Clear Sky Science · he
תיקון שגיאות אריתמטיות של כפל-וסכימה בעיבוד-בסמוך-לזיכרון באמצעות קודי LDPC
מדוע חשוב לתקן שגיאות חישוב בזיכרון
שבבי בינה מלאכותית מודרניים דוחפים עוד מהירות ויעילות מהחומרה על ידי ביצוע חישובים ישירות בתוך הזיכרון, במקום לשנע נתונים הלוך ושוב למעבדים נפרדים. גישה זו של "עיבוד-בסמוך-לזיכרון" חוסכת אנרגיה אך יוצרת בעיה משמעותית: אי־דיוקים חשמליים זעירים יכולים להפוך ביטים מאוחסנים או לעוות אותות אנלוגיים, ולפגוע בשקט בדיוק של מטלות כמו זיהוי תמונה. המאמר מתאר שיטה חדשה לגילוי ותיקון שגיאות אלה בזמן אמת, שעוזרת לחומרת הבינה המלאכותית העתידית להישאר גם מהירה וגם אמינה.
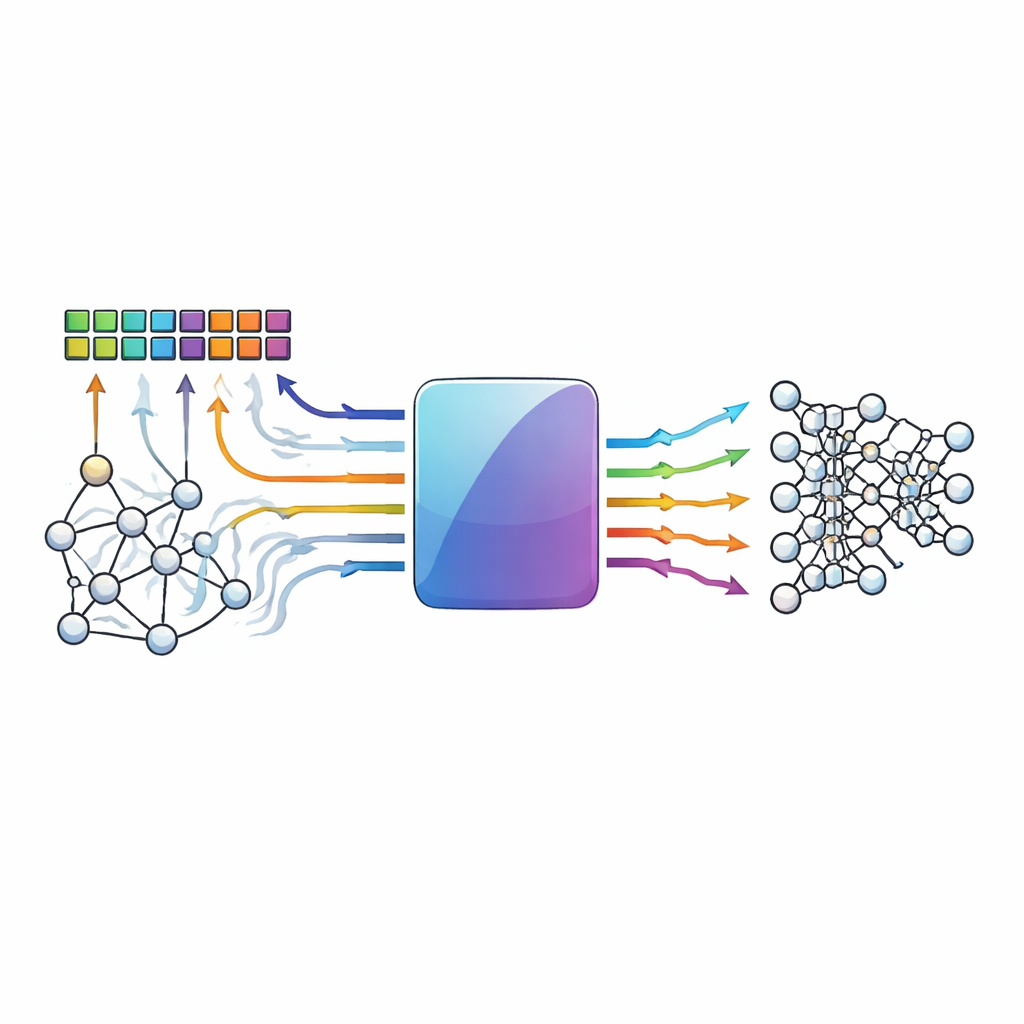
לחישוב במקום שבו הנתונים גרים
מחשבים קונבנציונליים מאטים בגלל הצורך להזיז נתונים בין הזיכרון למעבד. עיצובים של עיבוד-בסמוך-לזיכרון ממנועים צוואר בקבוק זה על ידי ביצוע פעולות כפל־וסכימה — העמוד השדרה של רשתות נוירוניות — בתוך מערכי תאים דחוסים של זיכרון. מכשירים מתקדמים כגון זיכרון חסין־התנגדות (resistive RAM) ורכיבים ממראטיביים אחרים מושכים במיוחד מכיוון שהם יכולים לאחסן ערכים רבים ולבצע חשבון בסגנון אנלוגי ביעילות גבוהה. עם זאת, האופי האנלוגי והשונות של המכשירים שמקנים להם כוח גם הופכים אותם לרועשים: תנודות תרמיות, אי־התאמות במכשירים וירידות מתח יכולים להזיז ערכים מאוחסנים או תוצאות מחושבות הרחק מהמקומות הצפויים.
כאשר תקלות זעירות מצטברות
במערכים אלה של עיבוד בתוך הזיכרון, שורות רבות של תאים מוארות יחד ותרומותיהן מסוכמות לאורך חוטים משותפים. ככל שיותר שורות משתתפות, הפגמים האישיים שלהן מצטברים ויוצרים דפוסי שגיאות שכיחים ומסובכים. במקום ביט שגוי יחיד, המעצבים רואים לעיתים קרובות שגיאות מרובות הממוקמות באותה עמודה של מטריצה או הפרוסות על פני מספר עמודות באופן שמערים קשיים על טריקים סטנדרטיים לתיקון שגיאות. קודים מקובלים מניחים בדרך כלל דפוסי שגיאה פשוטים ואורכי מילה קצרים; הם עלולים לפספס ליקויים מרובי־ביט או שלא להכיל ערכים בטבלאות החיפוש עבור קומבינציות נדירות אך מזיקות. כתוצאה מכך, דיוק המודל של רשתות נוירוניות עמוקות עלול לצנוח באופן חמור ברגע שהחומרה הבסיסית הופכת אפילו לחסרת־אמינות במידה מתונה.
רשת ביטחון דיגיטלית מסוג חדש
המחברים מציגים קוד LDPC בצפיפות נמוכה שאינו־בינארי (NB-LDPC) המותאם במיוחד לחומרת עיבוד-בסמוך-לזיכרון. במקום לעבוד רק עם אפסים ואחדים, הסכימה שלהם פועלת על קבוצות קטנות של ביטים המטופלות כסמלים במבנה מתמטי שנקרא שדה סופי המבוסס על מספר ראשוני (כאן: שלוש). זה מאפשר לאותו קוד להגן הן על אחסון בינארי רגיל והן על קידודים ברמה מרובת־מפלסים או קידודי דיפרנציאלי המשמשים לעתים במאיצים אנלוגיים. המערכת מצרפת מספר צנוע של סמלי בדיקה נוספים לכל בלוק של נתונים. הן בקריאות הזיכרון הרגילות והן בפעולות כפל־וסכימה שמתבצעות בזיכרון, החומרה מחשבת את התוצאות גם עבור הנתונים וגם עבור סמלי הבדיקה, כך שגילוי השגיאות שזור באופן טבעי בתוך החישוב.
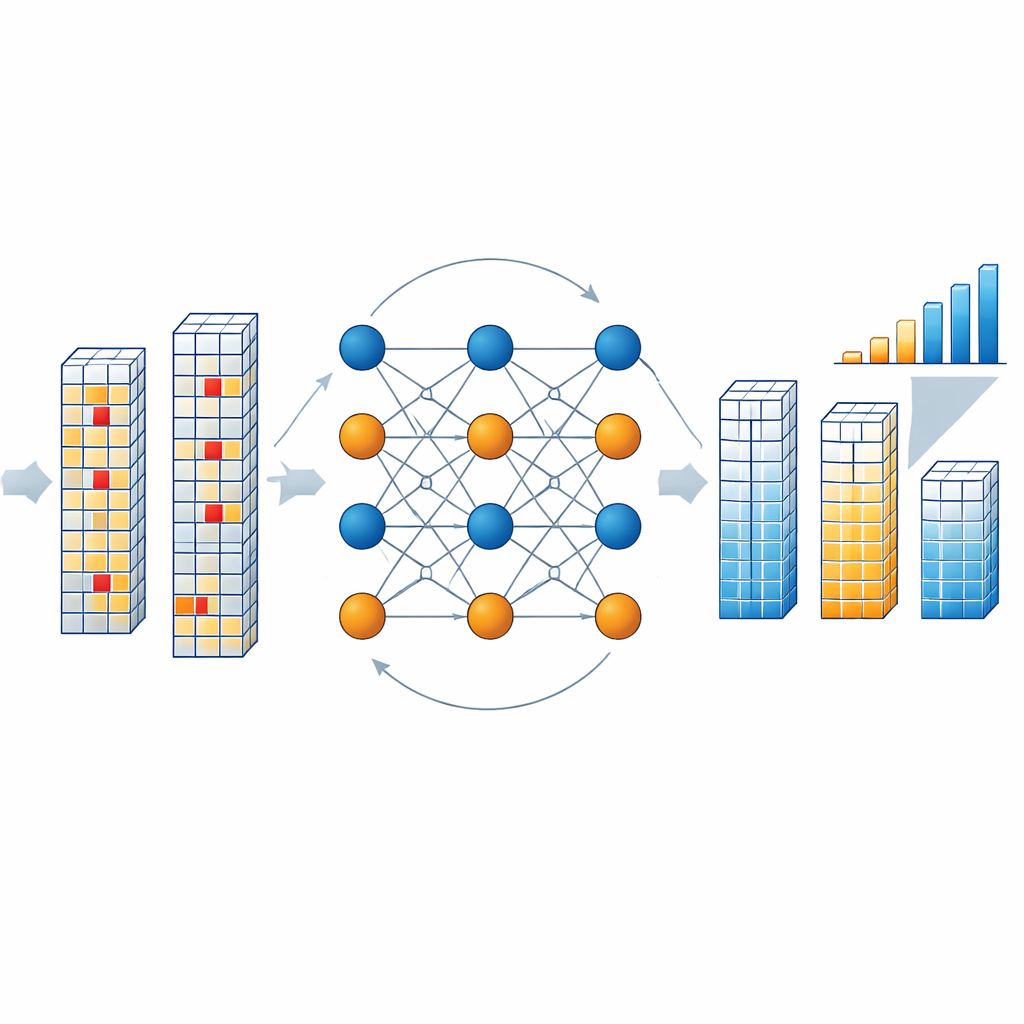
כיצד מנוע התיקון פועל בתוך השבב
כשהשבב קורא בלוק של תוצאות, מפענח ייעודי בודק האם הנתונים המשולבים וסמלי הבדיקה מצייתים ליחסי הפריטי שהוגדרו על ידי הקוד. אם כן, הבלוק מניחים כנקי. אם לא, המפענח משיק תהליך איטרטיבי שבו "קודקודים משתנים" אבסטרקטיים המייצגים כל סמל ו"קודקודי בדיקה" המייצגים תנאי פריטי, מחליפים הודעות הסתברות. הודעות אלה מעריכות כמה סביר שכל סמל יקבל כל אחת מהערכים המותרים, בהתבסס על התוצרים הנצפים ושיעור החלפת הביטים הצפוי בזיכרון. המחברים מפשטים את החשיבה המתמטית הכבדה הזו באמצעות קירובי מרחק מנאהטן, שמפחיתים במידה ניכרת את עלות החומרה תוך שמירה על ביצועים גבוהים. לאחר מספר סבבים — בדרך כלל שלושה — המפענח מתכנס לגרסה המתוקנת הסבירה ביותר של וקטור התוצאה, מבלי שצריך לקרוא את הזיכרון שוב או לעצור את זרם החישוב.
הוכחה בסיליקון והשפעה על דיוק ה-AI
כדי לבחון את הרעיון במציאות, הצוות בנה שבב אב־טיפוס בתהליך של 40 ננומטר שמשלב מערך זיכרון חסין־התנגדות, ממירי אנלוגי‑לדיגיטלי קלים, והמפענח NB-LDPC החדש. בקונפיגורציה שמגינה על 256 סמלי מידע באמצעות 32 סמלי בדיקה, המפענח משיג יחס קוד גבוה (כ‑0.8), יעילות צריכת‑האנרגיה המיטבית שנמדדה של כ־88 טרביטים מתוקנים לשנייה לכל ואט, ותוספת שטח מתונה שיכולה להיות מופחתת עוד על ידי שיתוף מפענח אחד בין כמה מאקרו‑זיכרון. סימולציות על גדלים שונים של קודים מראות שכאשר מגינים על 1024 סמלי נתונים באמצעות 128 סמלי בדיקה, הסכימה יכולה לשפר את שיעור שגיאת הביט כמעט פי 60. כאשר הוחלה על מודל סיווג תמונות ResNet‑34 הרץ על חומרת עיבוד-בסמוך-לזיכרון, התיקון משחזר יותר מ‑20 נקודות אחוז של דיוק שאבד בתנאי שגיאה מאתגרים.
מה זה אומר עבור שבבי ה-AI של העתיד
במילים פשוטות, העבודה מספקת לחומרת עיבוד-בסמוך-לזיכרון "מסנן איות" חזק עבור החישובים שלה, שמבין קבוצות סמלים עשירות ודפוסי שגיאה מורכבים בלי להאט את זרם הנתונים. על ידי איחוד ההגנה גם על נתונים מאוחסנים וגם על חישובים בזמן אמת, ובהצגת יישום סיליקוני יעיל, המחקר מראה שמאיצים צפופים וחסכוני־אנרגיה לא חייבים להקריב אמינות. סוג זה של תיקון שגיאות מותאם יכול להפוך למרכיב מרכזי בהפיכת מאיצים נוירומורפיים ו‑AI עתידיים לחסכוניים באנרגיה ואמינים מספיק ליישומים בעולם האמיתי, ממכשירים ניידים ועד מרכזי נתונים בקנה‑מידה גדול.
ציטוט: Shi, D., Fu, Y., Zhu, Y. et al. Correcting processing-in-memory multiply-accumulate arithmetic errors with LDPC. npj Unconv. Comput. 3, 14 (2026). https://doi.org/10.1038/s44335-026-00061-9
מילות מפתח: עיבוד-בסמוך-לזיכרון, תיקון שגיאות, קודי LDPC, זיכרון חסין-התנגדות (RRAM), חומרת רשתות נוירונים