Clear Sky Science · it
Ricostruzione 3D ad alta fedeltà del patrimonio culturale tramite super-risoluzione e Gaussian splatting progressivo
Perché i reperti digitali più nitidi contano
Musei e archeologi di tutto il mondo stanno correndo per creare copie 3D fedeli di reperti fragili, dai vasi di porcellana ai portali dei templi. Questi sostituti digitali ci permettono di studiare, condividere e preservare i tesori culturali senza toccare gli originali. Ma nel mondo reale, le foto degli oggetti del patrimonio sono spesso scure, sfocate o scattate da angolazioni scomode, il che può portare i metodi odierni di ricostruzione 3D a produrre modelli deformati o incompleti. Questo articolo presenta un nuovo approccio che affronta il problema alla radice, sia migliorando le foto in ingresso sia stabilizzando il processo di modellazione 3D.
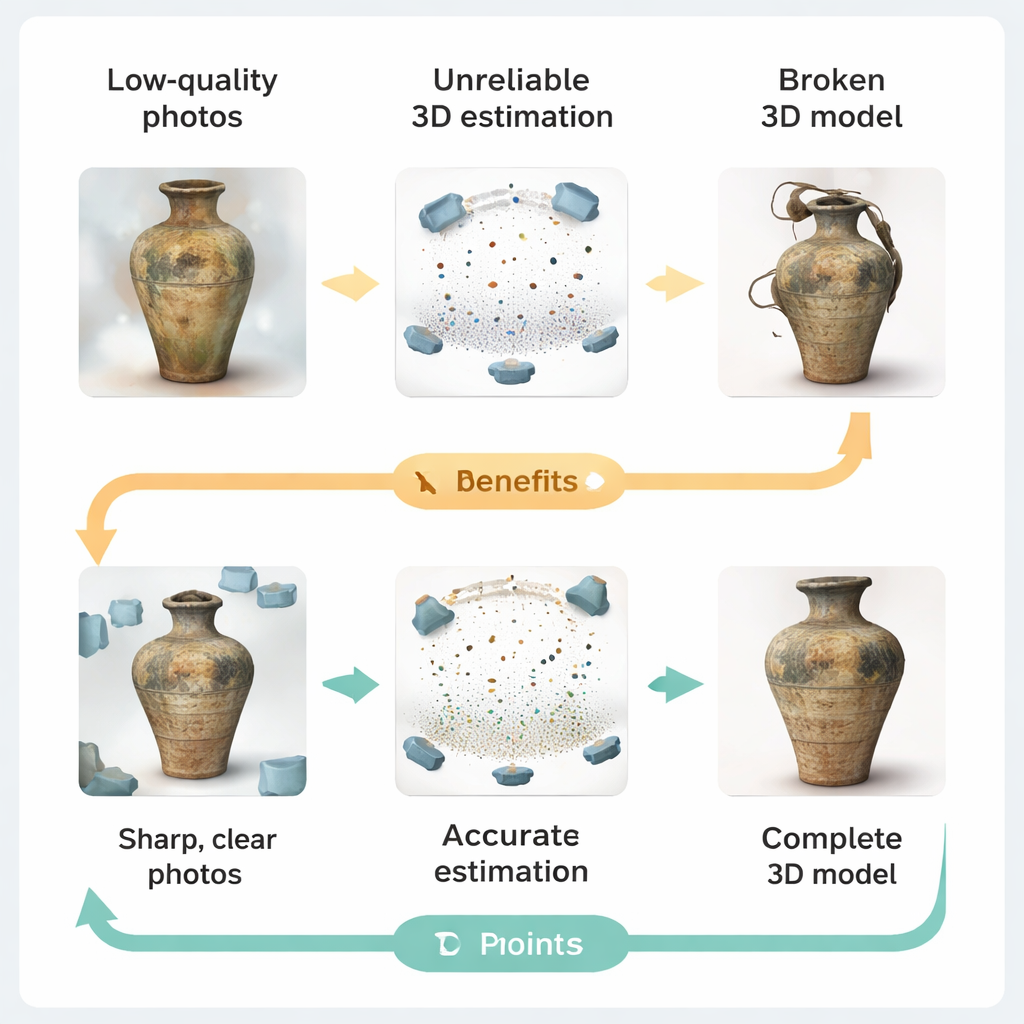
Quando le foto scadenti rompono i modelli 3D
I flussi di acquisizione 3D attuali seguono tipicamente un'idea semplice: scattare molte foto, stimare la posizione di ciascuna camera, inferire la forma dell'oggetto e infine renderizzare un modello 3D. In pratica, i siti del patrimonio raramente offrono condizioni da studio. Scarsa illuminazione, superfici consumate o irregolari, riflessi da teche di vetro e limitazioni nella posizione delle camere degradano tutte le immagini. Gli autori mostrano come questi difetti si propagano lungo la pipeline. Foto sfocate o a bassa risoluzione rendono difficile al software abbinare caratteristiche tra le viste, causando errori nelle pose delle camere e stime di profondità frammentarie. Quando queste misurazioni inaffidabili alimentano i renderer moderni basati sul "Gaussian splatting"—sistemi che costruiscono scene da migliaia di piccole macchie colorate—il risultato può essere un'ottimizzazione instabile, macchie ridondanti e geometria visibilmente distorta.
Affilare le foto con un potenziamento intelligente delle immagini
Per fermare gli errori alla fonte, gli autori costruiscono innanzitutto una rete specializzata di "super-risoluzione" che trasforma foto di patrimonio di bassa qualità in immagini più nitide e dettagliate. Anziché affidarsi a un unico tipo di elaborazione, la rete combina due punti di forza. Un modulo convoluzionale multi-scala si concentra sui dettagli locali—come crepe, pennellate o incisioni—osservando l'immagine a diverse dimensioni di vicinato contemporaneamente. Un modulo Transformer efficiente cattura invece pattern più ampi, come motivi ripetuti o curve lunghe che attraversano un oggetto. Un terzo componente potenzia selettivamente regioni realmente simili nell'immagine mentre sopprime il rumore, in modo che le texture deboli vengano chiarite anziché sfocate. Insieme, questi elementi producono immagini ad alta risoluzione che preservano sia gli ornamenti fini sia la struttura complessiva, fornendo agli stadi 3D successivi un punto di partenza molto migliore.
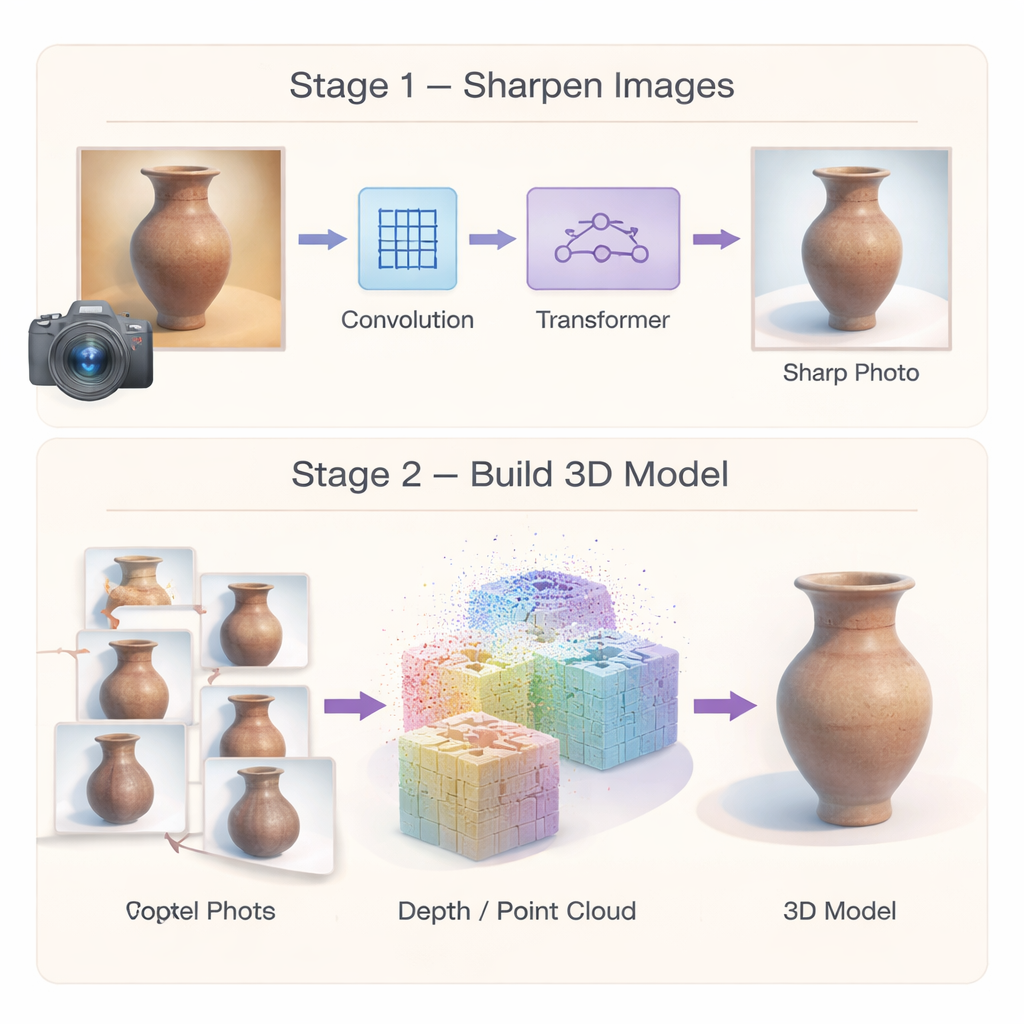
Costruire forme 3D più stabili da molte viste
Immagini migliorate da sole non bastano; la ricostruzione 3D deve essere essa stessa robusta. La seconda parte del framework ripensa come il modello 3D viene inizializzato e ottimizzato. Anziché affidarsi a un insieme sparso di punti corrispondenti, gli autori usano un metodo di matching "denso" che produce nuvole di punti ricche e pose delle camere più affidabili fin dall'inizio. Questi punti densi fungono da solido scheletro geometrico per la scena. Su questo fondamento introducono una rappresentazione ibrida: lo spazio attorno all'oggetto è diviso in celle 3D grossolane, e un decoder condiviso predice il colore e la forma dettagliata di molte piccole macchie all'interno di ciascuna cella. Poiché i parametri sono in gran parte condivisi anziché duplicati, il metodo riduce l'uso di memoria e favorisce superfici lisce e coerenti, rendendo il modello finale meno soggetto a protuberanze e buchi casuali.
Allenamento per passi delicati invece che tutto in una volta
Gli autori modificano anche il modo in cui il sistema viene allenato. Piuttosto che costringere il modello a corrispondere contemporaneamente aspetto e geometria fin dall'inizio—una ricetta per restare intrappolati in soluzioni scadenti—adottano una strategia in tre fasi. Prima, il sistema impara soltanto a riprodurre i colori delle foto in ingresso, assicurando coerenza visiva globale. Poi aggiunge gradualmente informazioni di profondità derivate dalle nuvole di punti dense, che guidano il modello verso superfici plausibili. Nella fase finale affina i dettagli su piccola scala imponendo coerenza tra patch di immagini sovrapposte da viste diverse. Testato su un nuovo dataset di patrimoni culturali contenente porcellane, mobili, oggetti d'artigianato e tessuti, così come su un benchmark standard di scene esterne complesse, questo approccio a tappe non solo migliora la qualità visiva ma riduce anche tempo di addestramento e memoria rispetto alle alternative più diffuse.
Cosa significa per la conservazione del passato
Per i non specialisti, il messaggio chiave è semplice: questo framework aiuta a trasformare fotografie da museo o da campo imperfette in repliche 3D più pulite e accurate di oggetti del patrimonio culturale, senza toccarli fisicamente. Affilando immagini di bassa qualità, partendo da uno scheletro geometrico più solido e addestrando il modello 3D in fasi attentamente controllate, il metodo produce artefatti digitali che catturano meglio sia le decorazioni fini sia la forma complessiva, usando al contempo meno risorse di calcolo. In termini pratici, questo rende più semplice per musei, conservatori e ricercatori costruire collezioni virtuali affidabili a partire da normali sessioni fotografiche, contribuendo a proteggere oggetti delicati e a condividerli ampiamente con studiosi e pubblico.
Citazione: Jia, Q., He, J. High-fidelity 3D reconstruction of cultural heritage via super-resolution and progressive Gaussian splatting. npj Herit. Sci. 14, 84 (2026). https://doi.org/10.1038/s40494-026-02355-4
Parole chiave: digitalizzazione del patrimonio culturale, ricostruzione 3D, super-risoluzione delle immagini, Gaussian splatting, conservazione digitale