Clear Sky Science · it
Il ruolo delle ripetizioni a bassa complessità nelle interazioni RNA–RNA e un framework di deep learning per la predizione dei duplex
Sequenze RNA “appiccicose” che modellano il comportamento cellulare
All’interno di ogni cellula, le molecole di RNA si scontrano continuamente tra loro, formando alleanze fugaci che contribuiscono a controllare quali geni vengono attivati, come vengono prodotti le proteine e come si sviluppano le cellule. Questo studio rivela che molti di questi incontri RNA–RNA non sono casuali: sono guidati da brevi sequenze semplici e altamente ripetitive che funzionano come un Velcro molecolare. I ricercatori hanno inoltre sviluppato uno strumento di intelligenza artificiale in grado di individuare dove è probabile che si formino tali coppie di RNA, aprendo nuove possibilità per esplorare il funzionamento delle cellule in salute e malattia.
Ripetizioni semplici con effetti potenti
L’RNA è spesso descritto come un messaggero che trasporta l’informazione genetica dal DNA alle proteine, ma svolge anche ruoli da impalcatura, regolatore e guida. Gran parte di questa attività dipende dall’appaiamento di due filamenti di RNA. Combinando dati provenienti da diversi ampi studi sperimentali in cellule umane e murine, gli autori mostrano che le regioni di RNA che effettivamente partecipano a questi appaiamenti sono fortemente arricchite in quelle che chiamano ripetizioni a bassa complessità. Si tratta di tratti costruiti da brevi motivi—per esempio sequenze ripetute di basi G e C—ripetuti più e più volte. Lungi dall’essere “spazzatura” genomica, questi segmenti ripetitivi si rivelano siti preferenziali di ancoraggio dove un RNA può legarsi a molti altri, formando centri di interazione densi su tutto il trascrittoma. 
Hub di RNA per lo sviluppo e la regolazione
Quando il team ha analizzato quali geni contengono questi siti di contatto ricchi di ripetizioni, è emerso un pattern evidente: molti codificano proteine che controllano lo sviluppo e l’identità cellulare, come i fattori di trascrizione. Anche in linee cellulari tumorali non in differenziamento attivo, gli RNA associati a programmi di sviluppo erano fortemente coinvolti nei contatti basati su ripetizioni. Gli autori hanno inoltre esaminato in dettaglio specifici RNA non codificanti lunghi (lncRNA), molecole che non codificano proteine ma spesso le regolano. Per esempio, i bersagli del lncRNA TINCR e di un altro lncRNA importante per la formazione dei motoneuroni, Lhx1os, hanno entrambi mostrato un eccesso di ripetizioni complementari. In questi casi, ripetizioni semplici sul lncRNA sono abbinate da ripetizioni complementari negli RNA partner, permettendo appaiamenti stabili che possono modulare i livelli o la traduzione di geni chiave per lo sviluppo.
Dove entrano proteine ed enzimi di editing
Questi contatti guidati dalle ripetizioni raramente agiscono da soli. Gli autori hanno sovrapposto alle loro mappe di interazione i profili di legame proteico e hanno trovato che molti siti di contatto contenenti ripetizioni sono riconosciuti anche da proteine leganti l’RNA coinvolte nel controllo della traduzione, nella degradazione dell’RNA e nella formazione di granuli citoplasmatici come i P-body e gli stress granule. Una proteina in particolare, STAU1, che può innescare la distruzione dei suoi target RNA, si lega frequentemente ai duplex formati attraverso ripetizioni a bassa complessità. L’abbattimento di STAU1 ha portato a livelli più alti degli RNA coinvolti in questi duplex, soprattutto quelli portatori di ripetizioni, suggerendo che l’appaiamento mediato da ripetizioni può segnalare trascritti per una degradazione controllata. Le stesse regioni ricche di ripetizioni attirano anche enzimi di editing dell’RNA come ADAR1, che modificano chimicamente basi specifiche all’interno degli RNA a doppio filamento, suggerendo che le ripetizioni a bassa complessità aiutano a posizionare siti di editing che affinano il comportamento degli RNA.
Insegnare a una rete neurale a leggere i contatti RNA
I programmi informatici standard cercano di prevedere il legame RNA–RNA principalmente sulla base della stabilità termodinamica—quanta energia sarebbe necessaria per formare o rompere un duplex. Pur essendo utili, questi modelli spesso non colgono le interazioni reali osservate nelle cellule, specialmente tra RNA lunghi. Per andare oltre le semplici regole energetiche, gli autori hanno addestrato un modello di deep learning chiamato RIME che utilizza embedding in stile “modello linguistico”: rappresentazioni numeriche delle sequenze di RNA che codificano pattern appresi da enormi raccolte di dati su acidi nucleici. A RIME sono state mostrate coppie di segmenti di RNA e il modello ha imparato a classificare se interagiscono, utilizzando molti appaiamenti reali provenienti da esperimenti di crosslinking a base di psoralene come esempi positivi e coppie non interagenti accuratamente costruite come negativi. 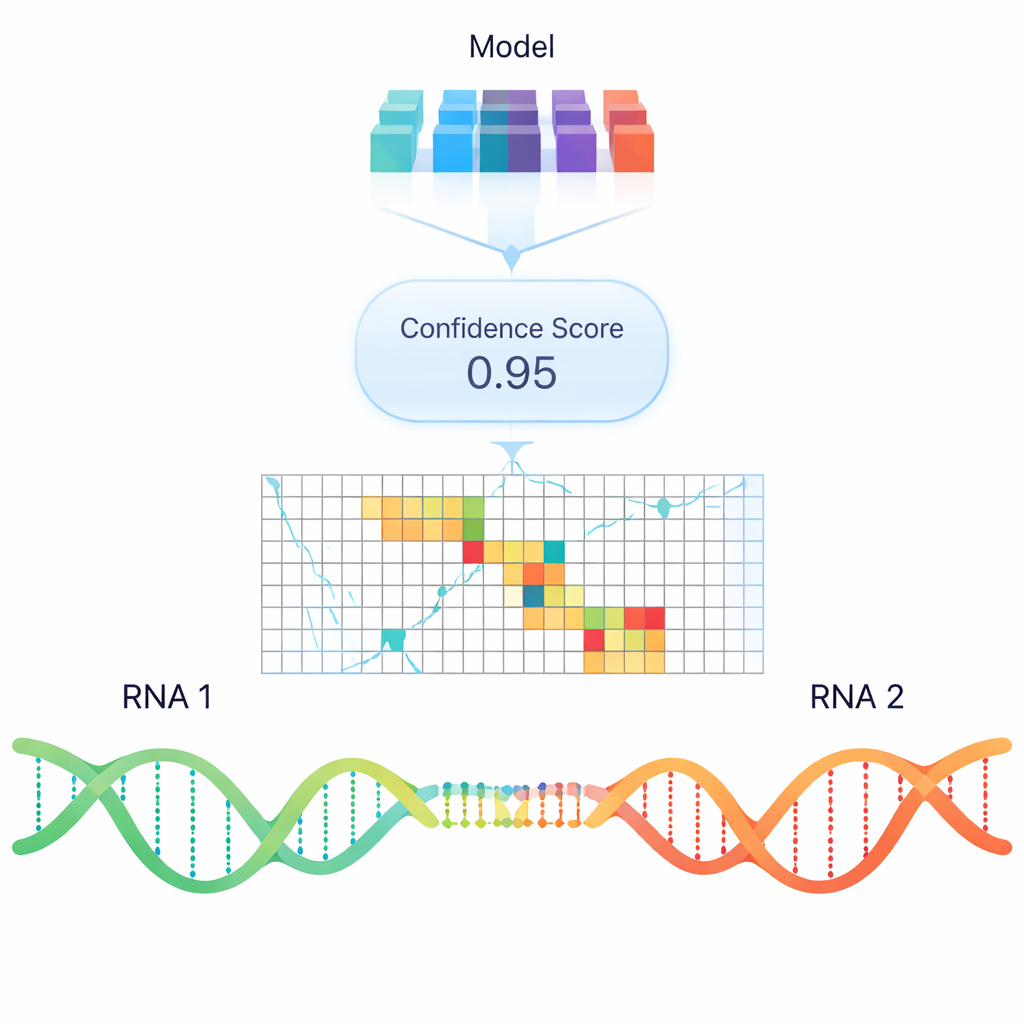
Previsioni più intelligenti e nuovi indizi biologici
Nel confronto con i migliori strumenti basati sulla termodinamica e con un altro metodo a rete neurale, RIME si distingue costantemente per la sua capacità di separare i veri contatti RNA–RNA dai decoy, soprattutto per le interazioni sperimentali ad alta confidenza. Non solo predice se due RNA si appaieranno, ma tende anche a evidenziare le regioni esatte coinvolte, e impara in modo naturale che le ripetizioni a bassa complessità sono forti predittori di contatto. Sorprendentemente, lo stesso modello, addestrato solo su interazioni tra RNA diversi, funziona bene anche per prevedere l’appaiamento interno all’interno di una singola molecola di RNA, in accordo sia con esperimenti strutturali sia con i classici algoritmi di folding. Per regolatori non codificanti come TINCR, NORAD e SMaRT, RIME riscopre con successo siti di interazione funzionali noti e suggerisce regioni candidate aggiuntive.
Perché è importante
Per il lettore non specialistico, il messaggio chiave è che brevi tratti ripetitivi nell’RNA—una volta facili da liquidare come rumore inutile—agiscono come punti di connessione centrali nel diagramma di collegamenti dell’RNA cellulare. Aiutano a mettere in contatto gli RNA, attraggono proteine regolatorie ed enzimi di editing e sono ampiamente impiegati in vie che controllano come le cellule si sviluppano e rispondono allo stress. Il nuovo modello RIME fornisce ai ricercatori un modo potente per esplorare i genomi alla ricerca di queste partnership RNA–RNA, comprese quelle che possono andare storte in malattie neurologiche e altre patologie legate all’espansione di ripetizioni. In sostanza, questo lavoro mostra che comprendere—e prevedere—come semplici ripetizioni di RNA si attaccano tra loro può rivelare strati nascosti di regolazione genica.
Citazione: Setti, A., Bini, G., Pellegrini, F. et al. The role of low-complexity repeats in RNA–RNA interactions and a deep learning framework for duplex prediction. Nat Commun 17, 1637 (2026). https://doi.org/10.1038/s41467-026-68356-w
Parole chiave: Interazioni RNA–RNA, Ripetizioni a bassa complessità, RNA non codificanti lunghi, Deep learning, Regolazione genica