Clear Sky Science · it
Geo-TCAM: un metodo di didascalia per Thangka che integra topic modeling con attenzione spaziale guidata dalla geometria
L'arte antica incontra la tecnologia intelligente
I dipinti Thangka – i rotoli dai colori vividi che si vedono in molti templi tibetani – sono ricchi di minuscoli dettagli e di strati di significato religioso. Per i visitatori dei musei o gli spettatori online senza una preparazione specialistica, gran parte di quel simbolismo è difficile da comprendere. Questo studio presenta Geo‑TCAM, un sistema di intelligenza artificiale progettato per generare automaticamente descrizioni ricche e accurate delle immagini Thangka, aiutando persone in tutto il mondo a comprendere e preservare meglio questo patrimonio culturale unico.
Perché le immagini Thangka sono difficili per i computer
A differenza delle foto di tutti i giorni, le opere Thangka sono intenzionalmente dense e simboliche. Un singolo dipinto può contenere una divinità centrale, dozzine di figure minori, bordi decorati e gesti delle mani, oggetti, colori e pose specifiche, ognuno con un valore religioso. I programmi standard di generazione di didascalie spesso se la cavano bene con scene semplici come “un cane su una spiaggia”, ma qui incontrano difficoltà: possono riconoscere il Buddha principale ma non vedere se tiene una ciotola o una spada, interpretare male la postura o confonderlo con un’altra divinità dall’aspetto simile. Tali errori non sono banali: possono ribaltare la storia e la dottrina che il dipinto intende trasmettere, compromettendone il valore educativo e culturale.
Un nuovo progetto per descrivere immagini sacre
Geo‑TCAM affronta questi problemi combinando tre idee: caratteristiche visive multi‑livello, conoscenza tematica sull’arte Thangka e attenzione guidata dalla geometria verso aree chiave come i volti. Innanzitutto usa una rete profonda (ResNet50) per analizzare ogni immagine su più livelli contemporaneamente: gli strati medi catturano contorni, trame e forme semplici, mentre gli strati più profondi riepilogano la composizione complessiva. Fusione questi livelli permette al modello di notare sia i dettagli fini come gli ornamenti sia la disposizione generale di sfondo e figure, offrendo una comprensione visiva più ricca rispetto ai sistemi precedenti che si concentravano su un unico livello. 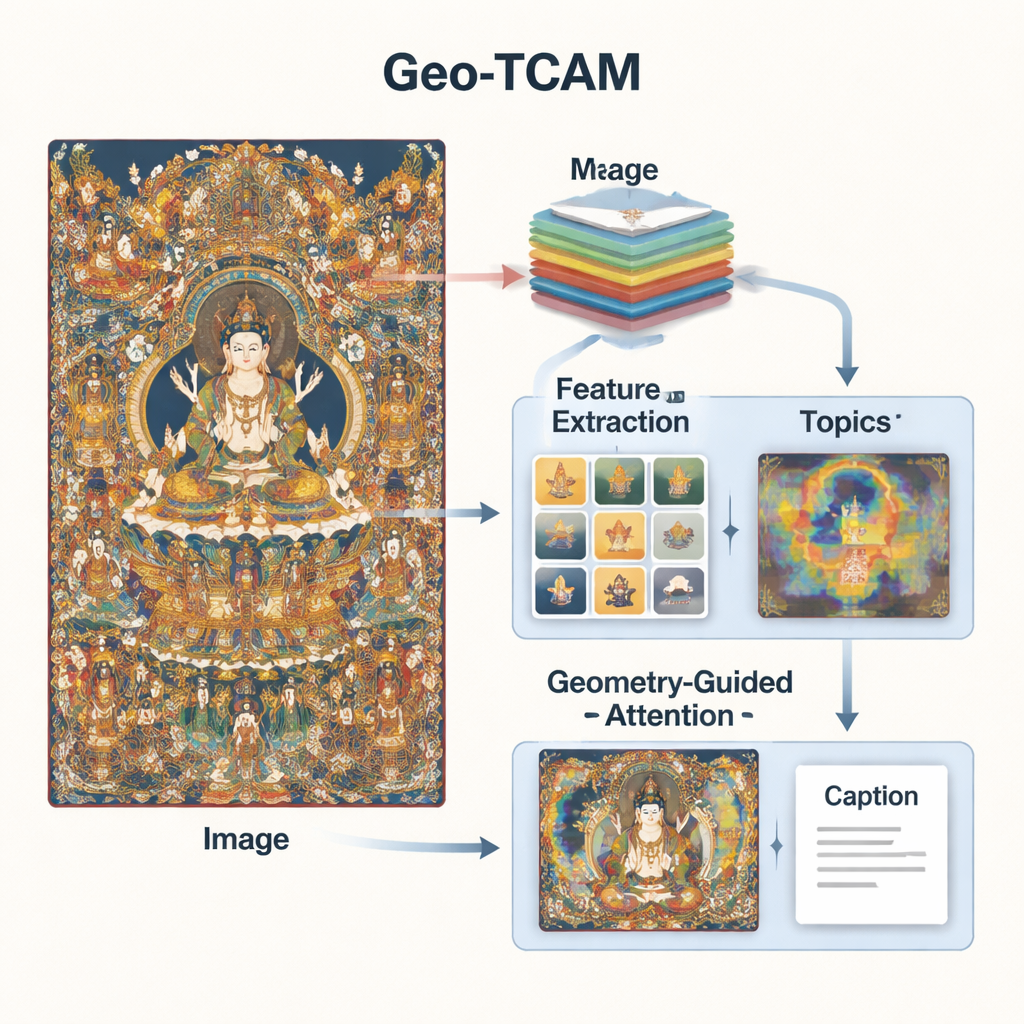
Insegnare al modello i “temi” Thangka
La sola visione non basta; il sistema ha anche bisogno di una certa conoscenza del linguaggio e dei temi Thangka. Per fornire questo, i ricercatori hanno addestrato un modello di topic su migliaia di descrizioni Thangka scritte da esperti. Questo modello raggruppa le parole in una serie di temi ricorrenti – per esempio, quelli relativi a Buddha, Bodhisattva, troni di loto, strumenti rituali o divinità protettrici. Per ogni nuova immagine, Geo‑TCAM stima quali temi sono più rilevanti e miscela quell’informazione con le caratteristiche visive. Un meccanismo di attenzione evidenzia quindi le regioni dell’immagine che corrispondono meglio ai temi probabili. In pratica, la conoscenza a priori su quali oggetti e simboli tendono ad apparire insieme orienta l’IA verso descrizioni più significative e culturalmente consapevoli.
Lasciare che l’IA “guardi” dove conta davvero
La terza innovazione è un modulo di attenzione spaziale facciale guidata dalla geometria (GFSA). Le composizioni Thangka solitamente collocano il volto della figura principale in regioni approssimativamente prevedibili del dipinto. Geo‑TCAM utilizza semplici strumenti di rilevamento dei contorni per individuare quest’area e le mani e la postura circostanti, quindi applica un meccanismo di attenzione dedicato che aumenta l’influenza di questi pixel nella formazione della didascalia. Questa strategia “localizza prima, guida dopo” aiuta a prevenire l’errata identificazione precoce della divinità centrale, che altrimenti determinerebbe una cascata di errori testuali su gesti, attributi e status. Le mappe di calore visive mostrano che con GFSA il modello si concentra in modo più netto sul volto della figura principale e sugli oggetti chiave, pur mantenendo il monitoraggio dei motivi importanti di sfondo. 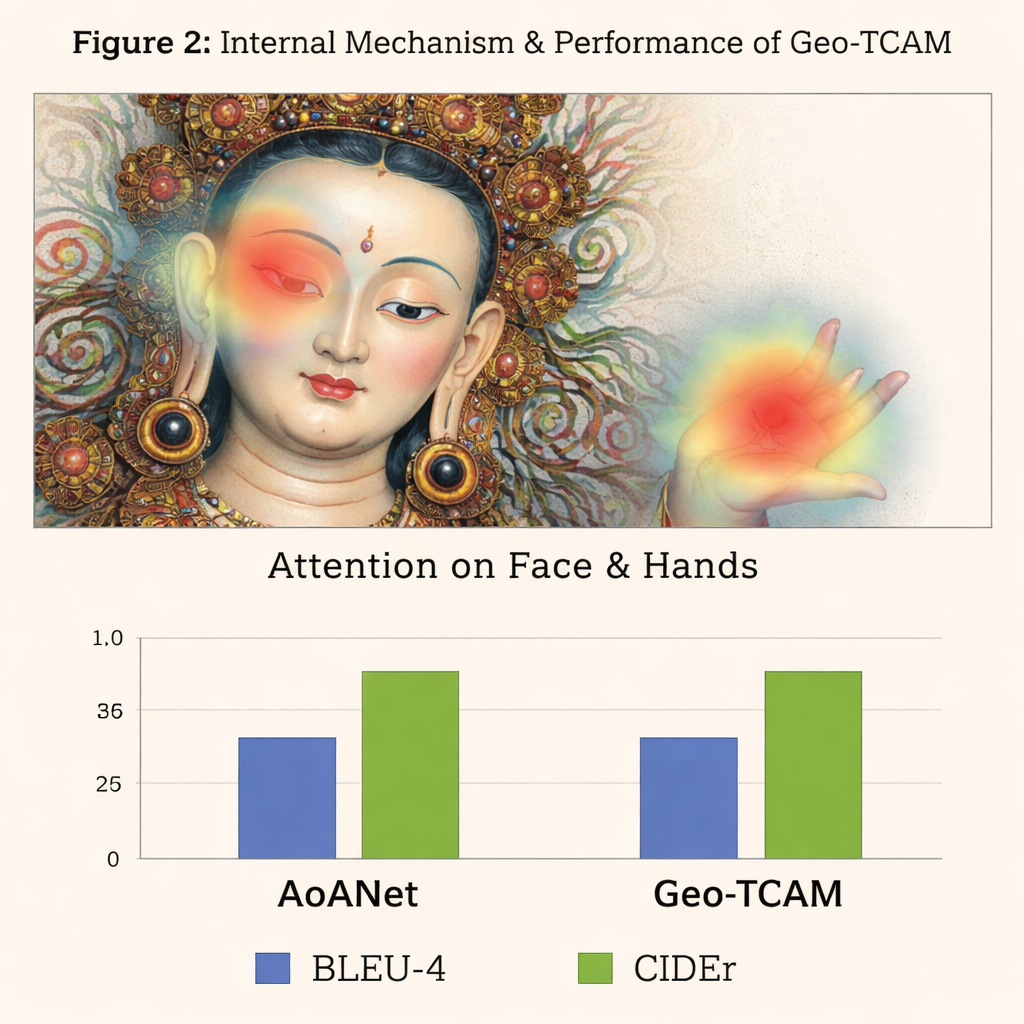
Quanto bene funziona Geo‑TCAM?
Per verificare il loro approccio, gli autori hanno costruito un dataset specializzato D‑Thangka di quasi 4.000 immagini accuratamente annotate, ciascuna con descrizioni dettagliate scritte da esperti. Su questo dataset, Geo‑TCAM ha superato nettamente diversi forti sistemi di didascalia, inclusi il popolare AoANet e grandi modelli visione‑linguaggio. A seconda della metrica, i suoi punteggi sono migliorati fino a circa il 120% rispetto alla baseline, e i valutatori umani hanno preferito in larga misura le sue didascalie per accuratezza, fluidità e ricchezza di dettagli. Importante, quando lo stesso modello è stato valutato su una raccolta standard di foto di uso quotidiano (il dataset COCO), è rimasto competitivo con i metodi di punta, dimostrando che il suo design è potente ma ancora di uso generale.
Cosa significa per il patrimonio e oltre
Per i non esperti, il messaggio principale è che Geo‑TCAM può trasformare i complessi dipinti Thangka in narrazioni chiare e informative che evidenziano chi è raffigurato, cosa sta facendo e perché quei dettagli sono importanti. Combinando analisi visive stratificate, temi appresi da testi di esperti e una particolare attenzione a volti e gesti, il sistema allinea le sue didascalie molto più strettamente al modo in cui gli specialisti umani leggono queste opere. Sul lungo periodo, strumenti di questo tipo potrebbero supportare archivi digitali, guide museali e piattaforme educative, rendendo l’arte religiosa esoterica più accessibile e aiutando conservatori e studiosi a documentare e proteggere tesori culturali fragili.
Citazione: Zhong, P., Hu, W., Zhao, Y. et al. Geo-TCAM: a Thangka captioning method integrating topic modeling with geometry-guided spatial attention. npj Herit. Sci. 14, 87 (2026). https://doi.org/10.1038/s40494-026-02343-8
Parole chiave: Didascalia di immagini Thangka, IA per il patrimonio culturale, attenzione visiva, topic modeling, conservazione dell'arte