Clear Sky Science · he
הערכת אי־ודאות המוערכת במודלים לשוניים גדולים
מדוע מילים מטושטשות לגבי סיכון חשובות באמת
כשצוות רפואי אומר שטיפול הוא "סביר" שיעבוד, או מטאורולוג מזהיר שיש "סיכוי קטן" להוריקן, אנחנו מסתמכים על המילים המטושטשות האלה כדי לקבל החלטות ממשיות. היום, מודלים לשוניים גדולים (LLMs) כמו צ’אטבוטים מקוונים מתחילים להשתמש באותו אוצר מילים. המחקר הזה שואל שאלה פשוטה אך קריטית: כשבינה מלאכותית אומרת "כנראה", האם היא מתכוונת לאותה משמעות שאנחנו מבינים — והאם היא יכולה באופן מהימן להמיר מספרים גולמיים למילים יומיומיות שמתארות אי־ודאות?
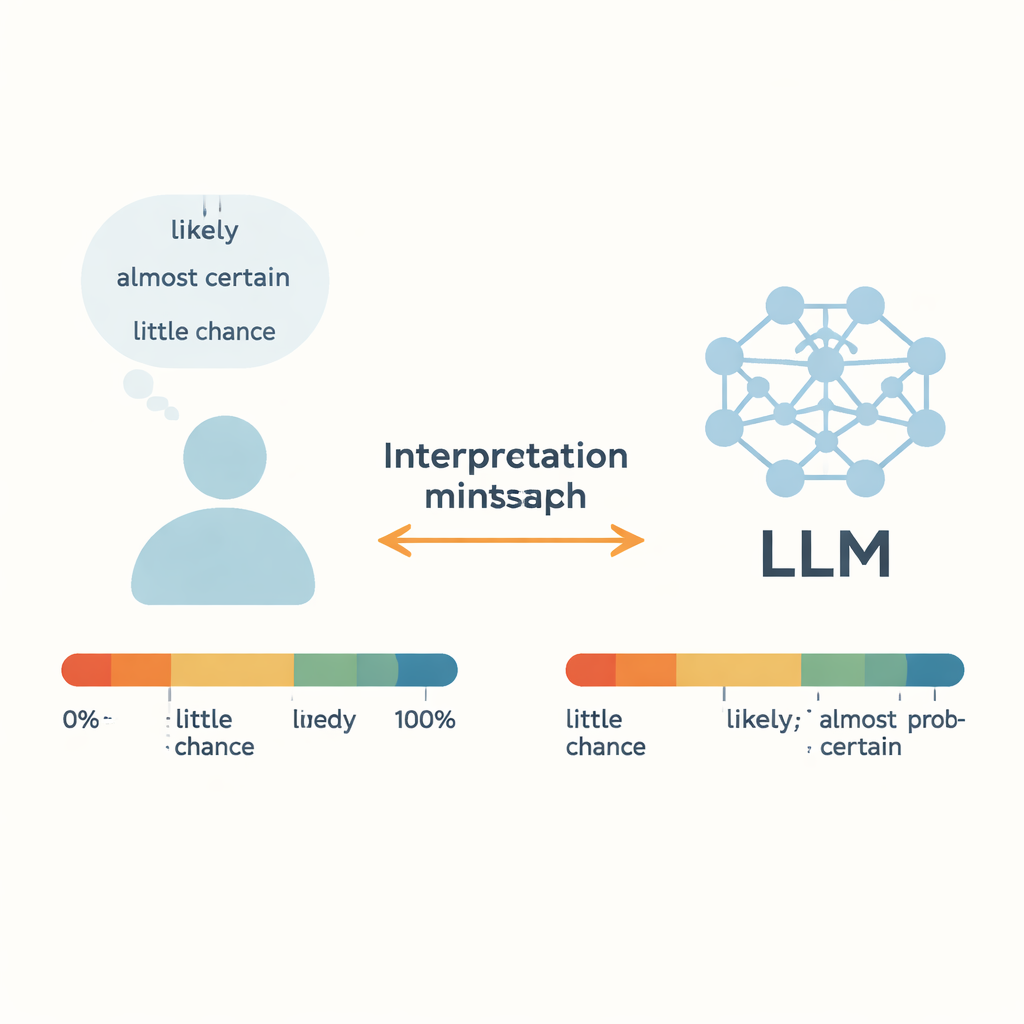
מעמידים את אי־הוודאות היומיומית תחת המיקרוסקופ
המחברים מתמקדים ב"מלים של הסתברות מוערכת" (WEPs) — מונחים כמו "כמעט בטוח", "סביר", ו"סיכוי קטן" שאנשים משתמשים בהם במקום אחוזים מדויקים. עבודות קודמות, החל מאנליסטים מודיעיניים בשנות ה־60, ניסו לקשר בין מילים אלה להסתברויות מספריות על ידי סקרים של אנשים. מחקר זה משווה את שיפוטי האנשים לפלט של חמישה מודלים מודרניים, כולל GPT‑3.5, GPT‑4, דגמי Llama של Meta, ומערכת סינית בשם ERNIE‑4.0. עבור 17 מילים נפוצות המתארות אי־ודאות, כל מודל קיבל פקודות קצרות בסגנון סיפור באנגלית או בסינית והוזמן להגיב בהסתברות מספרית בין 0 ל‑100 אחוז. באמצעות חזרה על כך בהקשרים רבים, המחברים בנו התפלגויות הסתברות מלאות לכל מילה ולכל מודל, ואז השוו אותן לנתוני סקר אנושיים.
איפה בני אדם ובינה מלאכותית מדברים באותה לשון
בעבור ההבעות הקיצוניות ביותר — כגון "כמעט בטוח" בקצה הגבוה ו"כמעט אין סיכוי" בקצה הנמוך — המודלים והאנשים מתיישרים באופן מפתיע. גם אנשים וגם מודלים נוטים לצבור את הביטויים האלה בטווחים צרים של הסתברויות גבוהות או נמוכות, מה שמעיד שמונחים חזקים אלה שמורים יחסית בתחומם בין הקשרים שונים. אותו הדבר נכון לגבי "בערך שווה" (about even), שאנשים ורוב המודלים מתייחסים אליו כמשהו קרוב להסתברות 50–50. בדיקות סטטיסטיות מראות הבדל מועט מהותית בין התפלגויות האנושיות לאלה של המודלים בעבור מילים אלה, ומרמזות שמודלים יכולים לתפוס מקרים ברורים של קרבה לבטיחות או לאי־אפשרות בדיוק הדומה לזה האנושי.
איפה המשמעויות נשזרות בהדרגה
מילים עמומות, באמצע הסקאלה, מספרות סיפור שונה. עבור ביטויים כמו "סביר", "סביר להניח", "אנו ספקנים" ו"סיכוי קטן", הפרשנויות המספריות של המודלים שונות באופן משמעותי מהשיפוטים האנושיים. GPT‑4, אף שהינו בדרך כלל בעל יכולת גבוהה יותר מ‑GPT‑3.5, מראה לעיתים פערים גדולים יותר. המחברים מציעים שהסיבה לכך עשויה להיות שהמילים האלה משלבות שני דברים: תחושת הסתברות ועמדה או יחס של הדובר. בשיחות אמיתיות, "סביר" יכול להישמע זהיר או בטוח בהתאם לטון ולהקשר, ו"אנו ספקנים" עשוי להביע סקפטיות יותר מאשר הסתברות מדויקת. מכיוון שהמודלים מאומנים על טקסט עצום ומגוון מהאינטרנט, הם עשויים לעשות ממוצע על שימושים סותרים רבים ולמטשטש את הדקויות הללו. התוצאה היא חוסר התאמה נסתר: בני אדם ובינה מלאכותית עשויים לקרוא את אותה המשפט ולחבר מספרים שונים באפור אל אותה מילה.
מגדר, שפה והדים תרבותיים
החוקרים בחנו גם כיצד ניסוח ממויין לפי מגדר ושפות שונות מעצבים את המילים הללו של הסתברות. כאשר הפקודות התייחסו ל"הוא" או "היא" במקום לנבדקים ניטרליים מבחינת מגדר, GPT‑3.5 ו‑GPT‑4 לעיתים נתנו הערכות הסתברותיות פחות משתנות, "ננעלות" יותר, שלעיתים קרובות התמוטטו לנקודה יחידה. הדבר מרמז שהמודלים ייתכן וקלוטו דפוסים קשיחים מתוך סטריאוטיפים בנתוני האימון שלהם, למרות שהממוצעים הכוללים עבור פקודות זכר ונקבה היו דומים. בהשוואה בין פקודות באנגלית ובסינית, דגמי GPT הראו סטיות בולטות באופן שבו פירשו את אותן מילים של אי־ודאות. ERNIE‑4.0, שאומן בעיקר על טקסט סיני, היה קרוב יותר לדוברי סינית בהערכות רבות אך עדיין העריך יתר או פחות כמה ביטויים. ממצאים אלה מדגישים שדרך שבה בינה מלאכותית מדברת על אי־ודאות תלויה לא רק במילה שנבחרה, אלא גם בשפה ובדפוסים התרבותיים שהוטמעו באימון שלה.
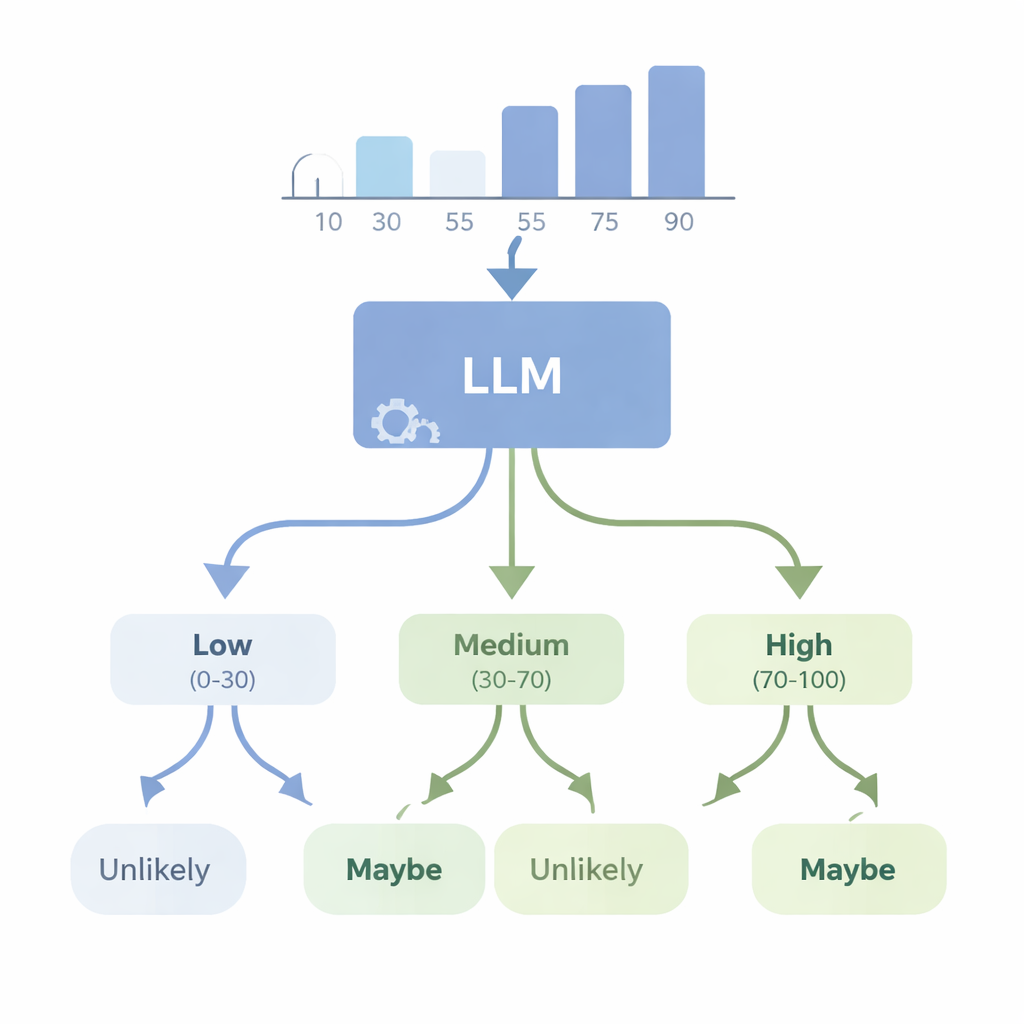
האם מכונות יכולות להמיר מספרים לספק בשפה פשוטה?
בסדרת ניסויים נוספת, המחברים בחנו את הבעיה ההפוכה: האם מודל מתקדם כמו GPT‑4 יכול לצאת מנתונים מספריים ולבחור מילה מתאימה של אי־ודאות? הם הזינו למודל מערכי נתונים פשוטים — כגון רשימות גבהים או ציוני מבחנים — וביקשו ממנו לבחור את ה‑WEP המתאים ביותר (למשל, "כמעט בוודאי", "סביר", "אולי", "לא סביר" או "כמעט בוודאי לא") עבור טענות על תוצאות עתידיות. לאחר מכן הם העריכו את GPT‑4 באמצעות ארבעה ציוני "עקביות" שבודקים האם בחירות המילים שלו הגיוניות כאשר ההסתברויות עולות או יורדות, כאשר מתוארים אירועים משלימים, וכאשר המספרים הבסיסיים משתנים באופן מבוקר. GPT‑4 ביצע טוב יותר מהגרלה אקראית ויכול לעקוב לעיתים אחרי שינויים גסים בסבירות, אך היה רחוק מעקב עקבי מושלם. במבחנים מסוימים הוא הגיב כמעט באותה צורה ברמות ביטחון שונות, מה שמרמז שלפעמים הוא מתייחס למילים אלה כתוויות רחבות במקום כסקאלה מוקפדת הקשורה ישירות לנתונים בפועל.
מה משמע הדבר להחלטות בעולם האמיתי
לקריאה, המסר הוא זהירות אך לא מלהיב בהיסטריה. מודלים לשוניים יכולים כבר לחקות את הביטויים החזקים ביותר שלנו של ודאות ואי־אפשרות, והם יכולים לעיתים לסכם נתונים להצהרות "סביר" או "לא סביר" הגיוניות. אך המחקר מראה שעבור רבות מהמילים היומיומיות שמתארות אי־וודאות, הכיול הפנימי שלהן אינו תואם במלואו לאינטואיציה האנושית, והמיפוי שלהן ממספרים לשפה יכול להיות לא עקבי. בתחומים כמו רפואה, מדיניות או תקשורת מדעית — שבהם שינויים קטנים בניסוח סיכון או ביטחון יכולים להיות משמעותיים — ה"כנראה" של המודל עשוי שלא להיות זהה לשלהם. המחברים טוענים שלשימוש בטוח במערכות אלה עלינו להתייחס למילים של אי־ודאות כקוד משותף שדורש עדיין יישור זהיר, בדיקות, ואולי גיבוי מספרי מפורש, במקום להניח שבני אדם והמכונה מתכוונים לאותו דבר כברירת מחדל.
ציטוט: Tang, Z., Shen, K. & Kejriwal, M. An evaluation of estimative uncertainty in large language models. npj Complex 3, 8 (2026). https://doi.org/10.1038/s44260-026-00070-6
מילות מפתח: אי־ודאות שפה, מודלים לשוניים גדולים, מילים של הסתברות, תקשורת אדם־מכונה, פרשנות סיכון