Clear Sky Science · he
מודל יסוד וידאו בסקלה רחבה בלמידה עצמית לניתוח חכם
עזרה חכמה יותר בחדר הניתוח
מנתחים מודרניים מסתמכים יותר ויותר על מצלמות ומחשבים כדי להנחות את עבודתם, אך הבינה המלאכותית של היום עדיין מתקשה להבין במלואה מה קורה במהלך ניתוח. מאמר זה מציג שיטה חדשה לאימון בינה מלאכותית על אלפי סרטוני ניתוח כך שהיא תוכל לעקוב טוב יותר אחר שלבי הפרוצדורה, לזהות כלי ניתוח ורקמות, ולהעריך עד כמה הניתוח מתבצע בבטחה ובמיומנות. בטווח הארוך, טכנולוגיה כזו יכולה לתמוך במנתחים בזמן אמת, לשפר הדרכה ולעזור להפוך ניתוחים לבטוחים יותר למטופלים.
מדוע קשה ללמד מכונות על ניתוחים
ללמד מחשבים להבין ניתוח אינו פשוט כמו לספק להם כמה תמונות מתוייגות. כל פרוצדורה כוללת מצלמות נעות, זוויות צילום משתנות, עשן, דם, וידיים וכלים החוסמים זה את זה באופן מתמיד. בנוסף לכך קיימים אלפי סוגי ניתוחים שונים, רבים מהם נדירים. תיוג מדוקדק של וידיאו פר-פריים דורש זמן מומחה יקר והופך במהרה לבלתי ישים מבחינה עלותית. מערכות AI קודמות ניסו להקל על הבעיה בעזרת תחבולות של למידה מתמונות לא מתוייגות, אך הן התמקדו בעיקר בפריימים בודדים ורק מאוחר יותר ניסו להוסיף היבט של זמן. כתוצאה מכך, הן לעתים פספסו את המהלך המתפתח של הניתוח: מה היה לפני, מה קורה עכשיו ומה צפוי לקרות בהמשך.
למידה ישירה מסרטי ניתוח
המחברים טוענים שמערכת AI שמטרתה לסייע בניתוח צריכה להיות מאומנת על וידיאו ולא על תמונות מבודדות. לשם כך הם אספו אחת מאוספי סרטוני האנדוסקופיה הגדולים עד כה: 3,650 הקלטות עם 3.55 מיליון פריימים, שנלקחו ממאגרי מחקר ציבוריים וממגוון רחב של חומר וידיאו ברשת. סרטונים אלה מכסים יותר מ-20 סוגי פרוצדורות ולמעלה מ-10 אזורים אנטומיים, מהוצאת כיס מרה ועד ניתוחי כבד ופעולות גינקולוגיות. הגיוון הזה מאפשר ל-AI לראות דרכים רבות שבהן פרוצדורה יכולה להיראות במציאות, כולל בתי חולים שונים, ערכות כלים וסגנונות צילום שונים.
תכנית לימוד חדשה המתמקדת בווידאו
על בסיס אוצר הנתונים הזה הצוות תיכנן את SurgVISTA, "מודל יסוד" המותאם במיוחד לסרטוני ניתוח. במקום לנסות לתייג כל פריים, SurgVISTA לומד על ידי השלמת החסר. במהלך האימון חלקים מכל קליפ וידאו מוסתרים, והמודל צריך לשחזר את האזורים החסרים. זה מכריח אותו לשים לב לאופן שבו רקמות, כלים ותנועות משתנים לאורך הזמן. במקביל, סניף שני של המערכת מאומן להתאים לרמזים חזותיים מפורטים שנלכדו על ידי מודל מומחה מבוסס-תמונה שמכיל כבר ידע נרחב על סצנות ניתוחיות. השילוב הזה עוזר ל-SurgVISTA לתפוס גם את הפרטים הזעירים בתוך כל פריים וגם את הזרימה הרחבה של כל הניתוח, הכל בתוך רשת מאוחדת אחת.
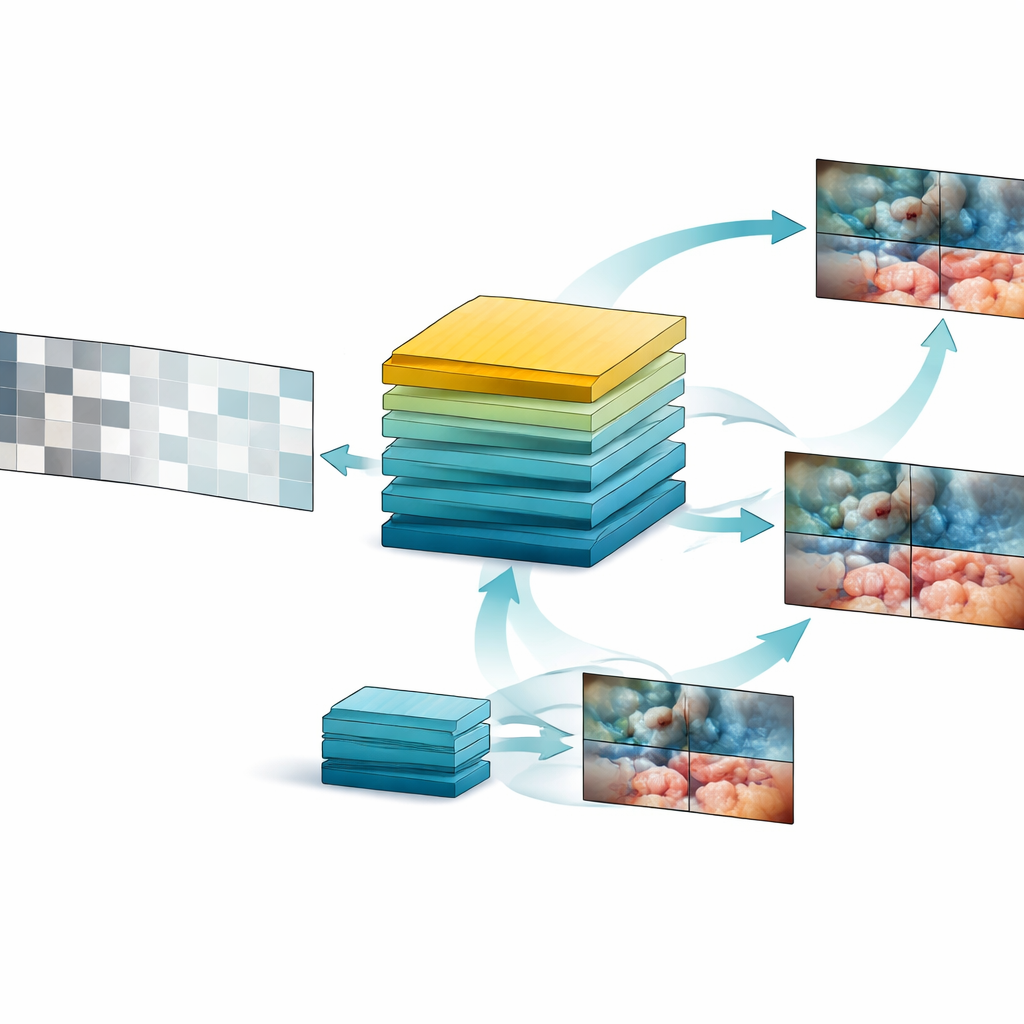
מבחן המודל
כדי לבדוק האם הגישה אכן משתלמת, המחברים בדקו את SurgVISTA על 13 מאגרי נתונים שונים הכוללים שישה סוגי ניתוחים וארבע משימות מעשיות. משימות אלה כללו זיהוי באיזו שלב של הניתוח נמצא התהליך, זיהוי פעולות ניתוח ספציפיות, לכידת הקשר התלת-כיווני בין כלי, פעולה ורקמת היעד, ושיפוט עד כמה שלבים מרכזיים בוצעו בבטחה. בכל המבחנים SurgVISTA גבר על מודלים מובילים שאומנו על וידיאו יומיומי, וכן על מערכות ממוקדות-ניתוח קיימות שהיו מבוססות בעיקר על תמונות בודדות. הוא הראה ביצועים חזקים גם בפרוצדורות שהוא מעולם לא ראה במהלך האימון, מה שמצביע על כך שהתבניות שלמד אינן תלויות באיבר, בחבילת כלים או בבית חולים ספציפי.
מדוע יותר נתונים עשירים של וידאו חשובים
המחקר בדק גם כיצד הביצועים משתנים ככל שמוסיפים נתוני אימון. כשהמחברים הגדילו בהדרגה את גודל ומגוון מאגר הווידאו, התוצאות של SurgVISTA השתפרו כמעט בכל המדדים, כולל בניתוחים שלא הופיעו כלל בערכת האימון. מעניין שהמודל הרוויח לא רק מתוספת דוגמאות מאותו ניתוח, אלא גם מסוגים שונים של ניתוחים: חשיפה ל"סיפורים" ניתוחיים מגוונים עזרה לו לזהות דפוסים חזותיים ותנועתיים כלליים שעוברים בין תחומים. ניסויים נוספים הראו שההדרכה הנוספת מהמודל המומחה מבוסס-הצילום חידדה עוד יותר את יכולת המודל לשמר פרטים אנטומיים עדינים, קריטי להבחין, למשל, בין מבנה חיוני לרקמה מסביבו.
מה משמעות הדבר עבור הניתוח בעתיד
במלים פשוטות, עבודה זו מראה כי בינה מלאכותית שמאומנת על כמות גדולה של וידאו ניתוחי אמיתי, כשהיא מתחשבת במרחב ובזמן, יכולה לבנות הבנה עמוקה הרבה יותר של מה שמתרחש בחדר הניתוח. SurgVISTA עדיין אינו כלי שמקבל החלטות בעצמו, אך הוא מספק בסיס חזק שאליו אפליקציות אחרות יכולות להתחבר — בין אם למעקב אחר התקדמות הניתוח, איתות רגעים מסוכנים, תמיכה בהדרכה, או השוואת טכניקות בין בתי חולים. המחברים מציינים שעדיין נדרשים נתונים רחבים יותר וניסויים קליניים, אך תוצאותיהם מצביעות על כך שמודלי יסוד מבוססי וידאו עשויים להפוך לרכיב מרכזי במערכות ניתוח חכמות עתידיות שמטרתן להפוך פרוצדורות לבטוחות יותר, עקביות יותר ומותאמות יותר לכל מטופל.
ציטוט: Yang, S., Zhou, F., Mayer, L. et al. Large-scale self-supervised video foundation model for intelligent surgery. npj Digit. Med. 9, 220 (2026). https://doi.org/10.1038/s41746-026-02403-0
מילות מפתח: בינה מלאכותית לווידיאו ניתוחי, למידה עצמית, מהלך ניתוחי, ניתוח בעזרת מחשב, מידול מרחב-זמני