Clear Sky Science · he
IMFLKD: מנגנון תמריצים ללמידת פדרציה מבוזרת המבוסס על זיקוק ידע
מדוע שיתוף יכול להיות בטוח והוגן
בינה מלאכותית מודרנית ניזונה מנתונים, ורוב הנתונים שלנו נשמרים בטלפונים אישיים, בשרתי בתי חולים או בעננים של חברות שלא ניתן להעתיק ולשתף בקלות. למידת פדרציה מציעה דרך שמאפשרת למכשירים רבים לאמן מודל משותף מבלי לחשוף את הנתונים הגולמיים שלהם, אבל המערכות של היום עדיין נאבקות בדליפות פרטיות, בנקודות כשל מרכזיות ובתגמולים לא הוגנים לאלה שתורמים הכי הרבה. מאמר זה מציג מסגרת חדשה, IMFLKD, המשלבת שלוש רעיונות רבי‑עוצמה — בלוקצ’יין, זיקוק ידע ומדידת מוניטין — כדי להפוך סוג זה של למידה קולקטיבית לפרטית יותר, חסינת שגיאות והוגנת יותר בטווח הארוך.
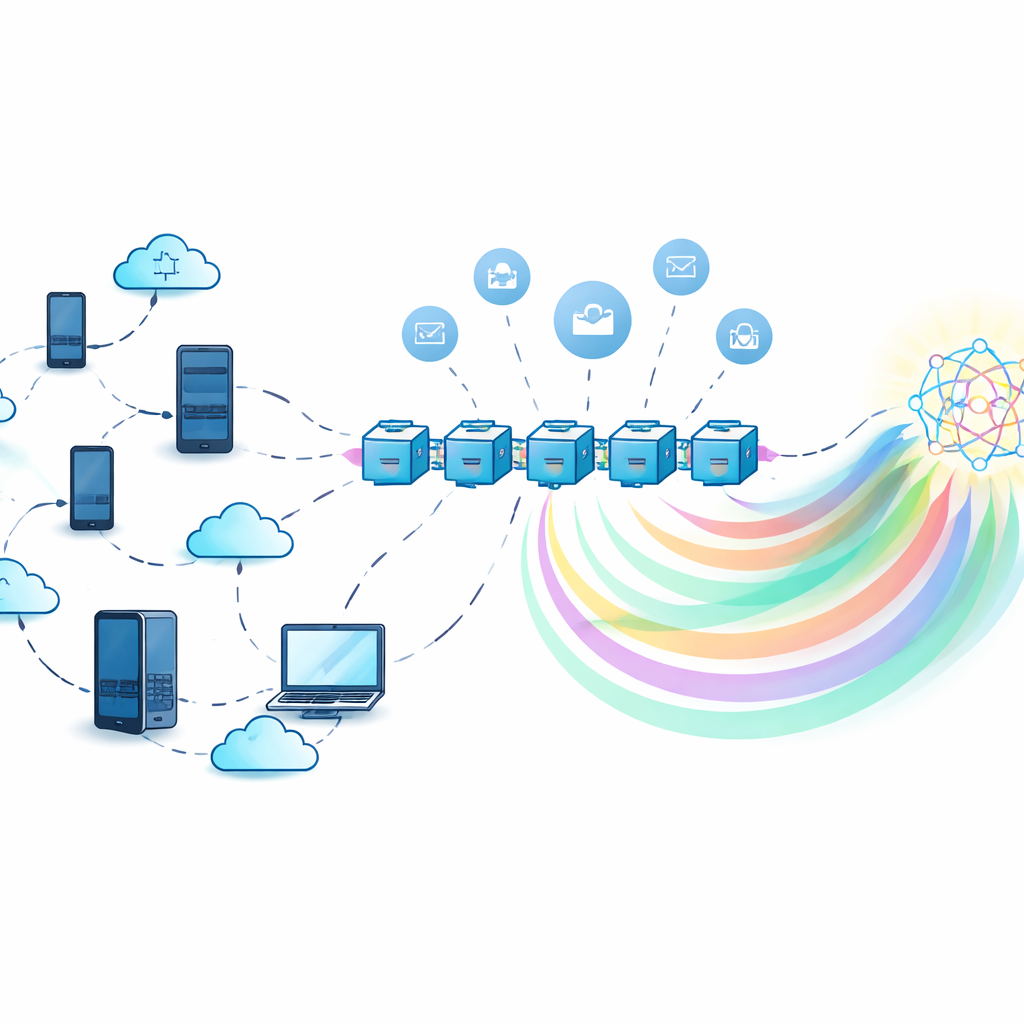
אימון משותף בלי שיתוף סודות
בלמידת פדרציה קלאסית, שרת מרכזי אוסף עדכוני מודל מהמון משתתפים ומשלב אותם. זה מונע נסיעה של הנתונים הגולמיים, אבל השרת עצמו הופך ליעד פוטנציאלי: אם הוא נכשל המערכת כולה נעצרת, ואם הוא לא אמין — הוא עלול להשתמש לרעה או לדלוף מידע שמוסתר בעדכוני המודל. המחברים במקום זאת משתמשים ביומן מבוזר מבוסס בלוקצ’יין לתיאום האימון. כל משתתף מאמן מודל מקומי על הנתונים שלו ואז מתקשר עם חוזים חכמים בבלוקצ’יין שמרשמים תרומות, מאגדים מידע ומפזרים תגמולים — הכל ללא הסתמכות על רשות מרכזית יחידה.
שיתוף ידע, לא מודלים כבדים
כדי לצמצם עלויות תקשורת ולהגן עוד יותר על הפרטיות, המסגרת נשענת על זיקוק ידע. במקום לשלוח פרמטרים מלאים של מודל, כל משתתף שולח רק "תוויות רכות" — הסתברויות החיזוי של המודל עבור קבוצה של קלטים משותפים — שהן קלות יותר וגילויות פחות לגבי נתוני יחיד. מכיוון שמאגר משותף אמיתי עשוי לא להתקיים, המערכת משתמשת במודל גנרטיבי שנקרא אוטו‑ווריאציונלי מותנה (conditional variational autoencoder) כדי ליצור מאגר סינתטי "דמה‑ציבורי" שמתאם בקירוב את התפלגות התוויות הכללית בלי לחשוף רשומות מקוריות. המשתתפים מאמנים על הנתונים שלהם, מבצעים תחזיות על המאגד הסינתטי ואז מחדדים את המודלים שלהם בעזרת אות מצטבר הנגזר מתוך הידע המשולב של כולם.
מדידת מי באמת תורם
אתגר מרכזי בכל מערכת שיתופית הוא להחליט מי ראוי לאשר. IMFLKD מטפל בכך בשיטת הערכת תרומה בשני שלבים המבוססת על אגירת תוויות. ראשית, אלגוריתם באייסי קל משקל בוחן את התחזיות מכל המשתתפים ומסקן הן את התווית הסבירה ביותר לכל דוגמה והן ציון איכות לכל מודל, ומעדכן ציונים אלה ככל שמגיעים מטלות נוספות. גישה זו עובדת בזמן אמת, ללא אחסון נתונים ישנים, ומתמודדת עם תורמים רעשניים או זדוניים על‑ידי הקטנת המשקל של מודלים שמתנגדים לעתים קרובות לקונצנזוס המתפתח. ניסויים מראים שאגירת תוויות זו משפרת את הדיוק בכ‑כ־10 אחוזים בהשוואה להצבעת רוב פשוטה, ובאותה עת נשארת מהירה דיו לסביבות בקנה מידה גדול עם משאבים מוגבלים.
הפיכת איכות לתגמולים ומוניטין
לאחר שקביעת איכות התרומה מוכרת, IMFLKD משתמשת בסכימת תמריצים שנקראת "מוקד אמת משוקלל_peer truth serum" כדי להפוך אותה לתגמולים. המשתתפים מושווים לקונצנזוס עמיתים משוקלל לפי איכות: אלה שהתחזיות שלהם מתיישבות עם עמיתים איכותיים מרוויחים יותר, בעוד שמי שסוטה או מתווכח בתדירות גבוה יורחק. הדבר מייצר דיווח כנה כאסטרטגיה הרווחית ביותר בטווח הארוך, אפילו מול מזימות. בנוסף, המערכת בונה ציון מוניטין רב‑ממדי לכל משתתף, המשלב איכות נתונים, רמת פעילות ויציבות התנהגותית, ומתאימה התנהגות ישנה באמצעות גורם דעיכה בזמן. המוניטין משובץ בחזרה בסבבים מאוחרים בכך שהוא משפיע על משקל התחזיות של משתתף והאם ייבחר למשימות עתידיות.
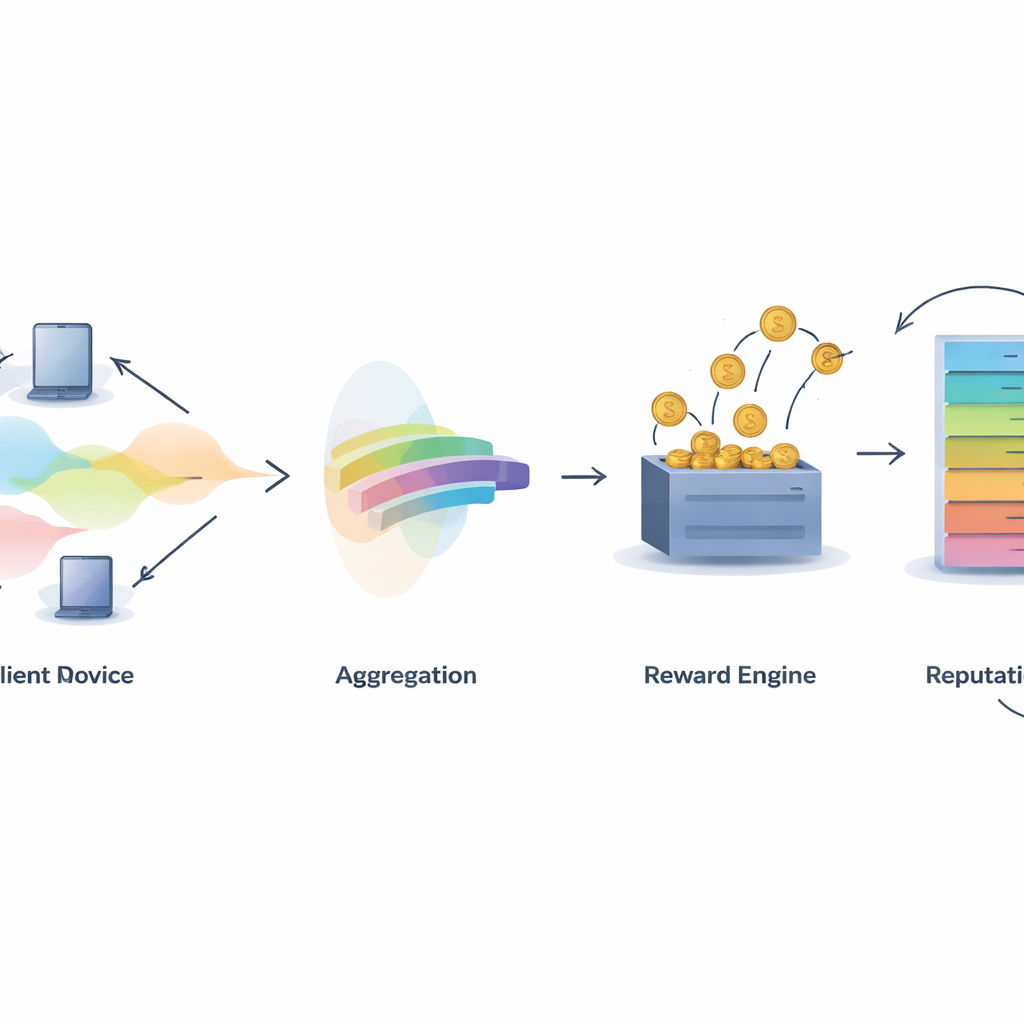
בניית אמון בחוכמה קולקטיבית
בסך הכל, מסגרת IMFLKD מראה שאפשר לתאם למידה על פני רבים ממכשירים עצמאיים באופן יעיל, מודע לפרטיות ועמיד בפני מנצלים ותוקפים. על ידי שילוב יצירת נתונים סינתטיים, דירוג תרומות מחמיר, תגמולים בגישה תיאורטית‑משחקית ומעקב דינמי אחרי מוניטין על גבי בלוקצ’יין, המערכת מעודדת משתתפים להתנהג ביושרה ובעקביות לאורך סבבי אימון רבים. עבור הקורא הכללי, המסקנה היא שניתן לזקק את הכוח הקולקטיבי של נתונים מבוזרים — כגון רשומות רפואיות, קריאות חישה או מכשירים אישיים — מבלי למסור הכל לחברה או שרת יחיד, ובאותה עת לוודא כי אלו שמספקים את המידע השימושי ביותר הם אלה שמרוויחים הכי הרבה.
ציטוט: Ying, X., Yan, K., Gao, X. et al. IMFLKD: an incentive mechanism for decentralized federated learning based on knowledge distillation. Sci Rep 16, 10567 (2026). https://doi.org/10.1038/s41598-026-46234-1
מילות מפתח: למידת פדרציה, בלוקצ’יין, זיקוק ידע, מנגנוני תמרוץ, מערכות מוניטין