Clear Sky Science · it
Riconoscimento multimodale delle immagini del patrimonio culturale basato su una rete di fusione quantistica e classica multimodale
Perché insegnare ai computer a conoscere i tesori antichi è importante
I tesori culturali conservati in musei e archivi vengono sempre più spesso fotografati e resi disponibili online, ma molte di queste immagini sono etichettate in modo approssimativo o non lo sono affatto. Questo rende difficile per visitatori, insegnanti e ricercatori trovare ciò che cercano e limita la profondità con cui il pubblico può esplorare il patrimonio comune dell’umanità. Questo articolo esplora un nuovo modo per riconoscere e ordinare automaticamente tali immagini combinando due idee che raramente si incontrano: le collezioni museali e il calcolo quantistico.
Dai depositi polverosi alle collezioni digitali
I musei di oggi conservano milioni di oggetti, dai bronzi e la laccatura agli abiti ricamati. Molte istituzioni stanno correndo a digitalizzare questi patrimoni in modo che chiunque abbia una connessione Internet possa consultarli. Tuttavia, una volta che le immagini sono online devono essere collocate nelle categorie corrette—come smalto, giada, seta o broccato—per essere davvero utili. Gli strumenti convenzionali di intelligenza artificiale guardano in genere solo ai pixel di ogni immagine. Ignorano le ricche descrizioni testuali che curatori e storici allegano agli oggetti, nonostante queste didascalie spesso menzionino materiali, colori e motivi non evidenti a prima vista. Con l’aumentare delle collezioni, anche gli algoritmi classici faticano per velocità, consumo energetico e complessità.
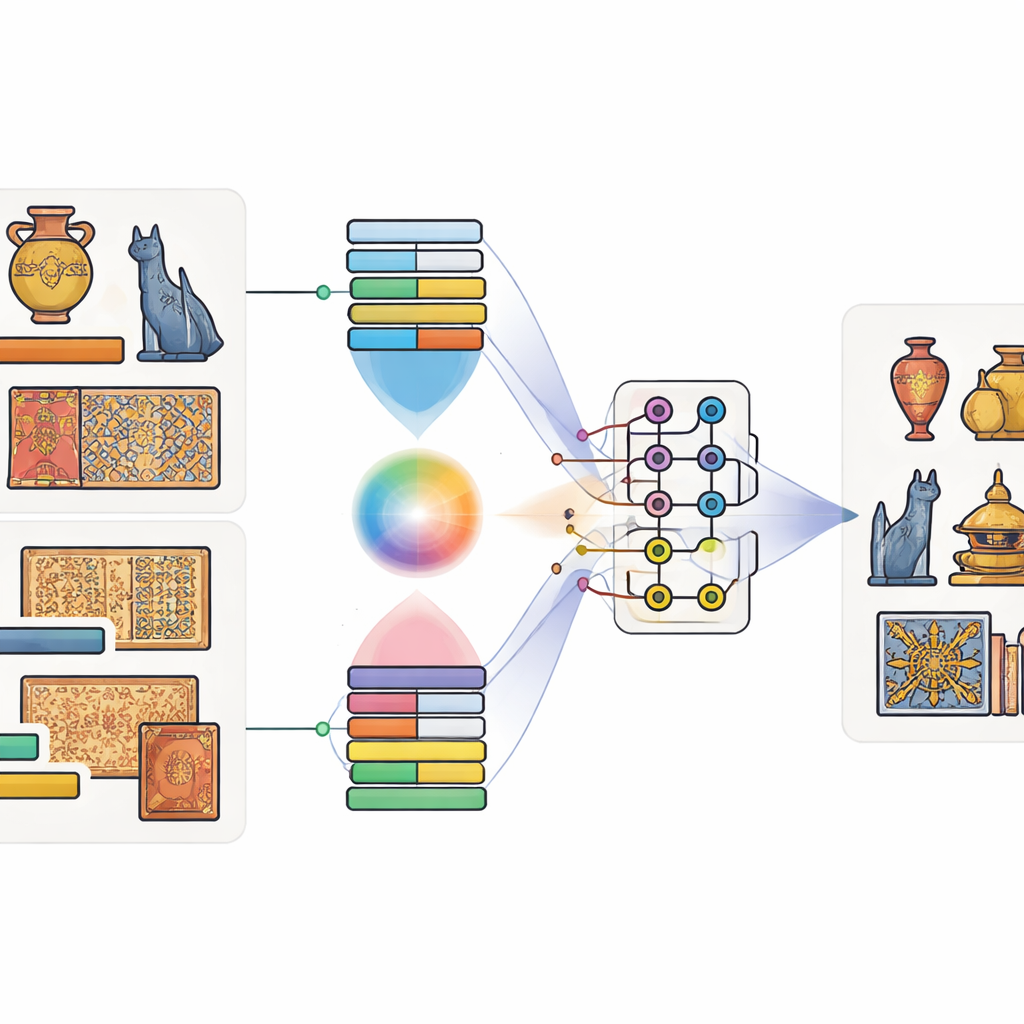
Accoppiare immagini e parole, e bit con qubit
Gli autori propongono un modello che chiamano Modello di Fusione Multimodale Quantistico-Classico. “Multimodale” significa semplicemente che presta attenzione a più tipi di informazione contemporaneamente—in questo caso sia all’immagine di un reperto sia alla sua didascalia. Innanzitutto si utilizzano strumenti consolidati addestrati su enormi insiemi di dati: una rete profonda per le immagini per catturare forme e trame, e un modello linguistico per cogliere il significato della didascalia. Un meccanismo di attenzione speciale impara poi quali regioni dell’immagine tendono ad associarsi a quali parole. Ad esempio, quando una didascalia menziona “drago dorato”, il modello impara a focalizzarsi sulle regioni color oro dalla forma di drago. Questo produce una descrizione congiunta che fonde vista e linguaggio.
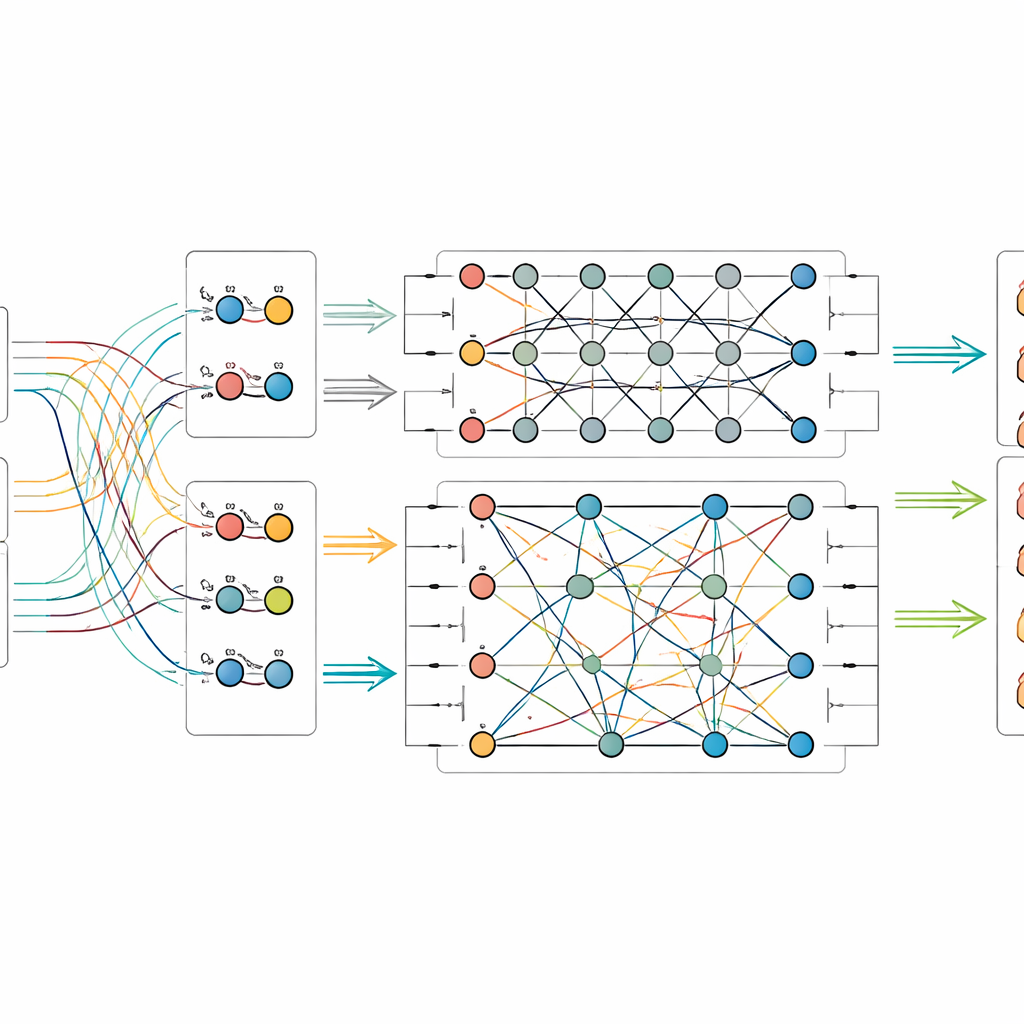
Lasciare che i circuiti quantistici mescolino i segnali
Una volta estratte le caratteristiche immagine-testo, il modello le alimenta in un piccolo circuito quantistico simulato. Poiché l’hardware quantistico attuale dispone di un numero modesto di qubit, gli autori comprimono l’informazione usando uno schema che impacchetta molti valori classici nelle ampiezze di pochi qubit. All’interno della parte quantistica progettano un circuito a due stadi che applica ripetutamente rotazioni ai singoli qubit e poi li intreccia—costringendo i loro stati a diventare interdipendenti. Questa struttura è pensata per far emergere relazioni sottili tra pattern visivi e indizi testuali che potrebbero altrimenti sfuggire. Dopo questo processamento quantistico lo stato dei qubit viene misurato e convertito nuovamente in numeri ordinari, che vengono poi passati a un classificatore finale che predice la categoria dell’oggetto.
Mettere alla prova il nuovo approccio
Per verificare se il loro metodo offra benefici reali, i ricercatori hanno assemblato due nuovi dataset dal Museo della Città Proibita: uno di manufatti fisici come smalti, lavori in oro e argento, lacca, bronzo e giada, e un altro incentrato sui tessuti come seta, raso, broccato e lo stile di tessitura complesso noto come kesi. Ogni immagine è corredata da una didascalia ufficiale e da un’etichetta affidabile tratta dai registri del museo. Hanno confrontato il loro modello di fusione quantistico–classico con una serie di forti concorrenti, incluse soluzioni basate solo su immagini, solo su testo e altre tecniche combinate. Su entrambi i dataset il nuovo modello ha ottenuto i punteggi più elevati in accuratezza e misure correlate, superando anche baseline multimodali avanzate e ispirate al quantistico. Esperimenti supplementari hanno mostrato come le prestazioni dipendano dal numero di qubit e dalla profondità del circuito, e che il modello rimane affidabile anche quando in simulazione vengono introdotti tipi comuni di rumore quantistico.
Cosa potrebbe significare per i futuri visitatori dei musei
Per i non specialisti, il messaggio chiave è che mescolare immagini, parole e processamento ispirato al quantistico può rendere i computer migliori nel distinguere diversi tipi di oggetti culturali. Mentre le parti quantistiche sono attualmente eseguite su simulatori piuttosto che su macchine quantistiche su larga scala, lo studio indica una via verso strumenti più efficienti ed espressivi man mano che l’hardware matura. In termini pratici, tali sistemi potrebbero aiutare musei e archivi a ordinare automaticamente nuovi caricamenti, ripulire vecchi registri e rendere più facile per le persone cercare “vasi rituali in giada” o “robe ricamate con dragoni” e trovarli davvero. Il lavoro suggerisce che il calcolo quantistico potrebbe diventare una nuova strada utile per comprendere e preservare il patrimonio culturale nell’era digitale.
Citazione: Fan, T., Wang, H., Zhao, Y. et al. Multimodal cultural heritage image recognition based on quantum and classical multimodal fusion network. npj Herit. Sci. 14, 160 (2026). https://doi.org/10.1038/s40494-026-02419-5
Parole chiave: immagini del patrimonio culturale, apprendimento automatico quantistico, fusione multimodale, digitalizzazione dei musei, riconoscimento delle immagini