Clear Sky Science · he
KM-DBSCAN: מסגרת משופרת לזיהוי גבולות מבוססת צפיפות וסנטראודים לצמצום נתונים לקראת בינה מלאכותית ירוקה
מדוע הקטנת ה-AI יכולה להפוך אותו לירוק יותר
לבינה המלאכותית יש מחיר נסתר: חשמל. אימון מודלים מודרניים של למידת מכונה לעיתים קרובות דורש עיבוד של מיליוני נקודות נתונים על חומרה צורכת־אנרגיה, דבר המייצר פליטות פחמן. המאמר מציג את KM-DBSCAN, דרך חדשה לכווץ ערכות נתונים לפני אימון מבלי לזרוק את המידע שהמודלים זקוקים לו באמת. על ידי שמירה רק על הנתונים המידעיים ביותר, השיטה מואצת את הלמידה, מקטינה את צריכת האנרגיה ועדיין מספקת תחזיות מדויקות במשימות שמתחילות מזיהוי ספרות בכתב יד ועד לזיהוי מוקדם של סרטן העור.
יותר מדי נתונים, יותר מדי אנרגיה
שנים רבות האמונה השלטת ב-AI הייתה שיותר נתונים כמעט תמיד מובילים למודלים טובים יותר. אמנם זה יכול לשפר את הדיוק, אך גם מאריך זמני אימון, דורש מחשוב חזק יותר ומעלה את חשבון החשמל. חוקרים החלו להבחין בין "Red AI" — שרודף אחרי דיוק בכל מחיר — לבין "Green AI" — שמנסה לאזן בין ביצועים להשפעה סביבתית. נתיב מבטיח לעבר AI ירוק יותר הוא צמצום נתונים: במקום להאכיל את המודל בכל דוגמה זמינה, לזהות קבוצה קטנה בהרבה של מקרים שעדיין מגדירים היטב את הבעיה, במיוחד את מקרים הגבול המורכבים שקובעים את החלטות הממיין.
שילוב שתי רעיונות פשוטים למסנן חכם אחד
מסגרת KM-DBSCAN משלבת שתי טכניקות קיבוץ ידועות לפעול כמסנן אינטיליגנטי על הנתונים הגולמיים. ראשית, שיטה מהירה שנקראת K-Means מקבצת נקודות לצברים קומפקטיים ומחליפה כל קבוצה במרכז מייצג, או סנטראויד. זה מצמצם את הבעיה מאלפים או מליוני נקודות לכמה מאות ייצגיות. לאחר מכן, מריצים שיטה מבוססת צפיפות (DBSCAN) על אותם סנטראוידים כדי למצוא אילו אזורים נמצאים בגבולות בין הצברים ואילו הם פנים צפופים והומוגניים או רעש מבודד. על ידי עבודה ברמת הסנטראוידים, DBSCAN נעשה מהיר בהרבה ופחות רגיש לבחירות פרמטרים דקדקניות מאשר כאשר הוא מיושם ישירות על כל נקודות הנתונים.

שמירה רק על המקרים הקשים והמידעיים
לאחר ש-KM-DBSCAN מזהה היכן קבוצות שונות נוגעות או חופפות, הוא שומר רק את נקודות הנתונים שנמצאות בקרבת גבולות אלה ומסרב הן נקודות פנים עמוקות והן חריגים ברורים. נקודות פנימיות מיותרות ברובן: כולן נראות דומות ומעבירות למודל את אותה הודעה לגבי המחלקה שלהן. נקודות גבול, בניגוד לכך, אומרות למודל בדיוק היכן מסתיים שיעור אחד ומתחיל אחר. על מערכי נתונים מלאכותיים קטנים, אסטרטגיה זו משחזרת את אותן גבולות החלטה שממיין לומד מהנתונים המלאים, אפילו כאשר רוב הנקודות מוסרות. על מערכי נתונים מהעולם האמיתי כגון Banana, ספרות USPS, מערך נתוני הכנסות Adult, נתוני התנגשות כלי רכב, זני שעועית יבשה ותמונות עור של מלנומה, הקבוצות המוקטנות שומרות על המבנה המרכזי של הבעיה בעוד שהן קטנות בסדרי גודל.
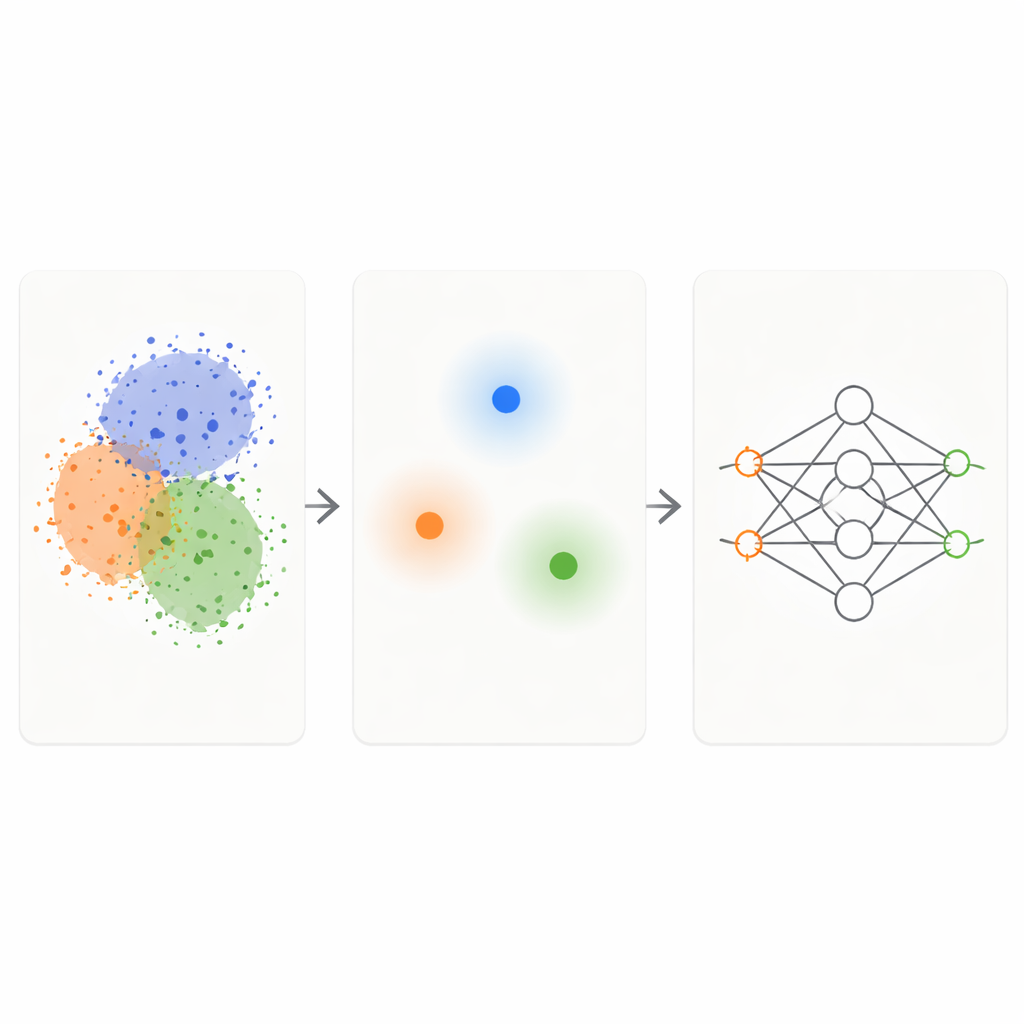
מהירות, חיסכון בפחמן ויישומים אמיתיים
המחברים בחנו את KM-DBSCAN כקדם־עיבוד למספר מודלים פופולריים, כולל מכונות וקטור תמיכה, פרספטרונים רב־שכבתיים ורשתות עצביות קונבולוציוניות. במקרים רבים, אימון על הנתונים המוקטנים היה מהיר בעשרות עד אלפי מונים תוך שמירה על דיוק כמעט זהה—ולפעמים אף שיפור קל. לדוגמה, בזיהוי ספרות בכתב יד, השיטה צמצמה את סט האימון ל-1.4% בלבד מגודלו המקורי ועדיין העלתה במעט את הדיוק, תוך שהאימון נעשה מהיר פי 284. במשימת חיזוי הכנסה עם מחלקות בלתי מאוזנות, הושג מהלך מהיר של פי 6907 באמצעות כ-3% בלבד מהנתונים עם אובדן מינימלי בדיוק. בניסוי לזיהוי מלנומה, רשת עצבית עמוקה הגיעה ליותר מ-90% דיוק בזמן שאימנה על פחות משליש ממאגר תמונות העור המקורי, עם הפחתה בפליטות הפחמן של למעלה מ-70%.
מה המשמעות של זה ל-AI יומיומי
ללא־מומחים, המסר המרכזי הוא שקביעה חכמה יכולה לגבור על כמות טהורה. KM-DBSCAN מראה כי בחירה מדוקדקת של הדוגמאות שהמודל רואה — התמקדות במקרי הגבול המידעיים ביותר — יכולה לקצץ בזמן מחשוב ובצריכת אנרגיה תוך שמירה על אמינות התחזיות. גישה זו משתלבת היטב בדחיפה הרחבה ל-Green AI, שבה איכות הנתונים ועיצוב שקול של צינורות האימון חשובים לא פחות מגודל המודל. אם תתקבל באופן נרחב, סינון מודע־נתונים כזה יכול להפוך כל דבר מאנליזת תמונות רפואיות ועד מערכות בטיחות תנועה לברי־קיימא יותר, ולהנגיש כלי AI חזקים לארגונים שאין בידם משאבי מחשוב עצומים.
ציטוט: AboElsaad, M.Y., Farouk, M. & Khater, H.A. KM-DBSCAN: an enhanced density and centroid based border detection framework for data reduction towards green AI. Sci Rep 16, 10349 (2026). https://doi.org/10.1038/s41598-026-40062-z
מילות מפתח: בינה מלאכותית ירוקה, צמצום נתונים, קיבוץ, יעילות בלמידת מכונה, זיהוי מלנומה