Clear Sky Science · he
תפקידם של מודלים שפתיים גדולים בטיפול במצבי חירום: מחקר השוואתי מקיף
מדוע זה חשוב לכל מי שעשוי לבקר בחדר מיון
חדרי המיון עמוסים יותר מתמיד, עם זמני המתנה ארוכים יותר וכוח אדם מצומצם לטיפול במספר הולך וגדל של מטופלים במחלה קשה. המחקר הזה שואל שאלה שמשפיעה על רבים: האם מערכות הבינה המלאכותית המודרניות, הנקראות מודלים שפתיים גדולים, יכולות לסייע בבטחה לרופאים ולמאחיות לפעול מהר וחכם יותר במחלקת המיון? על ידי בחינת מספר מערכות מובילות בסדרת מבחנים רפואיים ומקרים מדומים במיון, החוקרים בוחנים עד כמה כלים אלה קרובים להפוך ל"שותפים" אמינים בעזרה בטיפול דחוף.
חדרי מיון תחת לחץ כבד
המאמר נפתח בתיאור משבר גובר בטיפול במצבי חירום, במיוחד בארצות הברית. הזדקנות האוכלוסייה וגידול במחלות כרוניות מניעים שיאים במספר הביקורים בחדרי מיון, שכבר הגיעו לכ־155 מיליון בשנת 2022 בלבד. במקביל, בתי חולים מתמודדים עם מחסור חמור באחיות ורופאים, ומספר המיטות לנפש ירד בעשורים האחרונים. מערכת בריאות מפורקת מקשה על תיאום הטיפול, ומגבירה את הסיכון לעיכובים ושגיאות. על רקע זה טוענים המחברים כי נדרשים בדחיפות כלים חדשים שיעזרו לצוותים לקבוע טרייאג', לקבל החלטות מהירות ולתעד טיפול מבלי להכביד על עומס עבודתם.
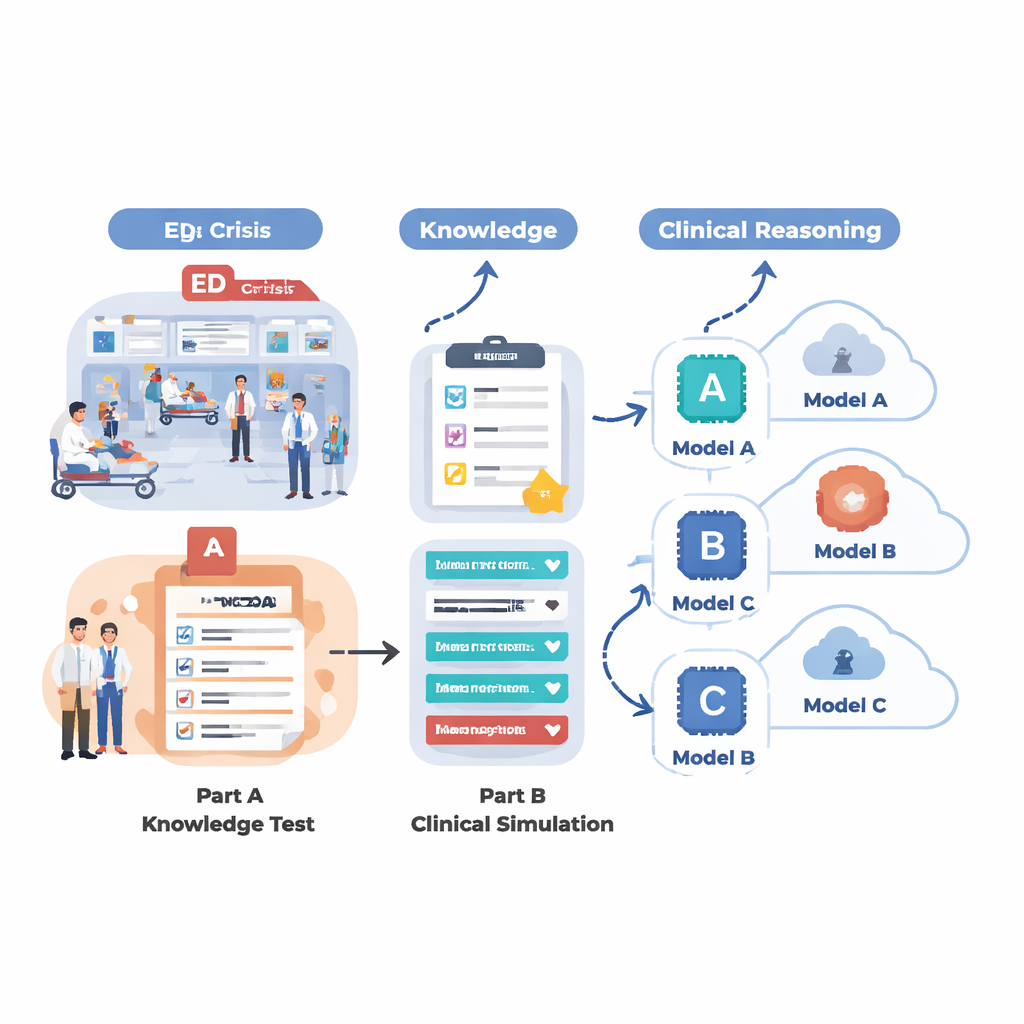
כיצד החוקרים בחנו בינה מלאכותית רפואית
כדי לבדוק מה מערכות הבינה של היום יכולות לעשות בסביבה הדומה למיון, הצוות תכנן הערכה בשני חלקים. ראשית, הם בחנו 18 מודלים שפתיים שונים על מאגר גדול של שאלות רב־ברירתיות מתוך MedMCQA, מערך נתונים בסגנון מבחנים רפואיים המכסה 12 תלונות שכיחות במיון כגון כאב בחזה, קוצר נשימה, כאב ראש וכאב בטן. שלב זה מדד ידע רפואי בסיסי: האם ה־AI יכול לבחור את התשובה הנכונה מתוך ארבע אפשרויות על פני אלפי שאלות? שנית, הם לקחו את חמשת המודלים החזקים ביותר והציבו אותם מול 12 מקרים מציאותיים במיון, שלב אחר שלב, כפי שרופא היה עושה. בכל מקרה חויב ה־AI לתמצת את המקרה, להעניק ציון דחיפות בטרייאג', להציע שאלות המשך חשובות, להציע צעדי ניהול ולרשום אבחנות אפשריות ככל שנחשפו נתונים נוספים (סימנים חיוניים, היסטוריה, ממצאי בדיקה, תוצאות מעבדה והדמיה).
אילו מודלים ידעו עובדות — ואילו יכלו להסיק מסקנות
בהיבט של שינון עובדות טהורות, כמה מודלים הציגו ביצועים מרשימים. מערכת מותאמת שנקראה LLaMA 4 Maverick קיבלה דיוק כולל של כ־91 אחוז בשאלות הרפואיות, כמעט ברצף עם LLaMA 3.1, GPT-4.5, GPT-5 ו־Claude 4. מודלים אלה היו חזקים בעקביות בעניינים שונים, מה שמרמז שמודלים מתקדמים עשויים להתקרב לתקרה של ידע רפואי בסגנון ספרי. מערכות מדור ביניים נותרו הרבה אחריהם, כאשר חלקן קיבלו ציונים הקרובים ל־60 אחוז והתקשו בתחומים מרכזיים כמו טיפול בפצעים ובעיות נשימה. עם זאת, כאשר המשימה עברה ממענה על שאלות נפרדות להסקת מסקנות בתוך סיפור חולה עשיר ומתפתח, ההבדלים הפכו חדים יותר. בסימולציות הקליניות הללו, GPT-5 בלט בבירור: הוא סיפק את הסיכומים המדויקים והמלאים ביותר, שאל את שאלות ההמשך המועילות ביותר, המליץ על צעדים הגיוניים ובטוחים, והציע את רשימות האבחנות האפשריות המקיפות והמסודרות ביותר.
חוזקות, חולשות וחששות בטיחותיים
קלינאים דירגו בקפידה את פלט כל מודל על בסיס דיוק, רלוונטיות ובטיחות. GPT-5 לא רק שזכה לניקוד הגבוה ביותר בסך הכל; הוא היה גם הדגם היחיד שביצועיו נותרו יציבים או השתפרו ככל שהמקרים נעשו מורכבים יותר, תוך שמירה על היסחויות ושגיאות חמורות מתחת לכ־2 אחוז. מודלים אחרים הציגו דפוסי חולשה שונים. חלקם נטו להחמיץ אבחנות משניות או לתת עדיפות לבעיות קלות על פני מסוכנות. אחרים הפכו זהירים או מעורפלים מדי, או נתפסו מהר מדי על אבחנה אחת. ברוב המערכות התוצאה הייתה הערכת מחלה שמרנית מדי בעת קביעה של רמות טרייאג', נטייה שעשויה לעכב טיפול דחוף אם לא יתוקנו. הממצאים מדגישים נקודה מרכזית: ידיעת עובדות רפואיות אינה זהה ליכולתה של מערכת לשלב באופן אמין עובדות אלה בתוך קבלת החלטות בטוחה ושלב־אחרי־שלב כאשר המידע חסר, מבולגן ומשתנה.

מה זה עשוי להצביע לגבי ביקורים עתידיים במיון
המחברים מסכמים כי בעוד מספר מערכות מודרניות תחרותיות זו עם זו בידע הרפואי, GPT-5 בולט במיוחד ברמת יכולת הסקת המסקנות שלו, מה שעשוי להפוך אותו לכלי תמיכה בהחלטות שימושי במחלקות מיון. הם מדגישים שמערכות אלה אינן מוכנות להחליף קלינאים או לפעול באופן עצמאי. במקום זאת, התפקיד המבטיח בטווח הקצר הוא כעוזר תחת השגחה — לסייע לאחיות טרייאג' בהערכת הדחיפות, לנסח סיכומי מטופל, להציע שאלות או בדיקות ולוודא שאבחנות מסוכנות נשקלו. המחקר גם מדגיש כי נדרש עוד מחקר בהגדרות קליניות חיות, עם אמצעי בטיחות חזקים וכללים ברורים לשימוש. עבור מטופלים, המסר הוא אופטימיות זהירה: ה־AI משתפר ביכולות החשיבה על בעיות רפואיות, אבל השימוש הבטוח שלו במיון יתבסס על עיצוב קפדני, פיקוח והמשך דגש על תמיכה — לא על החלפה — של שיקול הדעת האנושי של רופאים ואחיות.
ציטוט: Naderi, B., Liu, L., Ghandehari, A. et al. The role of large language models in emergency care: a comprehensive benchmarking study. npj Artif. Intell. 2, 24 (2026). https://doi.org/10.1038/s44387-026-00078-2
מילות מפתח: רפואה דחופה, מודלים שפתיים גדולים, תמיכה בהחלטות קליניות, טרייאג', הערכת ביצועי בינה מלאכותית רפואית