Clear Sky Science · he
R-GAT: סיווג מסמכי סרטן תוך שימוש ברשת שאריתית מבוססת גרף לתרחישים עם נתונים מוגבלים
מדוע מיון מאמרי סרטן חשוב
יום־יום מדענים מפרסמים מאות מחקרים חדשים על סרטן, החל מזיהוי מוקדם ועד תרופות מבטיחות. רוב העבודות האלו מופיעות תחילה כסיכומים קצרים שנקראים תקצירים. רופאים, חוקרים וקובעי מדיניות אינם יכולים לקרוא את כולם, אך החמצת מאמר חשוב עלולה להאט את ההתקדמות. המחקר הזה עוסק בשאלה פשוטה אך מועילה: האם ניתן לבנות מערכת מחשוב מהירה וקלה שמשייכת אוטומטית תקצירים על סרטן לפי סוג, גם כאשר כמות הדאטה המתויגת וכח המיחשוב מוגבלים?
דרך חכמה יותר לקרוא מחקר על סרטן
המחברים מתמקדים בארבעה סוגי תקצירים שנמצאים במאגר PubMed: תקצירים על סרטן של בלוטת התריס, סרטן המעי הגס, סרטן הריאה ונושאים ביומדיים כלליים. הם הרכיבו אוסף מבוקר של 1,875 תקצירים עדכניים, בגודלם הנעשה כמעט שווה בין ארבעת הקבוצות. איזון זה מסייע למנוע הטיה כלפי סוג סרטן בודד. לפני המודלינג, הטקסטים עובדו ונוקו: מילים פורקו ליחידות (טוקנים), איות נבדק, צורות קרובות של מילים מוזגו ומונחים שאינם מידעיים הוסרו. התקצירים המעובדים הומרו לאחר מכן לייצוגים מספריים בעזרת שיטות סטנדרטיות שונות, כדי לאפשר השוואה הוגנת בין סוגי מודלים.
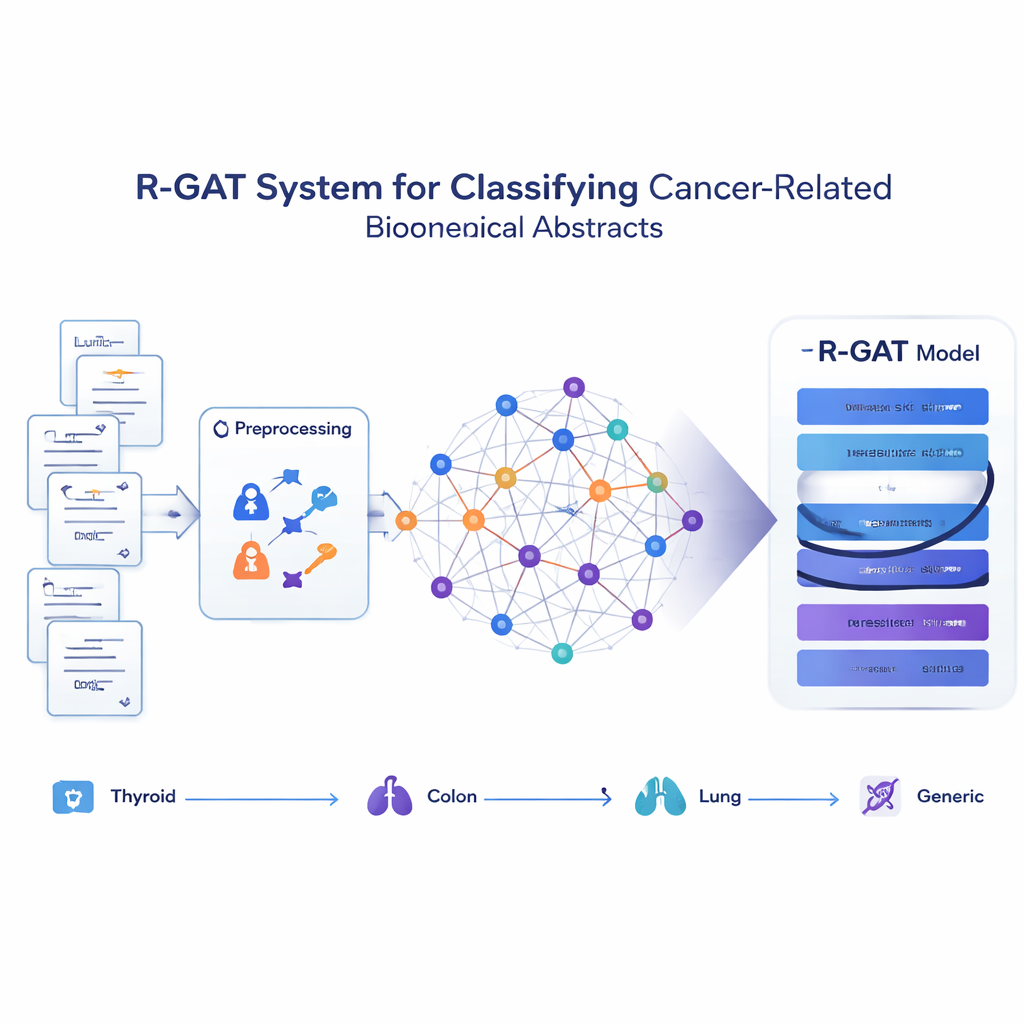
הפיכת המאמרים לרשת של רעיונות
במקום להתייחס לכל תקציר כמחרוזת מילים מבודדת, השיטה המוצעת, שנקראת R-GAT (Residual Graph Attention Network), רואה את אוסף התקצירים כרשת. ברשת הזו כל תקציר הוא צומת, והקשרים מייצגים עד כמה שני תקצירים דומים בתוכן. אם שני מאמרים דנים בנושאים קרובים, הקשר ביניהם חזק; אם לא — הוא חלש או לא קיים. גישה זו מאפשרת למודל לבחון תקציר בהקשר של שכניו, בדומה לאופן שבו קורא אנושי עשוי להבין מחקר טוב יותר באמצעות ידיעה על עבודות קשורות.
איך המודל החדש לומד מהממונים עליו
R-GAT מבוסס על שתי רעיונות מרכזיים מבינה מלאכותית מודרנית: מנגנון תשומת לב (attention) וחיבורים שאריתיים (residual connections). תשומת לב מאפשרת למודל להתמקד יותר בשכנים הרלוונטיים ברשת במקום להתייחס לכל השכנים באותה מידה. כמה "ראשים" של תשומת לב מחפשים בו־זמנית דפוסים מסוגים שונים. החיבורים השאריתיים פועלים כקיצורי דרך שמעבירים מידע דרך שכבות עמוקות של הרשת, ועוזרים למודל לא לאבד אותות חשובים בזמן הלמידה. לאחר עיבוד הגרף דרך מספר שכבות תשומת לב ודרכים קצרות אלו, המערכת מדחסת את המידע מכל הרשת לסיכום קומפקטי המוזן לממיין סופי שמנבא לאיזו מתוך ארבעת הקטגוריות כל תקציר שייך.
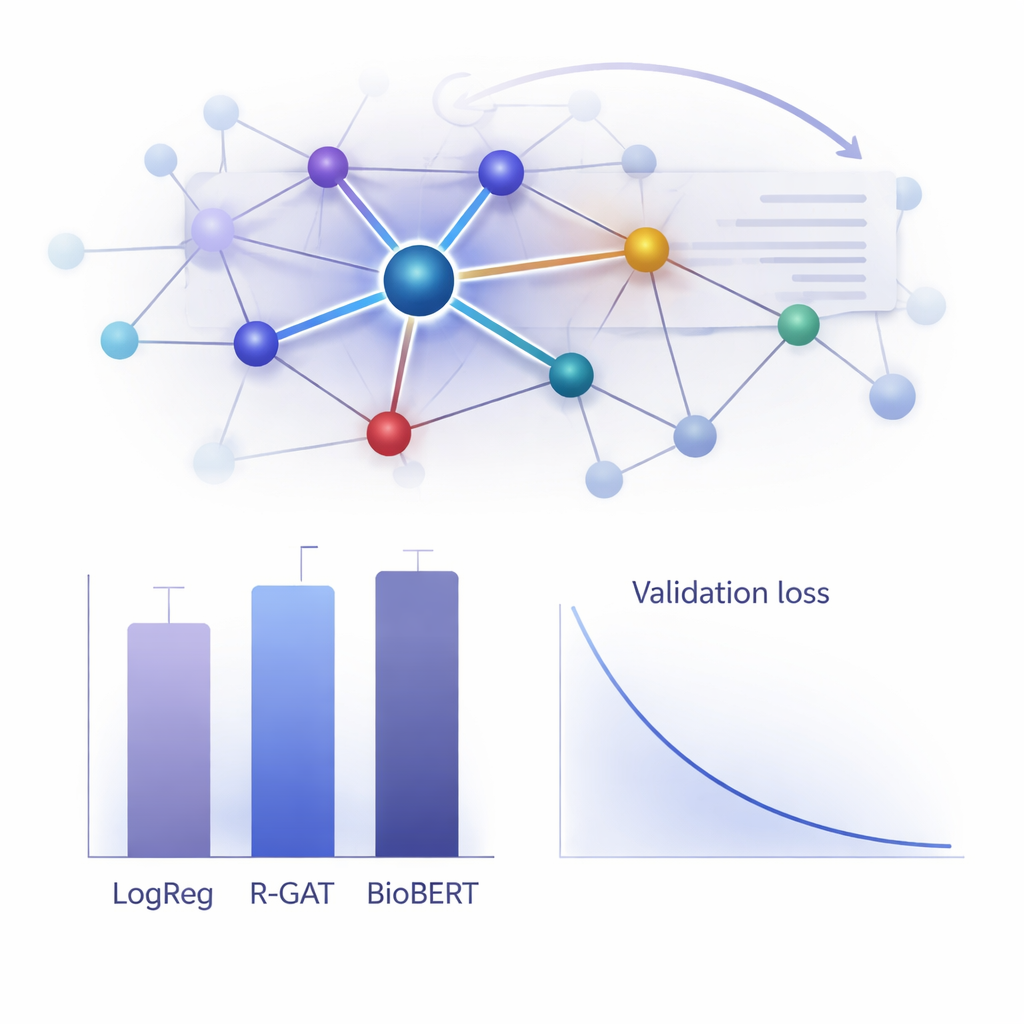
כמה טוב זה עובד בפועל?
כדי להעריך את ערך ה‑R-GAT, המחברים השוו אותו למגוון רחב של חלופות — ממודלים ליניאריים קלאסיים ועד מערכות טרנספורמר מתקדמות כמו BioBERT, הפופולריות אך דורשות משאבים גבוהים. באופן מפתיע, מודל לוגיסטי פשוט שהשתמש בתכונות של ספירת מילים השיג את הציון הגולמי הגבוה ביותר על מערך הנתונים הזה, ו‑BioBERT גם ביצע מצוין — אך לשניהם יש חסרונות, כולל תלות בבחירת תכונות ספציפית או בצורך במשאבי חישוב ניכרים. R-GAT השיג ציון F1 מקדם (macro) של כ־0.96, קרוב למודלים הטובים ביותר, והציג תוצאות יציבות מאוד בחלוקות אימון־מבחן שונות. ניסויים מבוקרים שבהם הוסר מנגנון התשומת לב או החיבורים השאריתיים הראו ירידות ביצועים ברורות, ואישרו ששני המרכיבים חיוניים לעמידות המודל בתנאי נתונים מוגבלים.
מה זה אומר למחקר הסרטן בעתיד
עבור הקורא הלא מקצועי, המסקנה פשוטה: R-GAT הוא כלי מעשי המסייע למיין מאמרי מחקר על סרטן לפי סוג הסרטן בדיוק גבוה ועקבי, ללא צורך במאגרי נתונים ענקיים או בחומרה יקרה. הוא אינו מחליף את המודלים הלשוניים החזקים ביותר בשוק, אך מציע פתרון אמין ובינוני — שימושי במיוחד לבתי חולים, קבוצות מחקר או צוותי בריאות ציבור שצריכים תוצאות אמינות ושחזרות במסגרת מגבלות של נתונים ותקציב. על ידי פרסום המודל ומערך הנתונים המנוקה שלהם באופן פתוח, המחברים מספקים גם נקודת ייחוס משותפת שאחרים יכולים להשתמש בה כדי לבנות ולבחון מערכות משופרות. בטווח הארוך, כלים כאלה עשויים להקל משמעותית על מומחים להישאר מעודכנים בספרות הסרטן ולהפוך ממצאים חדשים לטיפול טוב יותר.
ציטוט: Hossain, E., Nuzhat, T., Masum, S. et al. R-GAT: cancer document classification leveraging graph-based residual network for scenarios with limited data. Sci Rep 16, 6582 (2026). https://doi.org/10.1038/s41598-026-39894-6
מילות מפתח: אינפורמטיקה של סרטן, חילוץ טקסט ביורפואי, סיווג מסמכים, רשתות נוירונים גרפיות, למידה עם נתונים מוגבלים