo di modifica, come la diffusa N6‑metiladenosina (m6A). Questo li rende potenti ma limitati: ogni metodo rileva solo un tipo di modifica, spesso in una specifica configurazione sperimentale. Il sequenziamento diretto dell’RNA con nanopore ha aperto una porta diversa, facendo passare singole molecole di RNA attraverso un minuscolo poro e misurando le variazioni di corrente elettrica che dipendono dalla struttura chimica di ogni base. Le lettere modificate e non modificate distorcono il segnale e il processo di basecalling in modi sottili, ma dare senso a questi dati rumorosi e ad alta dimensionalità attraverso molteplici tipi di modifiche è stata una grande sfida.
Addestrare una rete neurale a riconoscere qualsiasi modifica
ORCA (Omni‑RNA modification Characterization and Annotation) affronta questa sfida in due fasi. Nella prima fase si concentra su una finestra ridotta intorno a ogni posizione dell’RNA e aggrega sia il segnale elettrico grezzo sia il modello degli errori di sequenziamento su molte letture. Poiché solo una frazione delle copie di RNA porta una data modifica, i siti veramente modificati mostrano distribuzioni di segnale più sbilanciate e errori di basecalling più frequenti in quella posizione. ORCA usa una rete neurale ricorrente profonda addestrata con una strategia “avversariale” in modo da apprendere schemi generali che distinguono siti modificati da non modificati, senza fissarsi su un singolo tipo chimico noto. Questo permette a ORCA di assegnare a ciascun sito un punteggio di modifica e una stima della frazione di molecole modificate.
Apprendere l’identità di ciascuna modifica
Nella seconda fase, ORCA impara a etichettare il tipo di modifica chimica presente. Gli autori forniscono al modello un insieme di siti ad alta confidenza provenienti da banche dati pubbliche, dove esperimenti convenzionali hanno già identificato m6A, 5‑metilcitosina (m5C), pseudouridina (Ψ), inosina, 2′‑O‑metilazione e diverse modifiche più rare. ORCA comprime i pattern di segnale, il contesto di sequenza e i brevi “motivi” di sequenza intorno a ciascun sito in una mappa a dimensione ridotta, quindi si affina per prevedere il tipo di modifica e la base esatta su cui ricade. Crucialmente, anche i siti non etichettati sono usati come esempi di “background”, il che aiuta il modello a evitare di forzare modifiche sconosciute in categorie sbagliate. Una volta addestrato, ORCA può trasferire queste etichette apprese a decine di migliaia di siti precedentemente non annotati in tutto il trascrittoma.
Osservare molte modifiche contemporaneamente
Applicando ORCA a cellule umane e murine, gli autori mostrano che non solo eguaglia o supera l’accuratezza degli strumenti di punta per modifiche specifiche come m6A, m5C e Ψ, ma può anche rilevare modifiche su cui non è stato esplicitamente addestrato. Per esempio, anche quando i dati m6A sono stati esclusi dall’addestramento, ORCA ha recuperato la maggior parte dei siti m6A misurati indipendentemente e li ha distinti correttamente da motivi di sequenza simili non modificati. Ha fatto lo stesso per gruppi 2′‑O‑metilici, siti di editing con inosina e una vasta gamma di cambiamenti chimici sull’RNA ribosomiale, incluse molte modifiche rare misurate con spettrometria di massa. Complessivamente, ORCA amplia notevolmente il catalogo conosciuto di siti di modifica dell’RNA, con incrementi multipli nelle annotazioni di m5C, Ψ, m7G e altre modifiche a bassa abbondanza rispetto alle banche dati esistenti.
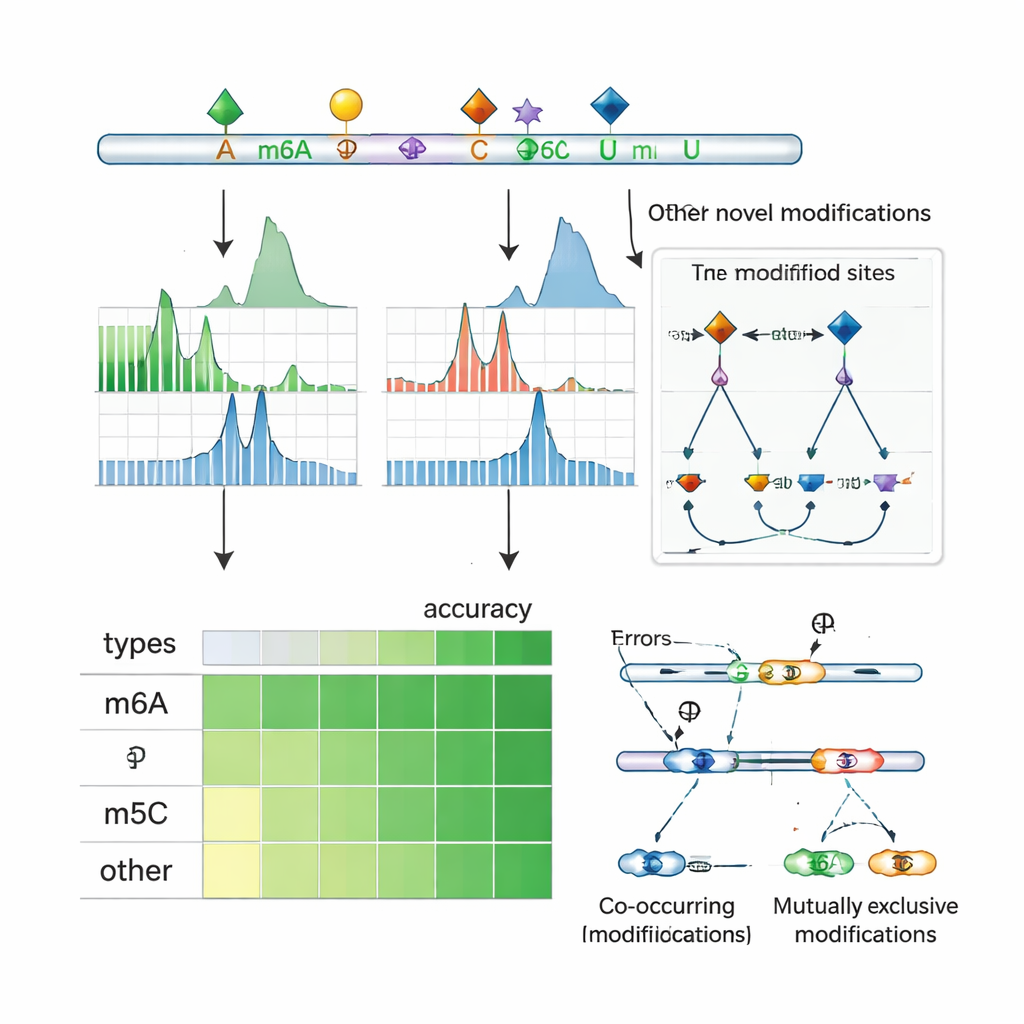
Rivelare interazioni e controllo dello splicing
Poiché il sequenziamento nanopore legge molecole di RNA intere, ORCA può esaminare quali modifiche compaiono insieme sullo stesso trascritto e quali tendono a escludersi a vicenda. Gli autori raggruppano modifiche vicine lungo gli RNA e usano un modello probabilistico per inferire se coppie di siti sono spesso co‑modificati o mutuamente esclusivi su singole molecole. Riscontrano frequente co‑occorrenza di m6A con m5C e altre modifiche, così come molte regioni in cui un sito è modificato solo quando il sito vicino non lo è. Nelle linee cellulari umane, questi schemi spesso ricadono vicino a esoni alternativamente inclusi o scartati e si sovrappongono ai siti di legame per regolatori dello splicing e proteine “lettori” che riconoscono l’RNA modificato. In geni specifici, ORCA rivela che varianti di splicing particolari sono arricchite per un certo schema di modifiche, mentre varianti alternative portano un diverso schema, collegando la decorazione chimica locale dell’RNA a come i messaggi vengono tagliati e ricomposti.
Perché questo è importante per la biologia e la medicina
Combinando il sequenziamento diretto dell’RNA con un deep learning flessibile, ORCA trasforma un complicato segnale elettrico in una ricca mappa multilivello di segni chimici attraverso il trascrittoma. Per i non specialisti, l’esito chiave è che gli scienziati possono ora vedere non solo dove avvengono singole modifiche dell’RNA, ma quante e quali modifiche decorano la stessa molecola e come queste combinazioni si relazionano alla regolazione genica, in particolare allo splicing dell’RNA. Questo quadro rende possibile studiare “epigenetica” dell’RNA in molti tipi cellulari e condizioni senza progettare un nuovo esperimento per ogni modifica, aprendo la strada a scoperte su come questi piccoli aggiustamenti chimici contribuiscono allo sviluppo, alla funzione cerebrale e a malattie come il cancro e i disturbi neurologici.
Citazione: Dong, H., Gao, Y., Cai, Z. et al. Comprehensive mapping of RNA modification dynamics and crosstalk via deep learning and nanopore direct RNA-sequencing. Nat Commun 17, 1722 (2026). https://doi.org/10.1038/s41467-026-68419-y
Parole chiave: Modificazioni dell'RNA, sequenziamento nanopore, deep learning, epitranscrittoma, splicing alternativo