Clear Sky Science · he
מתי מודלים לשוניים גדולים אמינים לשיפוט תקשורת אמפתית
מדוע אמפתיה מכנית חשובה לכם
יותר ויותר אנשים פונים לצ׳אבטים ולעוזרים דיגיטליים כשהם לחוצים, בודדים או ניצבים בפני החלטות קשות. מערכות אלו עשויות להישמע אכפתיות ומבינות — אבל האם הן גם יכולות לשפוט האם הודעה אכן תומכת ונדיבה? מאמר זה בוחן מתי מודלים לשוניים גדולים (LLMs), הטכנולוגיה שמאחורי רבים מהצ׳אבטים, מסוגלים להעריך באופן אמין עד כמה תגובה כתובה נראית אמפתית, ומה משמעות הדבר עבור כלים יום-יומיים כמו אפליקציות לרווחה, מטפלים וירטואליים ובוטים לשירות לקוחות. 
חקר שיחות תומכות
החוקרים ניתחו 200 שיחות אמיתיות בטקסט שבהן אדם אחד תיאר בעיה אישית — כמו לחץ בעבודה, קונפליקט משפחתי, דאגות כלכליות או מאבקים נפשיים — ואדם אחר ניסה להגיב באופן תומך. שיחות אלה הגיעו מארבע מערכי נתונים קיימים, שכל אחד מהם קשור לקבוצת שאלות שונה להערכת אמפתיה. חלקם התמקדו בשאלה האם המגיב הראה הבנה או הציע נחמה רגשית; אחרים שאלו האם נתן עצות פרקטיות, עודד את המדבר להרחיב, או במקום זאת מרכז את השיחה סביב עצמו. יחד, מסגרות אלה מפרקות את ה"היות אמפתי" ל-21 התנהגויות ספציפיות שניתן לדרג בסולמות, בדומה לסקר שביעות רצון לקוח.
מומחים, המון ומכונות
כדי לבדוק כמה טובים LLMs בדירוג אמפתיה, הצוות השווה בין שלושה סוגי שופטים: מומחי תקשורת, עובדים ממקורות המונים מקוונים ומודלים לשוניים מודרניים. שלושה חוקרים ותיקים בתחום התקשורת האמפתית דירגו באופן עצמאי כל שיחה בכל 21 ההתנהגויות. עובדי המון — משתמשי אינטרנט רגילים — כבר סיפקו דירוגים עבור אותם מסרים במחקרים קודמים. לבסוף, שלושה מודלים לשוניים מובילים הונחו בקפידה עם הנחיות בשפה פשוטה ודוגמאות דירוג מהמומחים, ואז התבקשו לציין ציון לכל שיחה על אותם סולמות. תצורה זו אפשרה למחברים למדוד עד כמה כל קבוצה הסכימה, לא רק עם "תשובה נכונה", אלא זו עם זו. 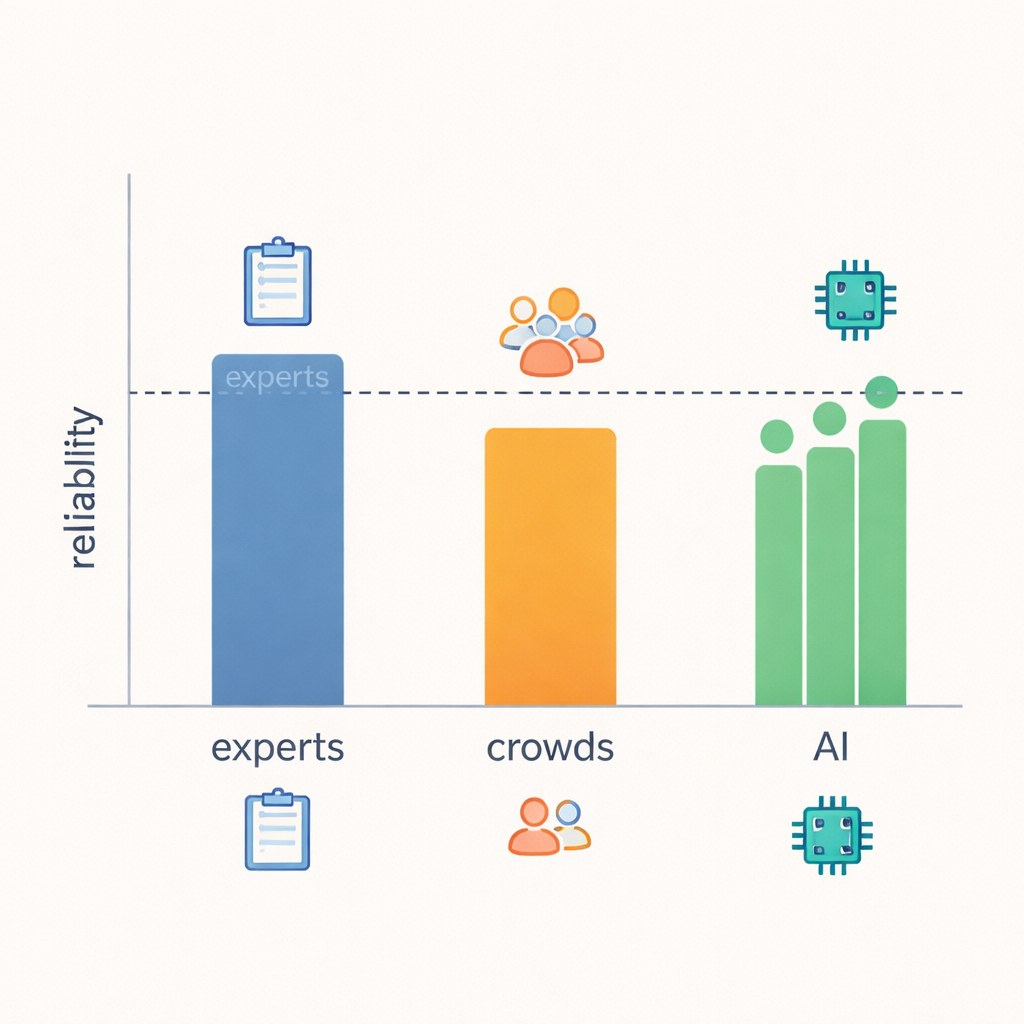
כמה קרוב הן מסכימות?
הממצא המרכזי הוא שמודלים לשוניים גדולים התקרבו ברמת אמינות להשוות לזו של מומחים — באופן מפתיע. כאשר החוקרים מדדו כמה פעמים הדירוגים חפפו וכמה גדולות הנקודות של אי-ההסכמה, המודלים התאימו או כמעט התאימו למומחים ברוב ה-21 ההתנהגויות, והם התעלו באופן ברור על עובדי ההמון. בתחומים עם אותות ברורים הניתנים לצפייה — כגון האם תגובה נתנה עצה מעשית, שאלה שאלת המשך, או החזירה את תשומת הלב למדבר — מומחים, LLMs ואפילו ההמון נטו להסכים יותר. אך כשמדובר בשיפוט רעיונות מטושטשים יותר, כמו האם תגובה באמת "הציגה הבנה" או מה היו כוונות המגיב, אפילו מומחים התריעו על חילוקי דעות תכופים יותר, ואמינות ה-LLM ירדה יחד איתם. הדבר מצביע שחלק מההיבטים של אמפתיה פשוט קשים יותר לקיבוע מטקסט בלבד, ללא קשר למי השופט.
מדוע ציונים פשוטים עלולים להטעות
רבות ממחקרי ה-AI מדווחות על הצלחה באמצעות ציוני סיווג מוכרים — כשמדרג מוסמך נתפס כעובדה בלתי מעורערת ומודדים כמה פעמים המודל תואם אותו. המחברים מראים שגישה זו עלולה לצייר תמונה מעוותת כאשר מדובר בשיפוטים אנושיים עדינים. למשל, מערכת יכולה להרוויח ציון טוב על ידי ניחוש רוב הזמן את דירוג הרוב בסולם לא מאוזן, גם אם היא מתקשה במקרים נדירים אך חשובים. בדומה לכך, שיטה שמרבה לתת "כמעט נכון" — פער של נקודה אחת בלבד — עלולה להיראות גרועה במדד התאמה קשוח, למרות שהיא מתנהגת בדומה למומחה אנושי. על ידי התמקדות באמינות בין-שופטים — כמה בעקביות שופטים שונים מדרגים את אותו הדבר — המחקר מציע תמונה כנה יותר של מה הן היכולות שניתן לסמוך עליהן הן אצל בני אדם והן אצל מכונות.
מה משמעות הדבר עבור AI יום-יומי
עבור הקורא הפשוט, המסקנה גם מעודדת וגם זהירה. LLMs המוגדרים היטב יכולים כעת לסייע בבדיקת האם תגובות כתובות — של מסייעים אנושיים או בוטים אחרים — עומדות בסטנדרטים המומחים לתקשורת אמפתית, ולעתים קרובות הם עושים זאת בעקביות רבה יותר ממדרגים אנושיים לא מאומנים. זה יכול להקל על ניטור ושיפור צ׳אבטים המשמשים בתחום הבריאות, החינוך ושירות הלקוחות. יחד עם זאת, המחקר מזהיר שלא כל "מבחני אמפתיה" נוצרים שווים: שאלות מעורפלות או חופפות מובילות להסכמות אנושיות רעועות, ובתורן לשיפוטים מכניים לא יציבים. לפני שנפקיד בינה מלאכותית לדרג משהו עדין כמו תמיכה רגשית, צריך קודם לוודא שאפילו המומחים עצמם מסכימים מה נחשב "טוב" — ולהשתמש בסף זה כדי להחליט איפה המכונות יכולות לסייע בבטחה ואיפה שיפוט אנושי נשאר חיוני.
ציטוט: Kumar, A., Poungpeth, N., Yang, D. et al. When large language models are reliable for judging empathic communication. Nat Mach Intell 8, 173–185 (2026). https://doi.org/10.1038/s42256-025-01169-6
מילות מפתח: תקשורת אמפתית, מודלים לשוניים גדולים, חברותאיות בינה מלאכותית, תמיכה בבריאות הנפש, אינטראקציה בין אדם ל-AI