Clear Sky Science · it
Applicazione di machine learning e genomica per il miglioramento delle colture orfane
Colture nascoste con grande potenziale
In Africa, Asia e America Latina, milioni di persone dipendono dalle cosiddette “colture orfane” come sorgo, teff, cassava e arachide. Queste piante raramente fanno notizia, eppure spesso resistono meglio al calore, alla siccità, ai parassiti e ai terreni poveri rispetto agli alimenti di base globali come grano o riso. Questo articolo di revisione esplora come due strumenti potenti — la genomica e il machine learning — possano sbloccare il potenziale di queste colture trascurate, rafforzando la sicurezza alimentare locale e fornendo allo stesso tempo geni preziosi che potrebbero rinforzare le colture principali a livello mondiale.
Perché le colture trascurate contano
Le colture orfane sono talvolta definite “neglette” o “sottoutilizzate” perché hanno ricevuto molta meno attenzione scientifica e commerciale rispetto alle grandi colture da esportazione. Tuttavia, sono pilastri nutrizionali per molte comunità e sono spesso coltivate in ambienti marginali e difficili dove altre colture falliscono. Diversamente da grano o riso, la maggior parte delle colture orfane ha mancato i progressi della Rivoluzione Verde in termini di miglioramento e degli strumenti moderni come la selezione assistita da marcatore e l’editing del genoma. Progetti genomici come l’African Orphan Crops Consortium stanno iniziando a sequenziare e catalogare il loro DNA, ma trasformare dati genetici grezzi in miglioramenti pratici resta una sfida importante.
Insegnare ai computer a leggere le piante
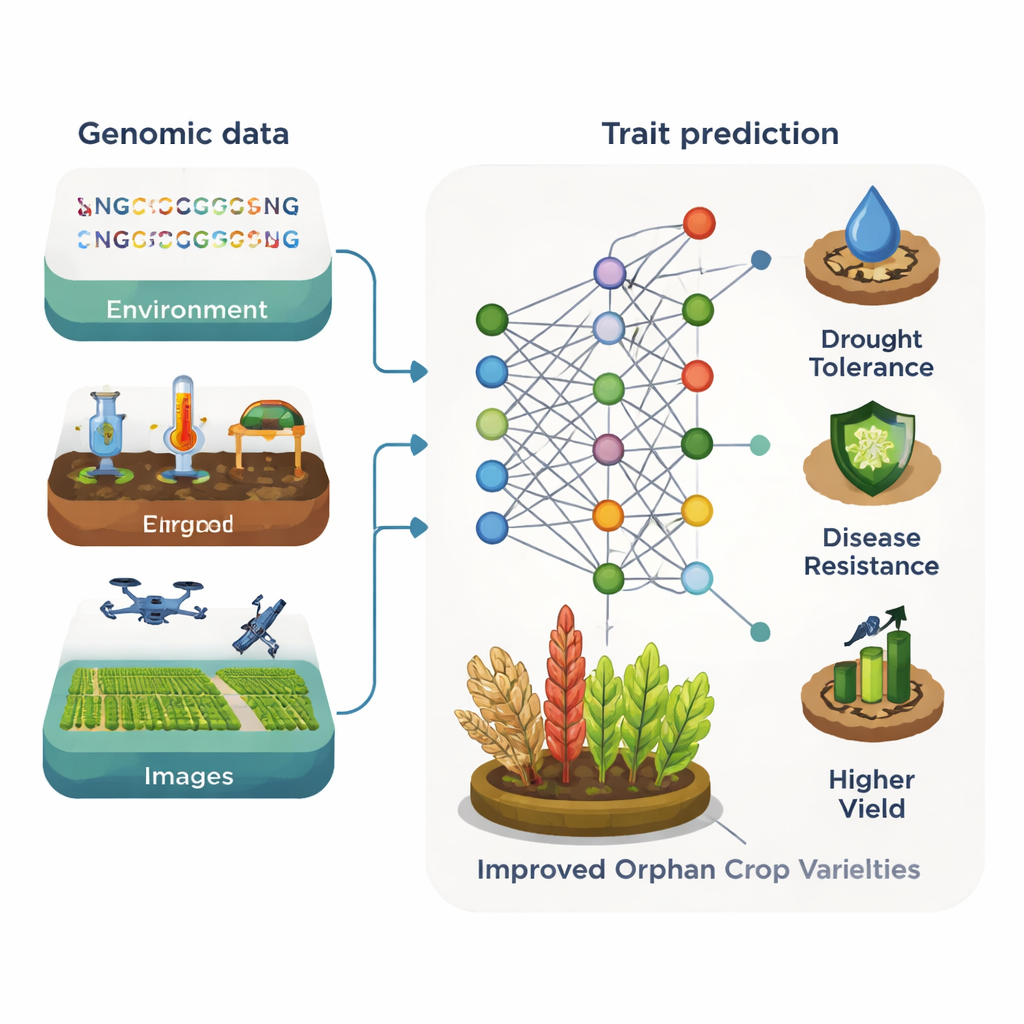
Il machine learning — metodi informatici che apprendono schemi da grandi insiemi di dati — sta già trasformando il miglioramento genetico nelle colture principali. Combinando sequenze genomiche, dati meteorologici e del suolo, letture di sensori e immagini da droni o smartphone, gli algoritmi possono prevedere tratti complessi come resa, resistenza alle malattie o qualità del seme. Diversi tipi di modelli, dagli alberi decisionali alle reti neurali profonde, eccellono in contesti diversi. Talvolta gli strumenti statistici tradizionali eguagliano o superano il deep learning, ma in generale la fusione di più fonti di dati e modelli tende a fornire ai miglioratori previsioni più accurate e consistenti rispetto a qualsiasi approccio singolo.
Sfruttare al massimo dati scarsi
Per le colture orfane, l’ostacolo principale non è la potenza di calcolo ma la scarsità di dati. Esistono solo poche collezioni genomiche e di immagini pubbliche, e poche sono abbastanza grandi per le pipeline convenzionali di machine learning. Nonostante ciò, le prime dimostrazioni sono promettenti. Nel sorgo, ad esempio, modelli di deep learning che utilizzavano semplici fotografie del granello hanno previsto con alta accuratezza i livelli di proteine e antiossidanti, offrendo un’alternativa più economica ai test di laboratorio. In un altro caso, misurazioni nel vicino infrarosso e deep learning sono state usate per stimare tratti nutrizionali nell’erba Perilla. La review sostiene che costruire banche dati condivise di genomi, immagini e profili chimici per le colture orfane moltiplicherebbe rapidamente l’impatto di tali strumenti.
Prendere in prestito conoscenza dalle colture maggiori
Un’idea centrale dell’articolo è il “trasferimento di conoscenza” fra specie. Molte colture orfane sono parenti prossimi di colture maggiori, condividendo ampi tratti di DNA e geni simili. I modelli di machine learning possono sfruttare questa correlazione. Strumenti addestrati inizialmente su piante ben studiate come Arabidopsis o mais possono aiutare a individuare geni per tratti quali altezza della pianta, qualità del seme o tolleranza allo stress in una parente meno nota. Grandi modelli linguistici sviluppati originariamente per genomi umani o vegetali possono anche trattare il DNA come una sorta di testo, imparando schemi che identificano regioni regolatorie o geni importanti. Una volta addestrati su dataset ricchi, questi modelli possono essere adattati (fine‑tuned) su dati limitati di colture orfane per prevedere la funzione genica, evidenziare bersagli per l’editing del genoma e guidare programmi di miglioramento più efficienti.
Dagli algoritmi ai campi e agli agricoltori
Gli autori sottolineano che la tecnologia da sola non trasformerà le colture orfane. Il progresso dipende da investimenti in scienziati locali, partnership con piccoli agricoltori e politiche che assicurino che le comunità traggano beneficio dalle nuove varietà. Approcci di citizen science, in cui gli agricoltori testano le varietà direttamente nelle proprie terre, possono generare dati preziosi per il machine learning allineando la ricerca ai bisogni e ai gusti locali. Poiché i finanziamenti sono limitati, l’articolo raccomanda una strategia bilanciata: combinare il miglioramento tradizionale e l’agronomia a basso costo con progetti genomici e di machine learning mirati, e condividere strumenti e dati tra paesi e tra colture orfane e colture maggiori.
Cosa significa per il nostro futuro alimentare
In termini semplici, l’articolo conclude che computer più intelligenti insieme a migliori informazioni genetiche possono aiutare a trasformare le colture “dimenticate” di oggi nelle colture pronte per il clima di domani. Imparando dalle grandi colture e applicando quelle lezioni a quelle minori — e poi retroalimentando le scoperte nella direzione opposta — machine learning e genomica possono accelerare la ricerca di varietà robuste e nutrienti. Se supportato da politiche lungimiranti e da una collaborazione genuina con le comunità agricole, questo approccio potrebbe migliorare le diete, rafforzare la resilienza ai cambiamenti climatici e ampliare il repertorio agricolo mondiale oltre un ristretto insieme di colture di base.
Citazione: MacNish, T.R., Danilevicz, M.F., Bayer, P.E. et al. Application of machine learning and genomics for orphan crop improvement. Nat Commun 16, 982 (2025). https://doi.org/10.1038/s41467-025-56330-x
Parole chiave: colture orfane, machine learning, genomica, miglioramento delle colture, sicurezza alimentare