Clear Sky Science · it
Stima e modifica dell’illuminazione neurale da singola vista per display a campo di luce dinamico
Perché il tuo mondo virtuale dovrebbe corrispondere al tuo salotto
Chiunque abbia indossato un visore per realtà virtuale o mista lo ha notato: un oggetto digitale che sembra fuori posto, con illuminazione e ombre che non coincidono con la stanza reale. Questo articolo affronta proprio quel problema. Gli autori presentano un metodo che permette ai visori di “comprendere” l’illuminazione dell’ambiente reale a partire da una singola vista della telecamera, e poi di usare quelle informazioni per far apparire gli oggetti virtuali come se appartenessero davvero al tuo mondo—senza bisogno di sonde luminose speciali, acquisizioni elaborate o pesanti ricalibrazioni.
Rendere più gestibile la luce nello spazio
In fisica e grafica computerizzata, l’aspetto di una scena è governato dal suo «campo luminoso» completo: tutti i raggi di luce che attraversano lo spazio in ogni direzione. Ricostruire esattamente questo campo richiede normalmente molti dati, con numerose immagini e misure accurate. Tecniche 3D moderne come i neural radiance fields possono memorizzare scene in reti neurali, ma di solito «fissano» l’illuminazione presente al momento della cattura. Questo significa che la scena virtuale appare corretta solo nelle condizioni di luce originali e si rompe quando l’illuminazione reale cambia. Gli autori puntano a superare questo limite trovando una descrizione compatta dell’illuminazione reale a partire da dati minimi, per poi utilizzarla a rilucare in modo flessibile una scena 3D neurale.
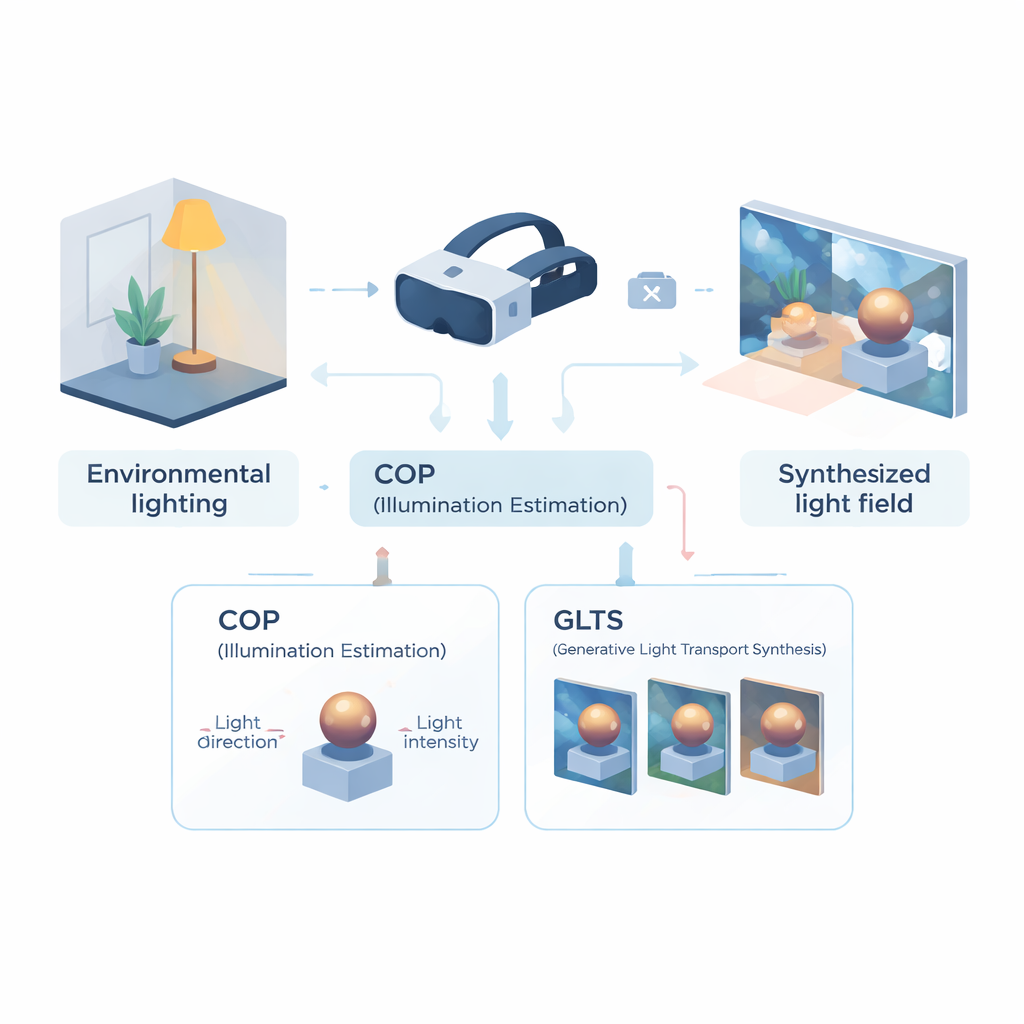
Addestrare un visore a leggere la stanza
La prima parte del framework è un modulo di percezione ottica computazionale (COP), progettato per rilevare l’illuminazione da una singola vista della telecamera. Invece di ricostruire l’intero campo luminoso, COP si concentra sulla sorgente luminosa dominante: direzione e intensità. Una rete neurale multi-scala analizza l’immagine in ingresso alla ricerca di indizi fisici—riflessi brillanti, gradienti di ombreggiatura e ombre—mentre un passaggio di interpolazione speciale corregge il modo non lineare con cui le fotocamere comprimono la luminosità. Ne risultano stime numeriche dell’intensità e della direzione della luce più fedeli all’energia reale nella scena. Una seconda fase, chiamata interprete semantico, affina poi questi valori e produce una breve descrizione testuale dell’illuminazione (per esempio, luce proveniente dall’alto e verso destra). Questa combinazione di numeri e parole rende la stima più stabile e facile da usare nelle fasi successive.
Ridipingere gli oggetti con nuova luce
Con questa descrizione compatta dell’illuminazione, entra in gioco il secondo modulo—sintesi generativa del trasporto di luce (GLTS). GLTS parte da una rappresentazione neurale 3D esistente di un oggetto o di una scena, resa una volta con l’illuminazione precedente fissata. Guidata dalla direzione inferita della luce, dall’intensità e dalla descrizione testuale, una rete generativa «ridipinge» questa vista in modo che luci e ombre corrispondano al nuovo ambiente. Per mantenere il risultato sia realistico sia specifico per l’oggetto, GLTS fonde due tipi di guida: controllo globale dai parametri di illuminazione e dettagli fini tratti direttamente dall’immagine osservata. Attraverso un processo di addestramento specializzato che si concentra esclusivamente su come un singolo oggetto risponde a luci diverse, il modello impara a spostare i riflessi e ammorbidire i bordi delle ombre in modi fisicamente plausibili invece di applicare semplicemente un filtro stilistico generico.
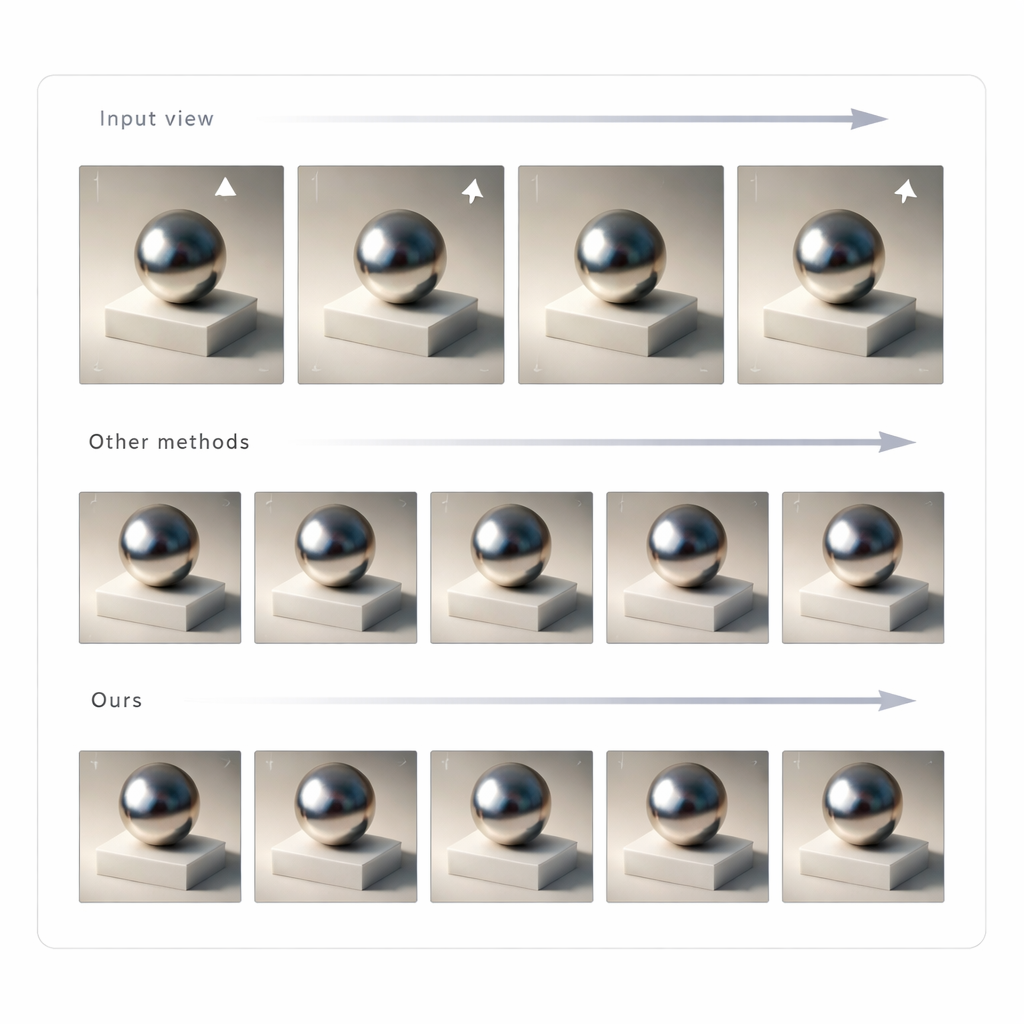
Costruire un campo luminoso 3D coerente da molte viste
Modificare una singola immagine non è sufficiente per una realtà mista convincente; l’illuminazione deve rimanere coerente mentre muovi la testa. Per ottenere questo, gli autori usano GLTS per generare un insieme di immagini rilucate da molte angolazioni e poi le trattano come obiettivi per ricostruire la scena 3D. Un processo di ottimizzazione congiunta aggiusta simultaneamente la rappresentazione 3D neurale e le posizioni delle camere virtuali in modo che il rendering del nuovo modello riproduca tutte le viste sintetizzate. Questo passaggio corregge sottili distorsioni introdotte dalla rete generativa e produce un asset 3D coerente il cui aspetto rimane stabile e credibile da qualsiasi angolazione. Il team ha confrontato il loro metodo con diverse tecniche di rilucamento all’avanguardia e ha scoperto che offriva una corrispondenza più nitida con le immagini di riferimento e ombre e riflessi dall’aspetto più naturale, giudicati sia con metriche a livello di pixel sia con misure basate sulla percezione.
Cosa significa per i futuri visori
Per i non specialisti, il punto chiave è che questo lavoro mostra come i futuri dispositivi VR, AR e di realtà mista potrebbero adattare i contenuti virtuali all’illuminazione del mondo reale con una sola rapida occhiata dalla telecamera del visore. Al posto di acquisizioni laboriose o del riaddestramento di modelli su misura per ogni nuova scena, il sistema stima le condizioni luminose principali, rigenera come la scena dovrebbe apparire sotto tali condizioni e ricostruisce una rappresentazione 3D coerente. Il risultato sono oggetti virtuali la cui luminosità, brillantezza e ombre rispondono all’ambiente in modo molto simile agli oggetti reali, aprendo la strada a esperienze di realtà mista che sembrano meno sovrapposizioni grafiche e più autentiche aggiunte al mondo fisico.
Citazione: Hong, X., Xie, J., Sheng, J. et al. Single-view neural illumination estimation and editing for dynamic light field display. Light Sci Appl 15, 147 (2026). https://doi.org/10.1038/s41377-026-02234-4
Parole chiave: illuminazione per realtà mista, campi luminosi neurali, riallestimento da singola vista, display per realtà virtuale, imaging computazionale