Clear Sky Science · he
השוואת למידת מכונה מבוזרת ומודלי בינה מלאכותית קליניים לאלטרנטיבות מקומיות ומרכזיות: סקירה שיטתית
מדוע חשוב לחלוק תוצרים רפואיים בלי לשתף נתונים
הרפואה המודרנית נשענת יותר ויותר על בינה מלאכותית לזיהוי מוקדם של מחלות, לבחירת הטיפול הנכון ולחיזוי מי בסיכון הגבוה ביותר. יחד עם זאת, כלים יעילים של בינה מלאכותית דורשים כמויות עצומות של נתוני מטופלים, ובתי חולים לא יכולים פשוט לאחד את הרשומות שלהם בגלל חוקים מחמירים של פרטיות ושיקולים אתיים. מאמר זה סוקר יותר מעשור של מחקר על "למידה מבוזרת" — דרכים שבהן בתי חולים מאבלים ללמד מערכות בינה מלאכותית יחד מבלי לשתף נתונים פרטיים — ושואל שאלה מעשית: עד כמה שיטות אלה המשמרות פרטיות אכן מתפקדות בהשוואה לגישות המסורתיות?
דרכים חדשות ללמוד ממטופלים תוך הגנה על הפרטיות
בלמידה מרוכזת מסורתית, בתי חולים מעתיקים את כל הנתונים שלהם למסד נתונים מרכזי ואימונים של מודל אחד מתבצעים שם. בלמידה מקומית, כל מוסד בונה את המודל שלו על הנתונים שלו, ללא שיתוף פעולה. למידה מבוזרת מציעה דרך ביניים. בלמידה פדרטיבית, למשל, כל בית חולים מאמן מודל באופן מקומי, ואז נשלחים רק הפרמטרים של המודל (כמו ה"כרטיסי כיוון" ברשת נוירונים) כדי לשלבם למודל משותף; הרשומות של המטופלים לעולם לא עוזבות את האתר. Swarm learning מסיר את המתאם המרכזי ומאפשר למוסדות להחליף עדכוני מודל ישירות. גישות מבוזרות נוספות משלבות תחזיות מכמה מודלים מקומיים, או מחלקות את המודל בין אתרים. שיטות אלה נבדקו בבעיות ממגוון תחומים, החל מזיהוי סרטן ואבחון COVID‑19 ועד למחלות לב, סוכרת, הפרעות מוחיות ומצבים פסיכיאטריים.
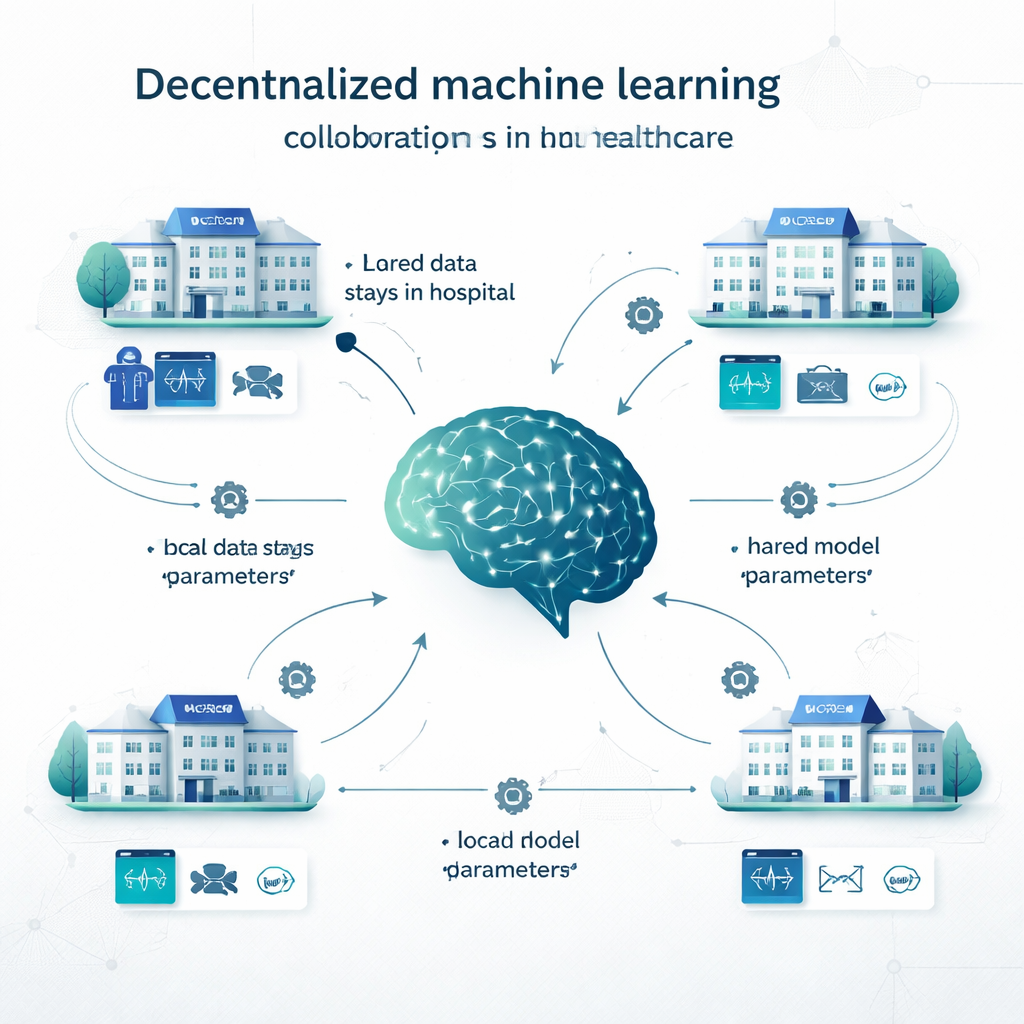
מה החוקרים בחנו
המחברים חיפשו באופן שיטתי ב‑11 מאגרי מידע מרכזיים וסקרו 165,010 מחקרים שפורסמו בין 2012 למרץ 2024. לאחר הסרת כפילויות ומחקרים שלא כללו החלטות קליניות אמיתיות נותרו 160 מאמרים. יחד דיווחו המאמרים על 710 מודלים מבוזרים ועל 8,149 השוואות ביצועים ישירות מול מודלים מרכזיים או מקומיים. רוב המחקרים התמקדו באבחון, אך היו גם רבים שהתמקדו בסגמנטציה של תמונות (לדוגמה, סימון גבולות גידולים), בחיזוי תוצאות עתידיות כגון הישרדות או סיבוכים, ובמטלות משולבות. סוגי הנתונים כיסו כמעט כל מקור עיקרי בשימוש ברפואה: רשומות בריאות אלקטרוניות, סריקות CT ו‑MRI, צילומי רנטגן, שקופיות פתולוגיה דיגיטליות, אותות לב ומוח, ואפילו נתונים גנטיים.
כיצד מודלים המשמרי פרטיות משתווים ל‑AI מרוכז
כאשר השוו מודלים מבוזרים למודלים מרוכזים שאומנו על נתונים מאוחדים, הלמידה המרוכזת בדרך כלל הייתה מעט עדיפה. היא הצטיינה במיוחד במידות מבוססות סף כמו דיוק ומדד תמונה מקובל הנקרא Dice, וניצחה בכ‑כ‑רבע מהמקרים וברובם בהפרש שנחשב ליתרון מתון עד גדול. עם זאת, עבור מדדי מיון — כגון שטח תחת עקומת ה‑ROC (AUROC), שמתאר עד כמה המודל מדורג מטופלים מסיכון נמוך לגבוה — המודלים המבוזרים והמרוכזים היו קרובים יותר, עם יתרון קטן בלבד ללמידה המרוכזת. חשובה לציון היא העובדה שכאשר שני המודלים הגיעו למה שהמחברים מכנים "ביצועים קליניים מקובלים" (ציון של לפחות 0.80), הרווח הטיפוסי של המודל המרוכז היה צנוע: לעתים קרובות פחות מנקודה אחוזית עד 1.5 נקודות. בהרבה מצבים זה המשמעותי הייתה "מצוין לעומת מקובל", לא "שימושי לעומת חסר תועלת".
מדוע למידה מבוזרת עדיפה על צעד יחידני מקומי
האות החזק ביותר בסקירה הופיע כאשר השוו מודלים מבוזרים למודלים מקומיים בלבד. בכל המדדים העיקריים — דיוק, AUROC, מדד F1, רגישות, סגוליות ובמיוחד דיוק חיובי (precision) — השיטות המבוזרות כמעט תמיד ביצעו טוב יותר, לעתים בהפרש ניכר. במבחנים ישירים, למידה מבוזרת עלתה על מודלים מקומיים ביותר מ‑80% מההשוואות עבור מדדים מרכזיים כגון דיוק, precision ו‑AUROC. במקרים רבים, מודלים מקומיים לא הצליחו להגיע לסף של 0.80 לשימוש קליני, בעוד המודל המבוזר המתאים עבר אותו בנוחות, ושיפר רגישות בעד 27 נקודות אחוז. המחברים מייחסים זאת לניסיון הרחב יותר שמודלים מרובי‑אתרים צוברים: "לראות" דפוסים מבתי חולים רבים מקטין את האפשרות שמתפתים לאפייני אתר ספציפיים בציוד הסריקה או בניהול הרשומות, ומגביר את היכולת לזהות תכונות מחלה שמכלילות באמת.
איזון בין ביצועים, פרטיות ושימוש מעשי
הסקירה מסכמת שלמידה מרוכזת נשארת הסטנדרט הגבוה כשהחוקים והלוגיסטיקה מאפשרים איחוד נתונים וכשהכל נשקל — למשל במחלות נדירות מאוד שבהן כל שבריר אחוז בביצועים חשוב. עם זאת, למידה מבוזרת מציעה אלטרנטיבה חזקה וקבילה קלינית במצבים שבהם שיתוף נתונים מוגבל על‑ידי חוקים כמו ה‑GDPR או חוקי ה‑EU AI, או על‑ידי מדיניות מוסדית. ביחס לשמירה על מודלים לחלוטין מקומיים, גישות מבוזרות מספקות שיפורים ניכרים בדיוק ובאמינות תוך שמירה על הנתונים בתוך חומות בתי החולים. המחברים טוענים שמחקרים עתידיים צריכים לדווח ביתר בהירות על טכניקות הפרטיות ועל עלויות חישוביות, כדי שמערכות בריאות יוכלו לקבל החלטות מושכלות על מתי כדאי לוותר מעט בביצועים תמורת יתרונות משמעותיים בפרטיות ובשיתוף פעולה.
ציטוט: Diniz, J.M., Vasconcelos, H., Rb-Silva, R. et al. Comparing decentralized machine learning and AI clinical models to local and centralized alternatives: a systematic review. npj Digit. Med. 9, 174 (2026). https://doi.org/10.1038/s41746-025-02329-z
מילות מפתח: למידה פדרטיבית, בינה מלאכותית במערכת הבריאות, פרטיות של נתונים רפואיים, למידת מכונה מבוזרת, מודלי חיזוי קליניים