Clear Sky Science · he
ADMM סטוכסטי מקרי לא מדויק עם קדם-תנאי עבור מודלים עמוקים
אימון חכם יותר עבור בינה חכמה יותר
מערכות בינה מלאכותית מודרניות, מצ׳אבוטים ועד גנרטורים של תמונות, נשענות על רשתות נוירונים מסיביות שקשה ויקר לאמן אותן. ככל שחברות וחוקרים מפזרים נתונים על גבי מכשירים ושרתים רבים, שיטות האימון הרגילות לעיתים מאיטות, הופכות לא יציבות או פשוט אינן מסוגלות להתמודד עם העשייה הבלתי-מסודרת של נתוני העולם האמיתי. מאמר זה מציג משפחת אלגוריתמים חדשה לאימון, המתמקדת בשיטה בשם PISA, שמבטיחה למידה מהירה ואמינה יותר למגוון רחב של מודלים עמוקים תוך הסתמכות על פחות הנחות מתמטיות על הנתונים.
מדוע שיטות אימון נוכחיות מתקשות
רוב המודלים בלמידה עמוקה מאומנים באמצעות וריאציות של האטת גרדיאנט סטוכסטית (stochastic gradient descent), שיטת עבודה המשתנה בהדרגה את פרמטרי המודל בכיוון שממזער שגיאה. לאורך השנים נוספו שיפורים רבים — כמו Adam, RMSProp ואחרים — שניסו להפוך את הצעדים לחכמים יותר על ידי התאמת קצבי הלמידה או הוספת אינרציה. עם זאת, שיטות אלה לרוב מניחות שהנתונים מאומנים בערבוב טוב ושדומיין הנתונים דומה בין מכונות, ושכמה כמויות מתמטיות נשארות גבוליות. בפועל, ובמיוחד בהקשרים כמו למידה פדרטיבית שבה טלפונים או מכשירי קצה מחזיקים בנתונים שוני־מהותיים, הנחות אלה לעיתים נשברות, מה שמוביל להתכנסות איטית או לתפקוד לקוי.
דרך חדשה לתיאום בין לומדים רבים
המחברים בונים על מסגרת אופטימיזציה שונה הידועה כשיטת הכיוון החלופי של מכפילים (alternating direction method of multipliers, ADMM), שהיא טובה בפיצול בעיה גדולה להרבה תת־בעיות קטנות שניתן לפתור במקביל. התרומה המרכזית שלהם, PISA (preconditioned inexact stochastic ADMM), שומרת על היתרונות של ADMM תוך הימנעות ממגרעותיו הרגילות — כגון הצורך לחשב גרדיאנטים מלאים על כלל הנתונים או לבצע הפיכות מטריצות יקרות. במקום זאת, PISA מאפשרת לכל לקוח או צומת עובד לעדכן עותק מקומי של המודל באמצעות מיני־בטץ׳ של נתונים בלבד, ואז לתאם את העדכונים הללו דרך משתנה מרכזי. מטריצות "קדם-תנאי" מעוצבות בקפידה מעצבות מחדש את כיווני העדכון כך שהלמידה מתקיימת בצורה חלקה ויעילה יותר. 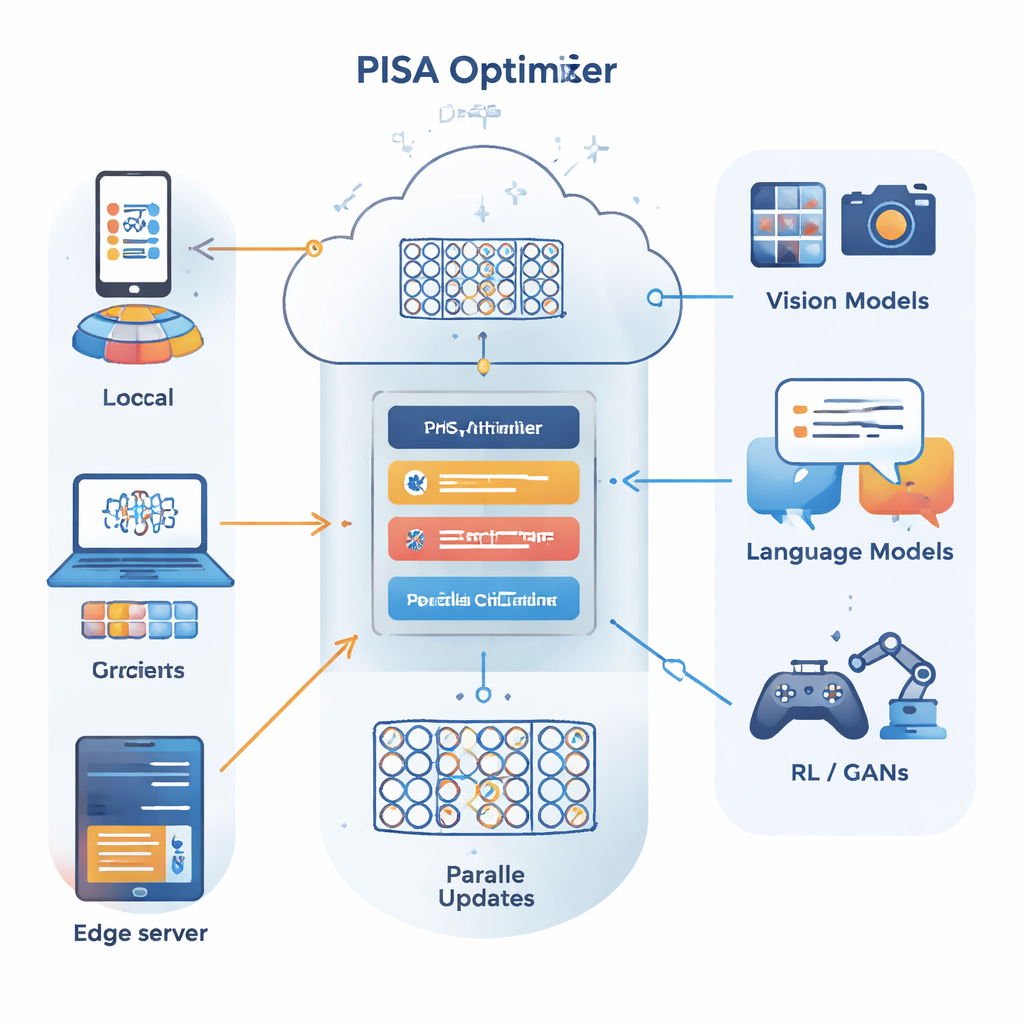
הבטחות חזקות יותר עם הנחות מתונות יותר
מאפיין בולט של PISA הוא היסוד התאורטי שלה. המחברים מראים שהאלגוריתם מתכנס תחת הנחה אחת יחסית מתונה: שהגרדיאנט של פונקציית ההפסד הוא רציף לפי ליפשיץ בתוך תחום חסום, תנאי שמתקיים ברבות מההפסדים הסטנדרטיים ברשתות נוירונים. בניגוד לרוב השיטות הסטוכסטיות, ל־PISA אין צורך בכך שהגרדיאנטים יהיו בלתי מוטים, בעלי ואריאנס חסום, או שייועדו מנתונים מעורבבים באופן מושלם. למרות ההרפיה הזו, השיטה משיגה קצב התכנסות ליניארי במונחי מהירות היציבות של ערכי הפונקציה ועדכוני הפרמטרים, מה שממקם אותה בין האלגוריתמים בעלי הביצועים הטובים ביותר בטבלת ההשוואה הניתנת. זה הופך את PISA לאטרקטיבית במיוחד עבור התפלגויות נתונים הטרוגניות ולא־אחידות השכיחות בפריסות בעולם האמיתי.
וריאנטים פרקטיים עבור רשתות עמוקות אמיתיות
כדי להפוך את המסגרת לפרקטית עבור רשתות נוירונים גדולות, המחברים מציגים שני וריאנטים יעילים, SISA ו־NSISA. SISA משתמש במידע של הרגע השני — עוקב למעשה אחרי גודל העדכונים בעבר בכל כיוון פרמטרי — כדי לבנות קדם־תנאים אלכסוניים פשוטים, בדומה לרעיונות מאחורי Adam ו־RMSProp אך משובצים בתוך מבנה ה־ADMM. NSISA עושה צעד נוסף ומשלב טכניקה הידועה כאורתוגונליזציה של ניוטון–שולץ (Newton–Schulz), בהשראת המיטב של המאיצים כמו Muon, כדי להתאים טוב יותר את המומנטום לכיוונים שימושיים במרחב הפרמטרים. שני הווריאנטים שומרים על הבטחות ההתכנסות של PISA תוך שהם שומרים על חישוב קליל מספיק עבור GPUs מודרניים ומודלים גדולים.
ביצועים על פני משימות חזון, שפה ומודלים גנרטיביים
המחברים בודקים את SISA ו־NSISA על סט רחב של משימות בלמידה עמוקה. בניסויים של למידה פדרטיבית עם התפלגויות תוויות מוטות בכוונה — סביבה מאתגרת שבה כל לקוח רואה רק תת־קבוצה של המחלקות — SISA מציג ביצועים טובים בהרבה על פני שיטות פופולריות כמו FedAvg, FedProx, FedNova ו־Scaffold, ומשיג דיוק מבחן גבוה משמעותית בבנצ׳מרקים כמו MNIST ו־CIFAR-10. עבור מיון תמונות סטנדרטי עם מודלים כמו ResNet ו־DenseNet על CIFAR-10 ו־ImageNet, SISA מתאים את עצמו או עולה על מאיצים חזקים כולל SGD עם מומנטום, AdaBelief ו־AdamW. כאשר מכווננים מחדש מודלים שפתיים GPT2 בגדלים שונים, NSISA מניב אובדן וולידציה נמוך יותר בפחות זמן קיר ממצבים מיוחדים כגון Shampoo, SOAP, Adam-mini ו־Muon, כאשר היתרון בולט יותר עבור המודל הגדול ביותר. הוא גם מייצב את האימון של רשתות GAN, ומשיג מדדי Fréchet inception distance נמוכים יותר, שמודדים את איכות הגיוון והוויזואליות של תמונות שנוצרו. 
מה זה אומר עבור בינה יום-יומית
במילים פשוטות, עבודה זו מראה שאפשר לאמן מודלים רבי-עוצמה מהר יותר ובאמינות גבוהה יותר, גם כשנתונים מלוכלכים, בלתי מאוזנים או מפוזרים על פני מכשירים רבים. על ידי עיצוב מחדש של תהליך האופטימיזציה הבסיסי במקום רק לכוון קצבי למידה, PISA ווריאנטיה מספקים כלי מאוחד שמתאים היטב למשימות חזון, שפה, למידה בהתמצקות (reinforcement learning) ומשימות גנרטיביות. עבור משתמשי קצה, התועלת עשויה להתבטא בהתאמה אישית חכמה יותר בסמארטפונים, במודלים לשפה ותמונה בעלי יכולת גבוהה יותר ובשימוש יעיל יותר במשאבי חישוב במרכזי נתונים — הכל נתמך על ידי אלגוריתם אימון שמתאים טוב יותר למציאות של מערכות AI מודרניות.
ציטוט: Zhou, S., Wang, O., Luo, Z. et al. Preconditioned inexact stochastic ADMM for deep models. Nat Mach Intell 8, 234–245 (2026). https://doi.org/10.1038/s42256-026-01182-3
מילות מפתח: אופטימיזציה בלמידה עמוקה, למידה פדרטיבית, ADMM סטוכסטי, מודלים שפתיים גדולים, נתונים הטרוגניים