Clear Sky Science · he
מודלי שפה גדולים משפרים את היכולת להעביר תחזיות מבוססות רשומות בריאות אלקטרוניות בין מדינות ומערכות קידוד
מדוע שיתוף חכם יותר של נתונים רפואיים חשוב
בתי חולים ומרפאות ברחבי העולם מחזיקים בכמויות עצומות של מידע יקר ערך: רשומות בריאות אלקטרוניות המתעודות אבחנות, טיפולים ותוצאות לאורך שנים. בתיאוריה, מידע זה יכול לעזור לרופאים לזהות מוקדם מי נמצא בסיכון גבוה למחלות קשות, זמן רב לפני שהתסמינים בולטים. בפועל, עם זאת, המודלים הממוחשבים של היום מתקשים "לנסוע" ממערכת בריאות אחת לאחרת, כיוון שכל מקום מתעד נתוני בריאות בצורה שונה. במחקר זה מוצגת גישה חדשה, בשם GRASP, שניצלת התקדמות בבינה מלאכותית כדי לגשר על פערים אלה כך שמודל שאומן במערכת בריאות אחת יוכל לפעול באופן מהימן במערכות אחרות.
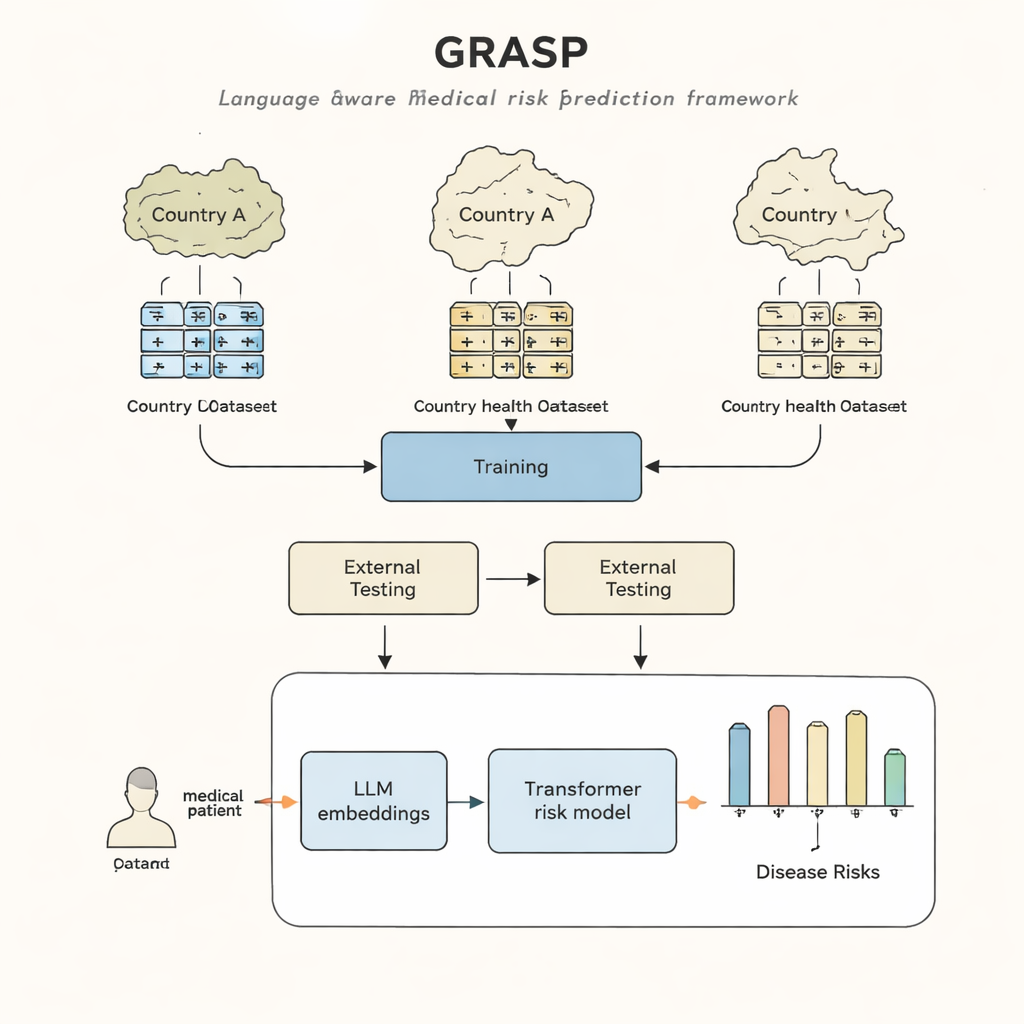
בתי חולים שונים, שפות שונות
גם כאשר רופאים מטפלים באותה מחלה, הם לעתים קרובות משתמשים במערכות קידוד והרגלים מקומיים שונים כדי לתעד אותה ברשומה הרפואית. בית חולים אחד עשוי לאחסן "רמת סוכר גבוהה בדם" תחת קוד מסוים, בעוד אחר ישתמש בקוד שונה ל"היפרגליקמיה", ושלישי יפעל לפי מערכת שונה לחלוטין. מאמצים לאכוף סטנדרט אחד—כמו סכמות קידוד בינלאומיות גדולות—חשובים אך איטיים, יקרים ועדיין משאירים הבדלים משמעותיים. כתוצאה מכך, מודל מחשב שמנבא מחלה מתוך רשומות במדינה אחת עלול לאבד דיוק כשהוא מיושם במקום אחר, מה שמגביל את מי שיכול להפיק תועלת מהכלים הללו.
להניח לבינה לקרוא משמעות, לא רק קוד
גישה GRASP מתחילה מרעיון פשוט: במקום להתייחס לכל קוד רפואי כמספר זיהוי חסר משמעות, לתת למודל שפה גדול לקרוא את התיאור האנושי מאחוריו, למשל "דלקת דרכי נשימה עליונה חריפה", ולהמיר את המשמעות הזו ל"אימבידינג" מספרי. אימבידינגים אלה מציבים מושגים קרובים זה לזה במרחב משותף, גם אם הם מגיעים ממערכות קידוד או ממדינות שונות. GRASP מחשב מראש אימבידינגים כאלה עבור מיליוני מונחים רפואיים סטנדרטיים ושומר אותם בטבלת חיפוש. היסטוריית המטופל מיוצגת אז כשרשרת של וקטורים עשירים אלה, שמוזנת לתוך רשת טרנספורמר—סוג של רשת נוירונים המתאימה לטיפול באוסף של קלטים מגוונים—כדי להעריך את סיכונו של האדם ל-21 מחלות מרכזיות וכן לסיכון כללי לתמותה.
בדיקה בין מדינות ומערכות רשומה
החוקרים אימנו את GRASP באמצעות נתונים של כמעט 400,000 משתתפים מ-UK Biobank, ולאחר מכן בדקו אותו ללא אימון חוזר בשתי סביבות שונות מאוד: פרויקט FinnGen בפינלנד ורשת בתי חולים גדולה בניו יורק סיטי. GRASP השיג ביצועים זהים או טובים משל חלופות חזקות, כולל שיטה נפוצה בשם XGBoost וטרנספורמר דומה שלא השתמש באימבידינגים מבוססי שפה. בפינלנד GRASP הציג יתרון בולט, עם שיפורים למחלות כגון אסתמה, מחלת כליות כרונית וכשל לב. באופן בולט, אפילו כאשר נתוני בית החולים האמריקאי נשארו במערכת קידוד שונה במקום להיות מומרות לסטנדרט משותף, GRASP עדיין סיפק תחזיות טובות יותר מאוכלוסיות דמוגרפיות בלבד, כי הוא יכול היה ליישר קודים רק על ידי הבנת ניסוח התיאורים שלהם.
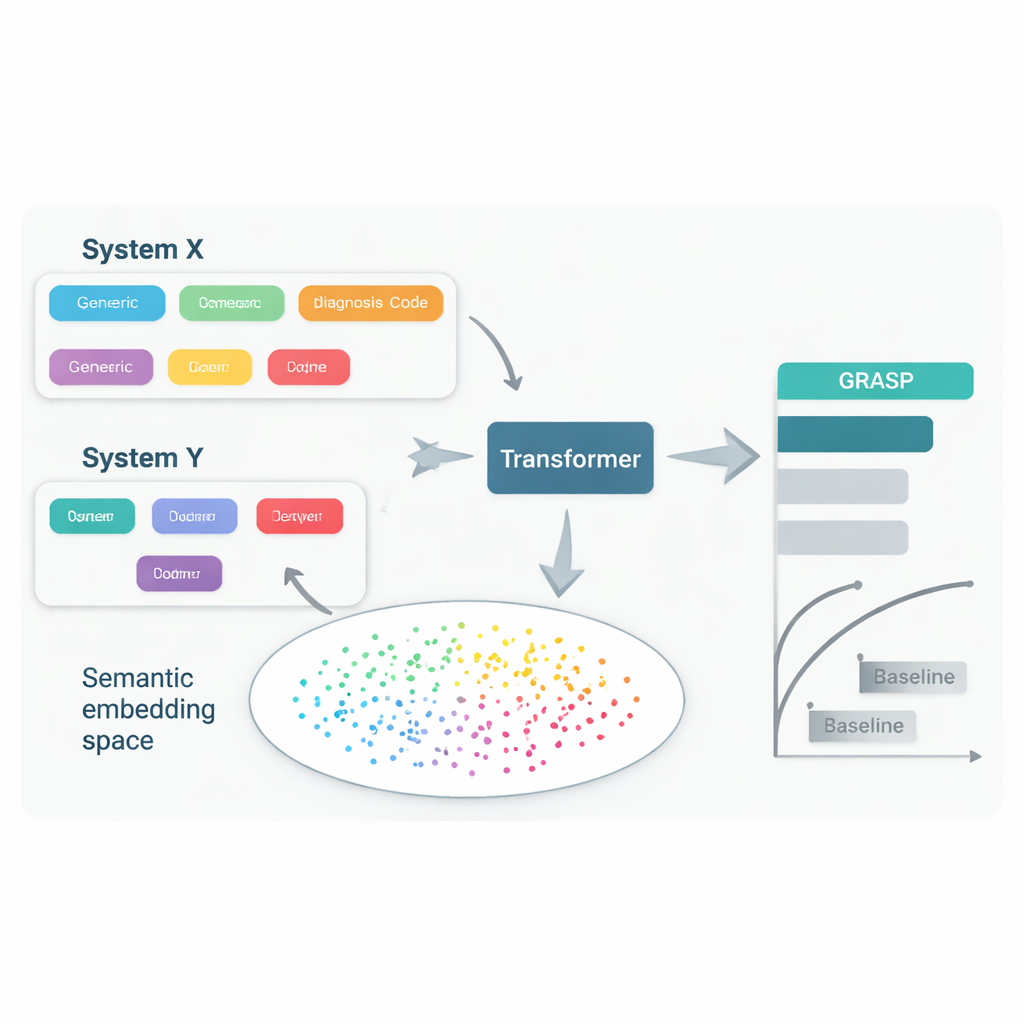
להפיק יותר מנתונים מועטים
יתרון נוסף של GRASP הוא היעילות. מאחר שמודל השפה כבר למד שמושגים רפואיים רבים קשורים זה לזה, רשת החיזוי אינה צריכה לגלות מחדש את הקישורים הללו מאפס. כשהמחברים אימנו את GRASP על תת-קבוצות קטנות בהרבה של נתוני ה-UK—עד ל-10,000 אנשים בלבד—הוא עדיין עלה על מודלים מתחרים שאומנו על אותן דגימות מוגבלות, הן בבריטניה והן כאשר הועבר לחו"ל. ציוני הסיכון של GRASP גם היו מותאמים יותר לסיכון הגנטי התורשתי של אנשים עבור מספר מחלות, מה שמרמז שהוא תופס היבטים עמוקים יותר של רמת הרגישות למחלות במקום רק לשנן דפוסים בערכה נתונה.
מה המשמעות הזו לטיפול עתידי
ללא-מומחים, המסר המרכזי הוא ש-GRASP מדגים כיצד בינה מודרנית מבוססת שפה יכולה לעזור למערכות בריאות שונות "לדבר באותה שפה" מבלי לכפות עליהן סכימה קשיחה אחידה. על ידי קריאת משמעות המונחים הרפואיים, GRASP יכול ליצור תחזיות סיכון למחלות שמכלילות טוב יותר בין מדינות ובין פורמטים של רשומות, ושיכול לעשות זאת עם פחות דוגמאות מטופלים. למרות שהשיטה עדיין דורשת בדיקות קפדניות, כיוונון ובדיקות הוגנות לפני שימוש יומיומי, היא מצביעה על עתיד שבו כלים חזקים לפיקוח סיכון המפותחים במקום אחד יכולים להיות משותפים בצורה בטוחה ויעילה עם בתי חולים ומרפאות ברחבי העולם.
ציטוט: Kirchler, M., Ferro, M., Lorenzini, V. et al. Large language models improve transferability of electronic health record-based predictions across countries and coding systems. npj Digit. Med. 9, 177 (2026). https://doi.org/10.1038/s41746-026-02363-5
מילות מפתח: רשומות בריאות אלקטרוניות, חיזוי סיכון להחלות, מודלי שפה גדולים, שיתוף נתונים רפואיים, בינה מלאכותית לבריאות