Clear Sky Science · he
תשומת לב ויזואלית אנושית ואלגוריתמית במשימות נהיגה
מדוע זה חשוב לנהיגה יומיומית
ככל שמכוניות הופכות לאוטומטיות יותר, שאלה מרכזית נשארת: האם מערכות נהיגה עצמאיות באמת "רואות" את הדרך כפי שאנשים רואים אותה? המחקר בוחן כיצד נהגים אנושיים ובינה מלאכותית ממקדים את תשומת הלב הויזואלית שלהם בתנועה, ומראה כי הוספה מדודה של קטע תשומת לב דמוי-אנושי יכולה להפוך אלגוריתמים לנהיגה לחכמים ובטוחים יותר — מבלי להסתמך על מודלים עצומים וצרכני-אנרגיה.
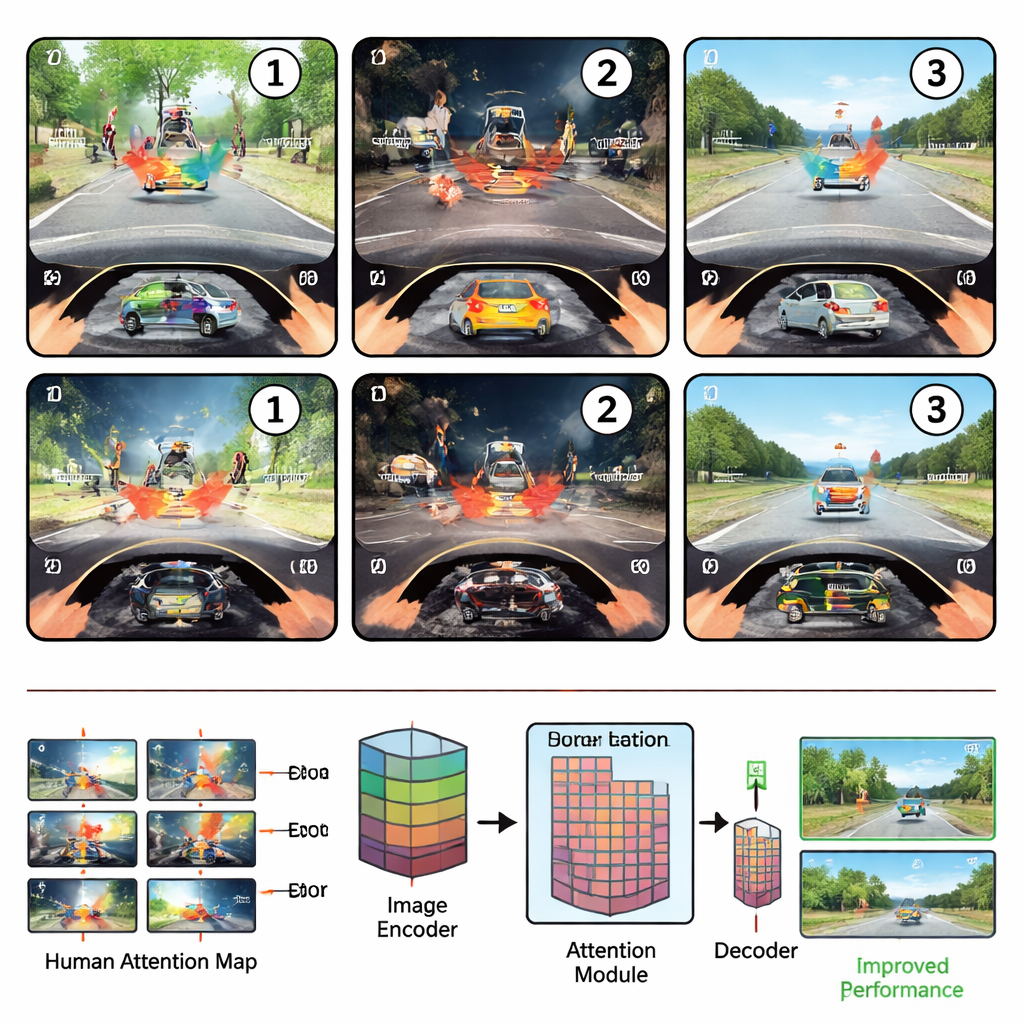
כיצד העיניים האנושיות נעות בכביש
החוקרים הניחו תחילה נהגים חסרי ניסיון ובעלי ניסיון בסביבה מדומה למעקב אחר תנועות עיניהם בזמן שביצעו שלוש משימות בטיחות נפוצות: זיהוי סכנות, שיפוט האם בטוח לפנות או להחליף נתיב, וזיהוי עצמים לא שגרתיים ומוצאים בחוץ. הם גילו שהתשומת לב של הנהגים נעה בקצב תלת-שלבי אמין. בשלב הסריקה (scanning), מיד לאחר הופעת הסצנה, העיניים סורקות ברוחב התמונה, מונעות בעיקר לפי מיקום האובייקטים. בשלב הבדיקה (examining), התשומת לב נעצרת על האזור העשיר במידע ביותר — למשל הולך רגל חוצה או רכב חוסם — ובוחנת את פרטיו ומשמעותו. לבסוף, בשלב ההערכה מחדש (reevaluating), הנהגים משווים את האובייקט המרכזי לאחרים, מנפים את המבט הלוך ושוב כדי לאשר את החלטתם.
לאן המכונות מביטות מול לאן אנשים מביטים
הצוות בנה מודל למידת עומק מבוסס תשומת לב לסצנות נהיגה והשווה את "מפות התשומת לב" הפנימיות שלו לאלה שנגזרו ממעקב עיניים אנושי. אימון המודל על זיהוי עצמים כללי הפך את תשומת הלב שלו למעט יותר דמוית-אנושית, אך כוונון עדין למשימות נהיגה ספציפיות לעיתים הסטה אותו מהתבניות האנושיות, במיוחד בשלב העשיר במשמעות של הבדיקה. בסך הכול, המתאמים בין תשומת הלב האנושית לאלגוריתמית נותרו מתונים, מה מרמז שמערכות הנהיגה הנוכחיות מתקשות לגלות את עקרונות הארגון שמנחים לאן אנשים מסתכלים ולמה.
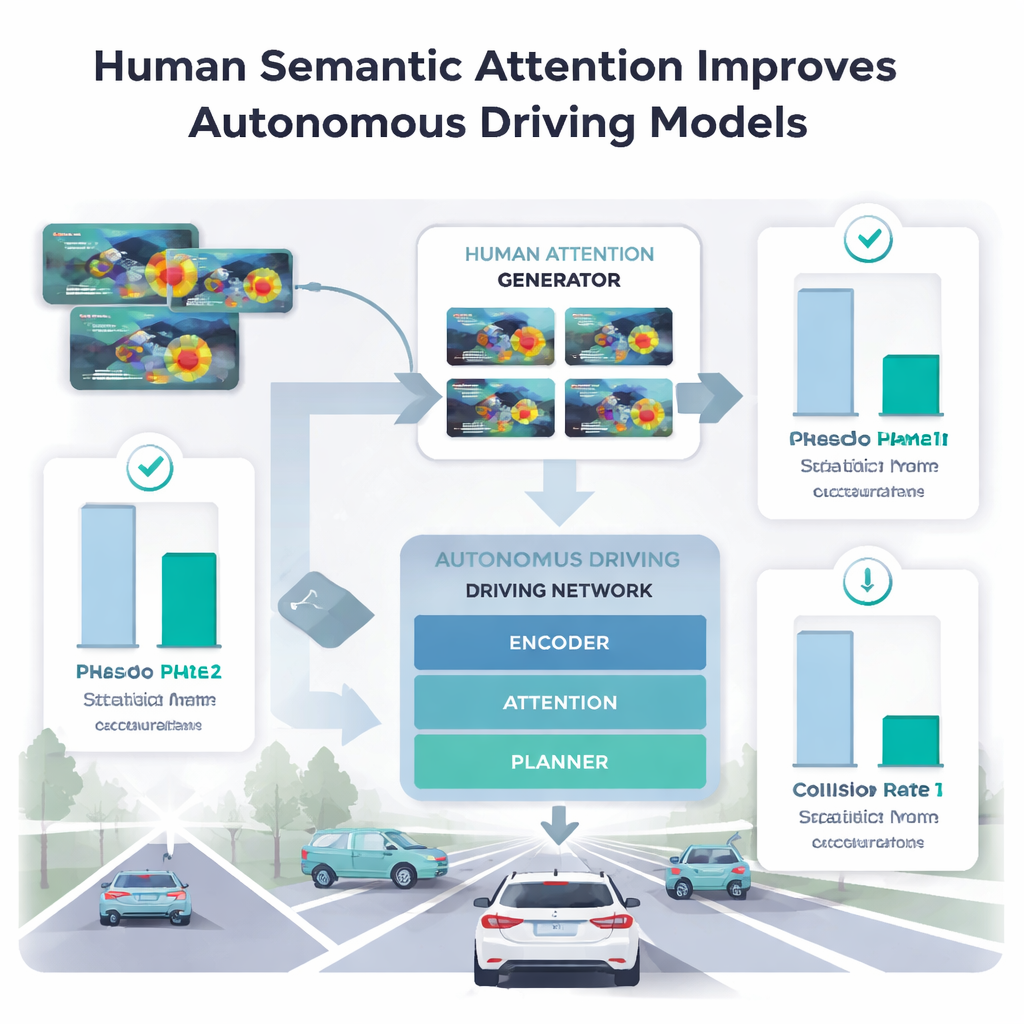
ללמד מכוניות לשאול תשומת לב אנושית
כדי להבין אילו חלקים בתשומת הלב האנושית אכן מסייעים למכונות, המחברים הזינו שלבים שונים של מבט אנושי למודל הנהיגה שלהם. איסוף נתוני מעקב עיניים ישירות עבור מיליוני תמונות אינו מעשי, לכן הם אימנו "מחולל תשומת לב אנושית" נפרד על מדגם קטן של חמישה נהגים בלבד. המחולל הזה למד לחזות מפות חום של תשומת לב דמוית-אנושית לסצנות חדשות. כאשר מודל הנהיגה הראשי השתמש רק בשלב המרחבי וההתחלתי של הסריקה, הביצועים שלו בזיהוי חריגות ותכנון מסלולים לעיתים הידרדרו או הניבו מסלולים שנראו בטוחים אך היו פגיעים להתנגשויות. לעומת זאת, כשהוא השתמש בשלב הבדיקה — שבו האנשים מתרכזים באזור המשמעותי ביותר — הדיוק השתפר מעבר לשיטות קודמות שהשתמשו במבט לאורך זמן מלא, ושיעורי ההתנגשויות במשימות תכנון ירדו.
מה שמודלים גדולים של ראייה-שפה עדיין מפספסים
החוקרים גם בחנו מודלים גדולים של ראייה-שפה שמגבשים תשובות לשאלות נהיגה או מייצרים תיאורים צפופים לסצנות רחוב תלת-ממדיות. למשימת שאלות ותשובות המדגישה חשיבה ברמת-על, הוספת תשומת לב אנושית הועילה במעט ולעיתים אף פגעה, מה שמרמז שמודלים אלו כבר מחזיקים הרבה מהידע המופשט הנדרש. אך למשימת תיוג דורשת ומדויקת שמחייבת התאמת מילים מדויקות לעצמים מסוימים, תשומת הלב האנושית בשלב הבדיקה העניקה שיפורים משמעותיים. זה מצביע על כך שמודלים גדולים עשויים להצליח בהסקה כללית, ועדיין להיכשל כאשר יש צורך לקשר במדויק מילים לנקודות המדויקות בסצנה מואמצת — פער שתשומת הלב האנושית יכולה לסייע לצמצמו.
מה משמעות הדבר לרכבים אוטומטיים בטוחים יותר
במלים פשוטות, המחקר טוען שההבדל האמיתי בין בני אדם לבין בינה מלאכותית לנהיגה כיום אינו רק לאן אנו מביטים, אלא כיצד אנו שופטים מיד מה "חשוב" בסצנה. אותו התפרצות קומפקטית של תשומת לב סמנטית — כשאנו בוחנים בקפידה את האזור היחיד שמכריע אם המצב בטוח או מסוכן — מתבררת להיות בדיוק האות שלרבים מהאלגוריתמים חסר. על-ידי למידה לחקות את השלב הזה מתוך כמות קטנה של נתוני מעקב עיניים, מערכות הנהיגה יכולות לרכוש הבנה דמוית-אנושית של סצנות כביש מבלי להסתמך רק על מודלים גדולים ויקרים יותר. ה"קיצור הסמנטי" הזה יכול להיות דרך יעילה להפוך את המכוניות האוטומטיות העתידיות לאמינות יותר בתנאים המסורבלים והבלתי-צפויים של התנועה בעולם האמיתי.
ציטוט: Zheng, C., Li, P., Jin, B. et al. Human and algorithmic visual attention in driving tasks. npj Artif. Intell. 2, 23 (2026). https://doi.org/10.1038/s44387-026-00079-1
מילות מפתח: נהיגה אוטונומית, תשומת לב ויזואלית, מעקב עיניים אנושי, מודלים של ראייה-שפה, בטיחות תנועה