Clear Sky Science · he
חיזוי, תחביר ועיגון סמנטי במוח ובמודלי שפה גדולים
איך המוח שלך מנחש את המילה הבאה
כשאתה מאזין לסיפור, לעיתים קרובות זה נראה קל לעקוב — אבל מתחת לפני השטח המוח שלך מנחש ברציפות מה יגיע בהמשך. במקביל, מערכות בינה מלאכותית מודרניות כמו מודלי שפה גדולים גם מנבאות מילים קרובות כדי להפיק טקסט זורם. מחקר זה מאחד את שני העולמות הללו, ושואל כיצד המוח האנושי צופה מילים בזמן אמת וכיצד התהליכים האלה משווים לאופן שבו מודל מתקדם של AI פועל.
האזנה לסיפור במעבדה
כדי לחקור הבנה של שפה טבעית, החוקרים עברו מעבר לרשימות מלאכותיות של מילים או משפטים קצרים ומבודדים. במקום זאת, 29 מתנדבים צעירים הקשיבו לכ-50 דקות של ספר שמע מדע בדיוני בגרמנית בעוד פעילות המוח שלהם הורשמה. נעשה שימוש בשתי טכניקות משלימות בו-זמנית: אלקטרואנצפלוגרפיה (EEG), שמודדת שינויים זעירים במתח על הקרקפת, ומגנטואנצפלוגרפיה (MEG), שמזהה את השדות המגנטיים הנוצרים מפעילות המוח. יחד, שיטות אלה יכולות לעקוב אחרי תגובות המוח לכל מילה ברזולוציית מילישניות בזמן שאנשים עוקבים אחרי עלילה רציפה.
מעקב אחרי סוגי מילים שונים
הספר הקולי הופץ אוטומטית למילים בודדות וסומנו לפי סוג דקדוקי: שמות עצם (כמו "כוכב לכת"), פעלים (כמו "לרוץ"), שמות תואר (כמו "אפל"), ושמות פרטיים. עבור כל מילה בסיפור, המדענים גזרו חלון זמן קצר מתוך אותות ה‑EEG וה‑MEG לפני ואחרי דיבור המילה ואז ממוצעו קטעים אלה בתוך כל קטגוריית מילים. הדבר חשף "חותמות" חשמליות ומגנטיות אמינות לסוגי המילים השונים, כולל רכיבים ידועים הקשורים למשמעות ולמבנה המשפט. חשוב מכך, הצוות מצא שהפעילות עבור שמות עצם התחילה להיבנות אפילו לפני שהמילה החלה בפועל, מה שמרמז שהמוח היה מוכן במיוחד לסוג מילה זה בהקשר.
שם המשמעות פוגשת תנועה
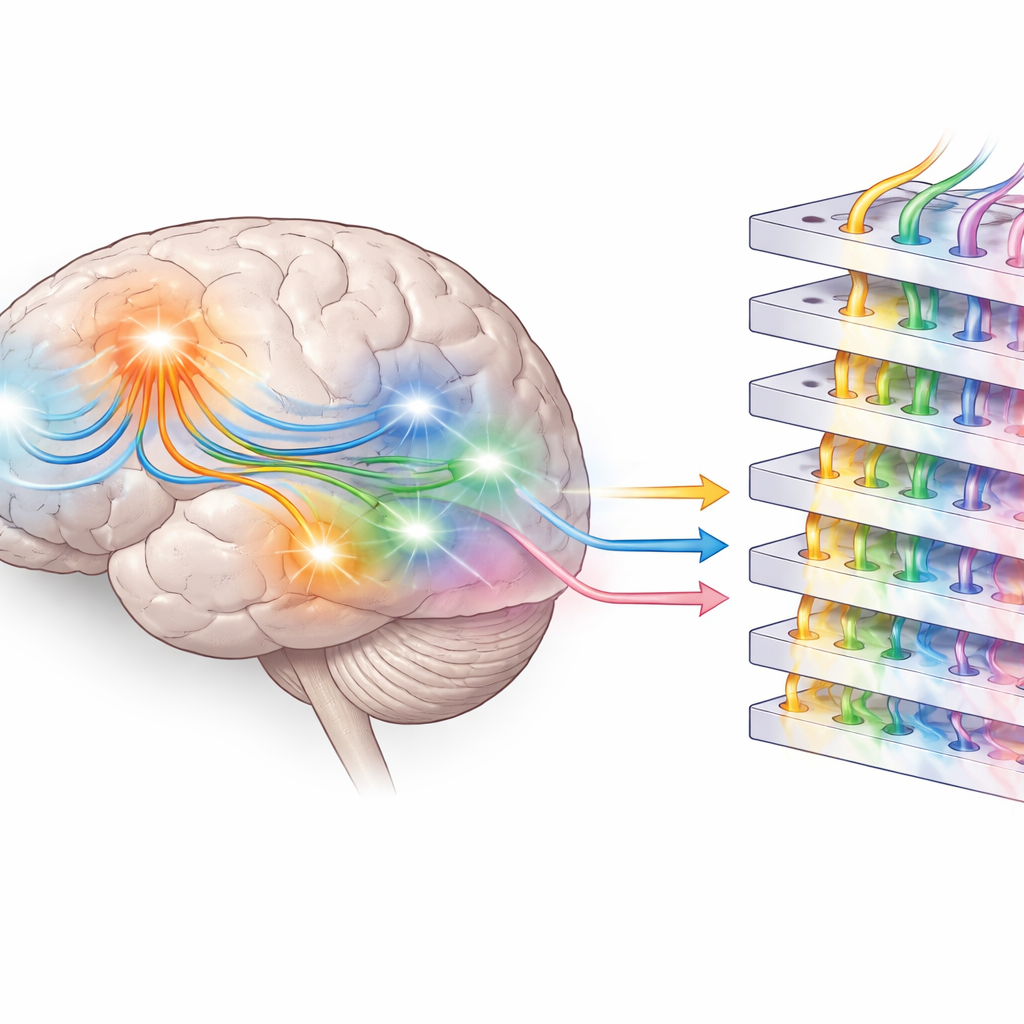
כדי לראות היכן במוח אותות אלה עלו, החוקרים השתמשו במודלים ממוחשבים כדי לאמוד את המקורות הסבירים של דפוסי ה‑MEG וה‑EEG בתוך הראש. שמות עצם לא הפעילו רק אזורים קלאסיים של שפה באונות הרקות; הן גם גייסו אזורים התואמים חלקים ממערכת הסנסורימוטורית, בסמוך לאזורים המעורבים בתנועה ובתחושת הגוף. פעלים, לעומת זאת, הראו דפוס שונה ומוגבל יותר. זאת תומכת ברעיון של שפה "מגושמת" (embodied), שבו הבנת מילה — במיוחד שם עצם מוחשי — מחזרת חלקית רשתות הקשורות לתפיסה ולפעולה, ועוגנת את המשמעות בחוויות תחושתיות עבריות ולא רק בכללים אבסטרקטיים.
השוואה בין מוח למודלי שפה גדולים
הצוות פנה אחר כך למודל השפה Llama 3.2 של Meta כדי לספק נקודת ייחוס חישובית. תחילה הם בדקו "חיזוי סמנטי" על ידי הזנת ההקשר הקודם מתוך הספר הקולי למודל ושאלו עד כמה המודל מדיר את המילה האמיתית הבאה ככניסה סבירה. שמות עצם התגלו כפשוטות לחיזוי ביותר עבור המודל, תואם לתפקיד המרכזי שלהם בבניית העלילה. לאחר מכן חקרו החוקרים "חיזוי תחבירי" על ידי בחינת ההפעלות הפנימיות, או ההטמעות, בתוך Llama. אפילו ללא אימון נוסף, השכבות החבויות של המודל קיבצו באופן טבעי מילים לפי סוג הדקדוק של המילה הבאה, ורשת פרוב פשוטה יכלה לעתים קרובות לקבוע איזו קטגוריית מילה תגיע בהמשך. לאורך השכבות, המבנה הפנימי עבור שמות פרטיים ושמות עצם הפך מובחן יותר, מהדהד את ההפרדה ההולכת וגדלה בתפקודים שנצפתה בדפוסי הפעילות במוח.
שני סוגי מוכנות למילים
ביחד, הממצאים מציעים שהמוח מתכונן לשפה הבאה לפחות בשני רבדים. באזורים טמפורליים, פעילות לפני הופעת המילה נראית כהכנה דקדוקית או "תחבירית" — ידע על היכן סוגי מילים מסוימים נוטים להופיע במשפט. באזורים חזיתיים וסנסורימוטוריים יותר, דפוסי המוכנות נושאים ציפיות סמנטיות עשירות יותר הקשורות למשמעות ולחווייה, במיוחד עבור שמות עצם ושמות. מודלי שפה גדולים, שאומנו רק לחזות את המילה הבאה, מפתחים מבנים פנימיים רב-שכבתיים משלהם שמעתיקים חלקית את ההבחנות האלה, אך הם חסרים עיגון ישיר בעולם הפיזי. על ידי שילוב הקלטות מוח במהירות גבוהה עם ניתוחים של AI חדיש, עבודה זו מסייעת להבהיר כיצד בני אדם מצפים למילים במהלך האזנה יומיומית ועד כמה המכונות של היום התקרבו להיקף זה של הבנת שפה אנושית.
ציטוט: Kölbl, N., Rampp, S., Kaltenhäuser, M. et al. Prediction, syntax and semantic grounding in the brain and large language models. Sci Rep 16, 8728 (2026). https://doi.org/10.1038/s41598-026-41532-0
מילות מפתח: חיזוי שפה, מוח ובינה מלאכותית, מודלי שפה גדולים, עיגון סמנטי, EEG MEG שפה