Clear Sky Science · it
Identificazione di informazioni visive e Q&A sugli eredi del patrimonio culturale immateriale mediante un framework Graph-Retrieval potenziato
Portare le tradizioni nascoste nell’era digitale
In tutta la Cina, maestri di opera tradizionale, intaglio della carta, burattini d’ombra e altre arti viventi conservano abilità tramandate per generazioni. Tuttavia gran parte di ciò che sappiamo su questi eredi esiste solo in file e immagini sparse online, rendendo difficile per il pubblico — o anche per i ricercatori — trovare informazioni attendibili. Questo articolo presenta un nuovo framework informatico che legge automaticamente i “biglietti da visita visivi” degli eredi del patrimonio culturale immateriale (ICH) e poi utilizza modelli linguistici avanzati per rispondere a domande e generare rapporti leggibili su di essi.
Dalle schede illustrate alla conoscenza strutturata
Molte istituzioni culturali ora pubblicano schede digitali che combinano testo, impaginazione e semplici elementi grafici per presentare ogni erede: nome, arte, luogo, biografia e altro. Gli umani le possono scorrere con un colpo d’occhio, ma i computer faticano perché le schede provengono da regioni diverse, adottano design differenti e spesso contengono testo mancante o danneggiato. Gli autori costruiscono un grande dataset di 5.237 di queste schede per eredi ICH cinesi, ciascuna etichettata con cura con dieci tipi informativi chiave, come numero del progetto, nome del progetto, regione, genere, unità di lavoro e breve descrizione. Usano innanzitutto il riconoscimento ottico dei caratteri (OCR) per leggere il testo e registrare dove ogni frammento appare sulla scheda, quindi impiegano grandi modelli linguistici per aiutare a standardizzare le etichette prima che esperti umani le verifichino.
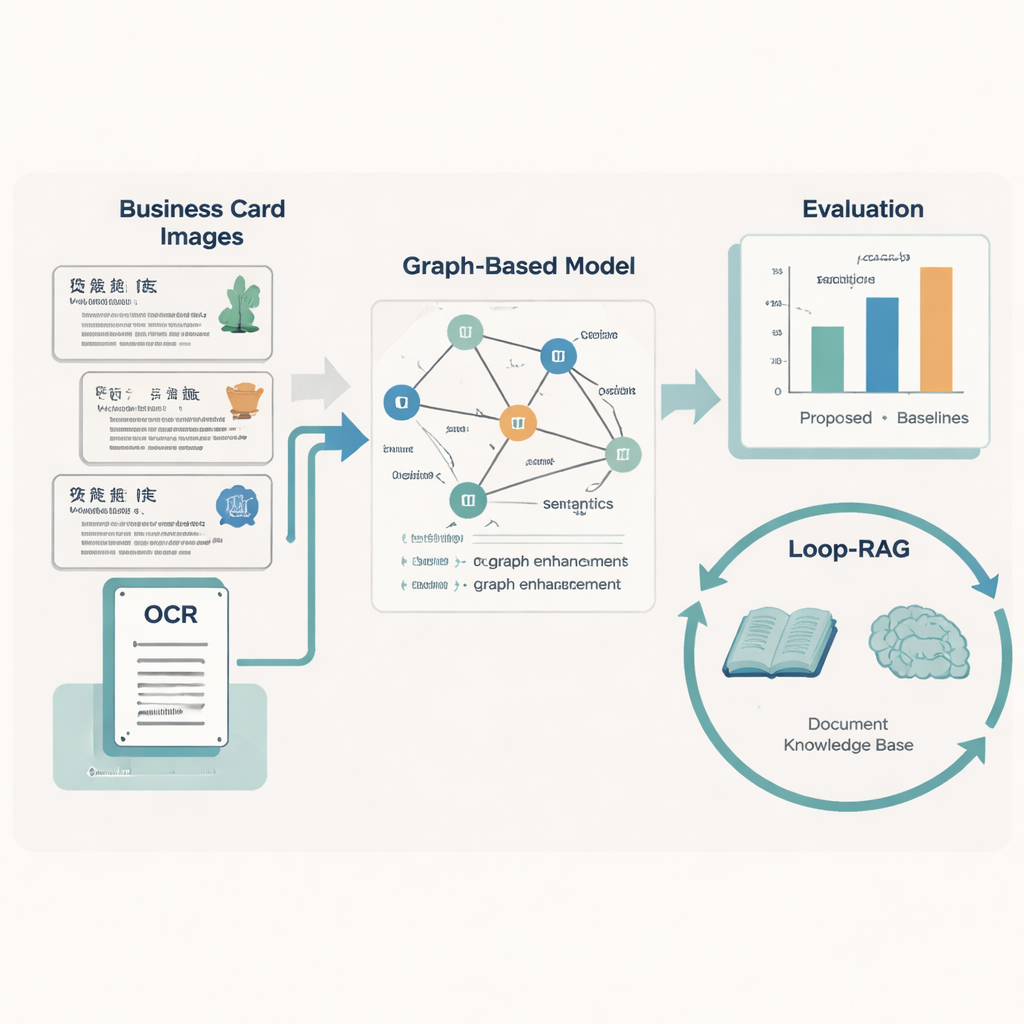
Insegnare alle macchine a leggere impaginazione e significato
Per trasformare ogni scheda in dati puliti e strutturati, il team progetta un modello “Graph-Retrieval” che imita il modo in cui le persone usano parole e impaginazione. Ogni frammento di testo su una scheda diventa un nodo in un grafo, e le relazioni spaziali tra i frammenti — sinistra, destra, sopra, sotto — formano gli archi. Una componente linguistica basata su RoBERTa e un LSTM bidirezionale apprende il significato del testo, supportata da un dizionario personalizzato di quasi 5.000 termini specifici ICH in modo che nomi di arti insoliti o espressioni locali siano trattati correttamente. Su questo si aggiunge una rete neurale su grafi che diffonde informazioni tra i nodi vicini, migliorando le previsioni su cosa rappresenti ciascun frammento di testo (per esempio decidere se un toponimo è una regione o un’unità di lavoro).
Rendere il sistema robusto alla disordine del mondo reale
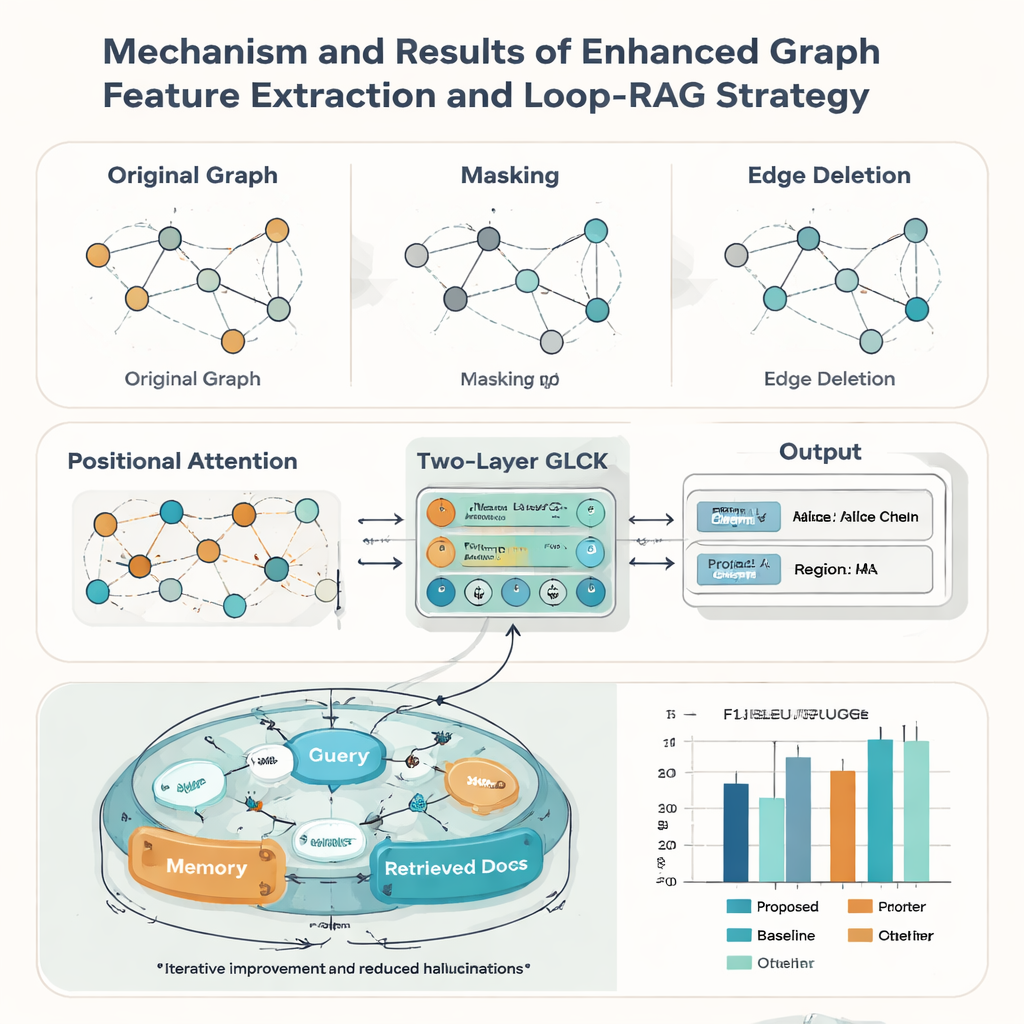
I registri del patrimonio raramente sono perfetti: le schede possono essere consumate, ritagliate o scansionate male. Per far fronte a questo, gli autori rafforzano il loro modello a grafo con tre idee prese dall’augmentation dei dati. Mascherano casualmente alcuni nodi così che il sistema impari a inferire informazioni mancanti dal contesto; eliminano casualmente alcuni archi così che possa tollerare variazioni nell’impaginazione; e aggiungono un meccanismo di attenzione posizionale che cattura l’«ordine di lettura» complessivo degli elementi sulla scheda. Insieme, questi trucchi aiutano il modello a generalizzare a molti stili e qualità di documento. Nei test contro nove metodi concorrenti noti, il nuovo approccio ottiene il valore più alto di F1 macro-media (0,928) sul dataset delle schede ICH e guida anche su cinque benchmark pubblici di documenti, suggerendo che è utile in modo ampio oltre le applicazioni sul patrimonio.
Q&A più intelligente con retrieval a ciclo
Riconoscere il testo è solo metà della storia; il secondo contributo dell’articolo è una strategia Loop-RAG (Loop Retrieval-Augmented Generation) che lavora con grandi modelli linguistici come GPT-4, Llama e ChatGLM. I sistemi tradizionali retrieval-augmented recuperano documenti di contesto una sola volta e poi generano una risposta, che può comunque essere incompleta o errata. Al contrario, Loop-RAG aggiunge un ciclo interno che verifica ripetutamente se il modello linguistico ha informazioni sufficienti per la risposta corrente e, in caso contrario, innesca un’altra ricerca mirata in una base di conoscenza ICH vettorializzata. Un ciclo esterno studia quindi molte interazioni passate per apprendere quali percorsi di retrieval e stili di prompt funzionano meglio, riducendo gradualmente ricerche inutili ed errori fattuali.
Dai registri grezzi a racconti culturali affidabili
Utilizzando questo framework combinato, il sistema può creare automaticamente brevi rapporti su un erede — riassumendo la sua arte, regione, opere rappresentative e stato — e rispondere a migliaia di domande fattuali su persone e pratiche. Misurato con punteggi standard di qualità linguistica come BLEU, METEOR e ROUGE, Loop-RAG con GPT-4 supera sia i modelli linguistici semplici sia configurazioni di retrieval più elementari, ottenendo anche la migliore accuratezza (F1 fino a 0,941) nelle domande e risposte, anche quando vengono forniti solo pochi esempi. Per un lettore non specialista, questo significa che future piattaforme per il patrimonio culturale potrebbero offrire spiegazioni interattive e affidabili delle arti tradizionali su richiesta, trasformando record digitali sparsi in storie ricche e navigabili che aiutano a mantenere le tradizioni viventi visibili e valorizzate.
Citazione: Wang, R., Zhang, X., Liu, Q. et al. Visual information identification and Q&A of intangible cultural heritage inheritors by using enhanced Graph-Retrieval framework. npj Herit. Sci. 14, 113 (2026). https://doi.org/10.1038/s40494-026-02384-z
Parole chiave: patrimonio culturale immateriale, estrazione di informazioni, reti neurali su grafi, retrieval-augmented generation, humanities digitali