Clear Sky Science · it
Costruzione del corpus delle Ventiquattro Storie, antico-moderno, etichettato per categorie grammaticali
Perché le antiche cronache contano nell’era dell’IA
Per più di due millenni, gli storici cinesi hanno registrato guerre, corti, carestie e la vita quotidiana nella massiccia serie nota come le Ventiquattro Storie. Oggi questi classici vengono riscoperti non solo dagli studiosi, ma anche dai computer. Questo studio descrive come i ricercatori hanno trasformato queste cronache antiche e le loro traduzioni in cinese moderno in un database linguistico attentamente etichettato. Questa risorsa può aiutare l’intelligenza artificiale a leggere, tradurre e analizzare testi storici con maggiore accuratezza — e rendere il passato lontano molto più accessibile al pubblico.
Dai volumi impolverati al testo digitale
Il progetto inizia con un compito di base ma arduo: trasformare milioni di caratteri stampati in testo digitale pulito e accurato. Il team ha utilizzato due fonti — un’edizione moderna definitiva delle Ventiquattro Storie e una grande raccolta online — per alimentare un sistema di riconoscimento ottico dei caratteri. Hanno poi rimosso con cura passaggi corrotti, corretto caratteri erroneamente letti e eliminato rumore come intestazioni e piè di pagina. Il risultato è stato un insieme parallelo di file, uno in cinese antico e uno in cinese moderno, che rispecchiavano fedelmente i libri originali ma erano pronti per l’analisi computazionale. 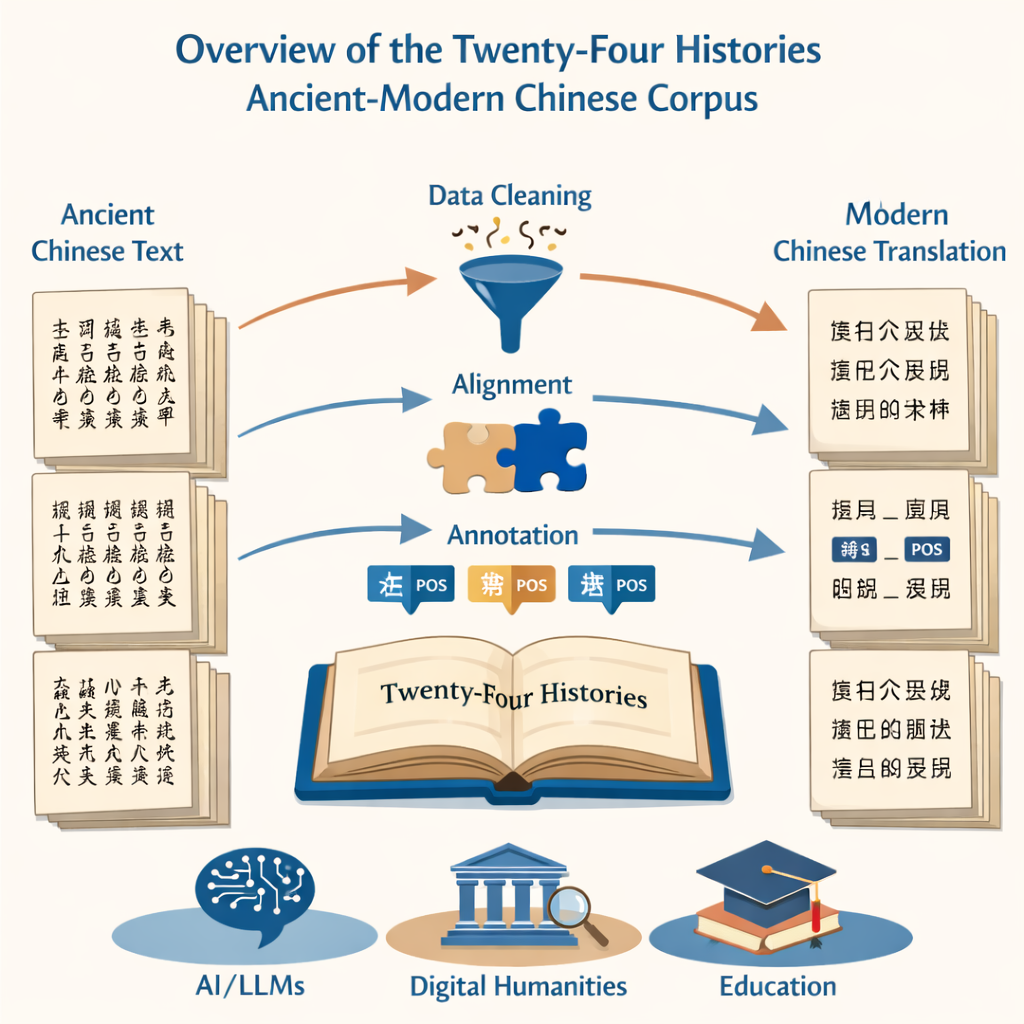
Mettere in coppia frasi antiche e moderne
Poiché l’obiettivo era confrontare come la lingua è cambiata nel tempo, era essenziale allineare le versioni antiche e moderne frase per frase. I ricercatori hanno impiegato software di allineamento specializzato per abbinare prima i paragrafi e poi suddividerli in frasi corrispondenti. Gli strumenti automatici hanno fatto il lavoro pesante, ma esperti umani hanno dovuto rivedere ogni coppia suggerita, dato che la grammatica del cinese antico può essere molto diversa da quella del cinese moderno. Dove il software ha inciampato — dividendo un pensiero nel punto sbagliato o interpretando male un carattere — gli annotatori hanno controllato le pagine scansionate originali e corretto il testo digitale in modo che ogni frase antica corrispondesse pulitamente alla sua controparte moderna.
Insegnare ai computer a vedere la grammatica
Oltre alla semplice trascrizione, il nucleo del progetto è l’etichettatura grammaticale. Ogni parola sia nei testi antichi sia in quelli moderni è stata marcata con un tag di parte del discorso, che indica se, per esempio, si tratta di un sostantivo, di un verbo o di una parola temporale. Poiché non esiste uno standard unico per il cinese antico, il team ha ancorato il proprio sistema alle linee guida nazionali moderne, poi le ha adattate agli usi antichi. Hanno ideato uno schema di 22 tag che include un’etichetta speciale per usi verbali unicamente antichi come “far vivere” o “morire per la patria”. Una rete neurale personalizzata — costruita su un modello linguistico per testi antichi con strati per l’etichettatura di sequenze — ha prodotto tag iniziali, poi verificate e corrette da un ampio gruppo di dottorandi ben addestrati. Severi test di accordo tra annotatori hanno mostrato un’elevata coerenza, confermando che il corpus finale etichettato è sia ampio sia affidabile.
Cosa rivela la nuova lente
Con il corpus etichettato a disposizione, gli autori hanno esaminato alcuni dei modelli che mette in luce. Nel cinese antico dominano le parole monosillabiche (a carattere singolo), riflettendo uno stile di scrittura notoriamente compatto, mentre il cinese moderno preferisce parole bisillabiche (a due caratteri). Gli elementi antichi più comuni sono piccole particelle grammaticali come “之” e “以”, mentre verbi e sostantivi ordinari insieme costituiscono circa metà di tutte le parole in entrambe le epoche. I dati mostrano anche quali parole tendono ad apparire insieme — per esempio strutture che descrivono funzionari, eserciti o missioni diplomatiche. Confrontando i tag nelle coppie antico–moderno, il team ha tracciato come le funzioni si siano spostate nel tempo: alcune preposizioni e avverbi antichi corrispondono oggi a verbi moderni completi, e alcuni verbi si sono consolidati in titoli fissi o termini legali. Un caso di studio ha estratto tutti i nomi di luogo e li ha mappati per vedere dove si concentrano nelle diverse dinastie, rivelando come i centri politici ed economici si siano spostati dal nord-ovest verso la regione del basso Yangtze e oltre. 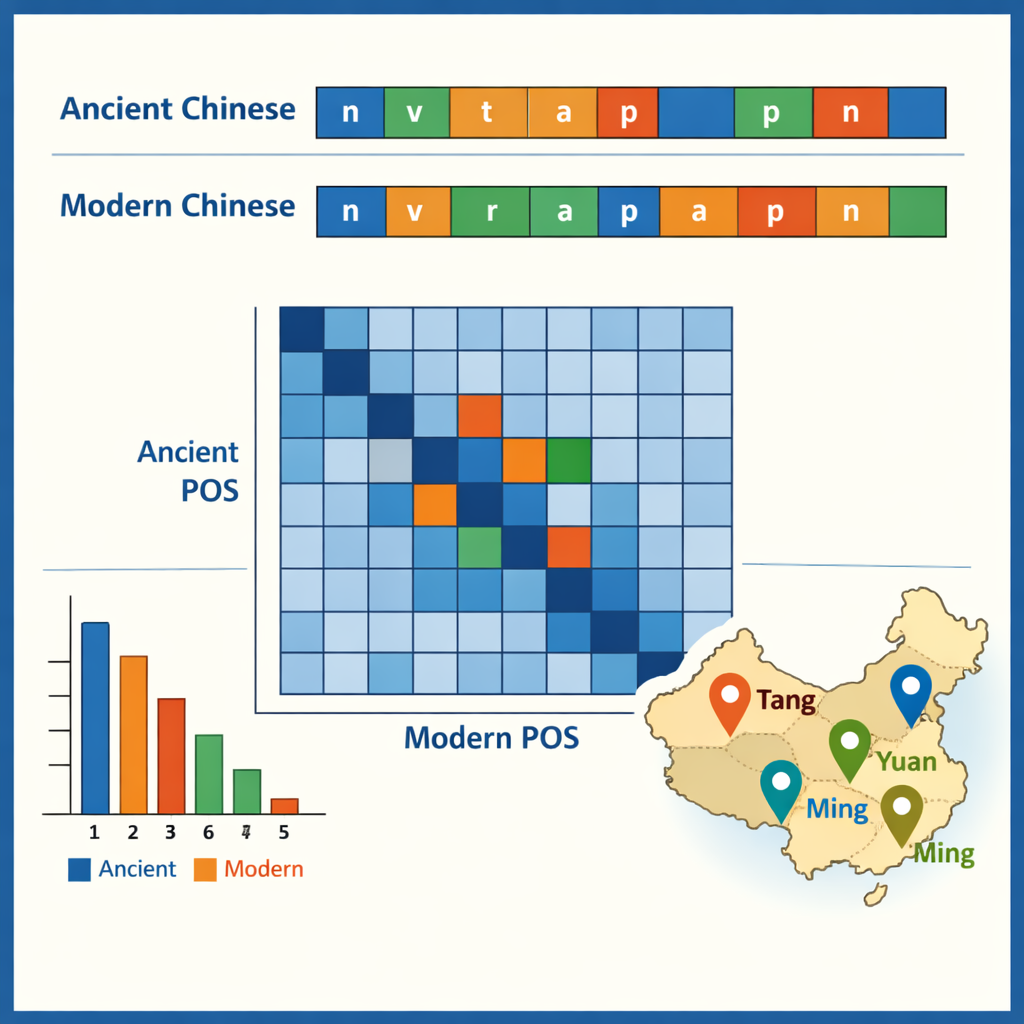
Portare il passato nel futuro digitale
In termini semplici, questo progetto trasforma un’imponente parete di prosa classica in dati strutturati che sia gli esseri umani sia le macchine possono percorrere. Per storici e linguisti, fornisce uno strumento potente per tracciare come parole, grammatica e persino confini statali si siano evoluti nei secoli. Per gli sviluppatori di IA, offre materiale di addestramento di alta qualità per costruire modelli linguistici che possano davvero gestire il cinese classico invece di trattarlo come un ammasso di caratteri. E per studenti e lettori generali, l’affiancamento frase per frase di testo antico e moderno abbassa la barriera alla lettura dei classici. Etichettando e allineando con cura le Ventiquattro Storie, gli autori hanno creato un ponte dai rotoli manoscritti del passato ai sistemi intelligenti del presente e del futuro.
Citazione: Ye, W., Xu, Q., Zhao, X. et al. Construction of the twenty-four histories ancient-modern part-of-speech tagged corpus. npj Herit. Sci. 14, 97 (2026). https://doi.org/10.1038/s40494-026-02309-w
Parole chiave: corpus cinese antico, etichettatura delle parti del discorso, umanesimo digitale, testi paralleli, cambiamento linguistico storico