Clear Sky Science · he
מסגרת התאמת איזון נתונים לחיזוי סיכוני תנועה בזמן אמת
מדוע איזון נתוני תנועה חשוב לבטיחות
תאונות בכבישים מהירים הן אירועים נדירים לעומת כמות הנהיגה השגרתי והחסרת אירועים. זו חדשות טובות מבחינת בטיחות, אבל זה מייצר בעיה נסתרת עבור מחשבים שמנסים לחזות בזמן אמת מתי והיכן עלולות להתרחש תאונות. כאשר הנתונים נשלטים על ידי מצבי בטיחות, האלגוריתמים יכולים להפוך למאוד טובים בחיזוי "לא יקרה כלום" ולראות מדויקים על הנייר—בעוד שהם מפספסים בשקט את הרגעים המסוכנים באמת. המחקר הזה מתמודד עם חוסר האיזון באופן ישיר, ומציע שיטה אדפטיבית ל"לאזן מחדש" את נתוני התנועה כך שמערכות אזהרה יוכלו לזהות טוב יותר מצבים נדירים אך חשובים מבלי להפוך לאיטיות מדי לשימוש מעשי.
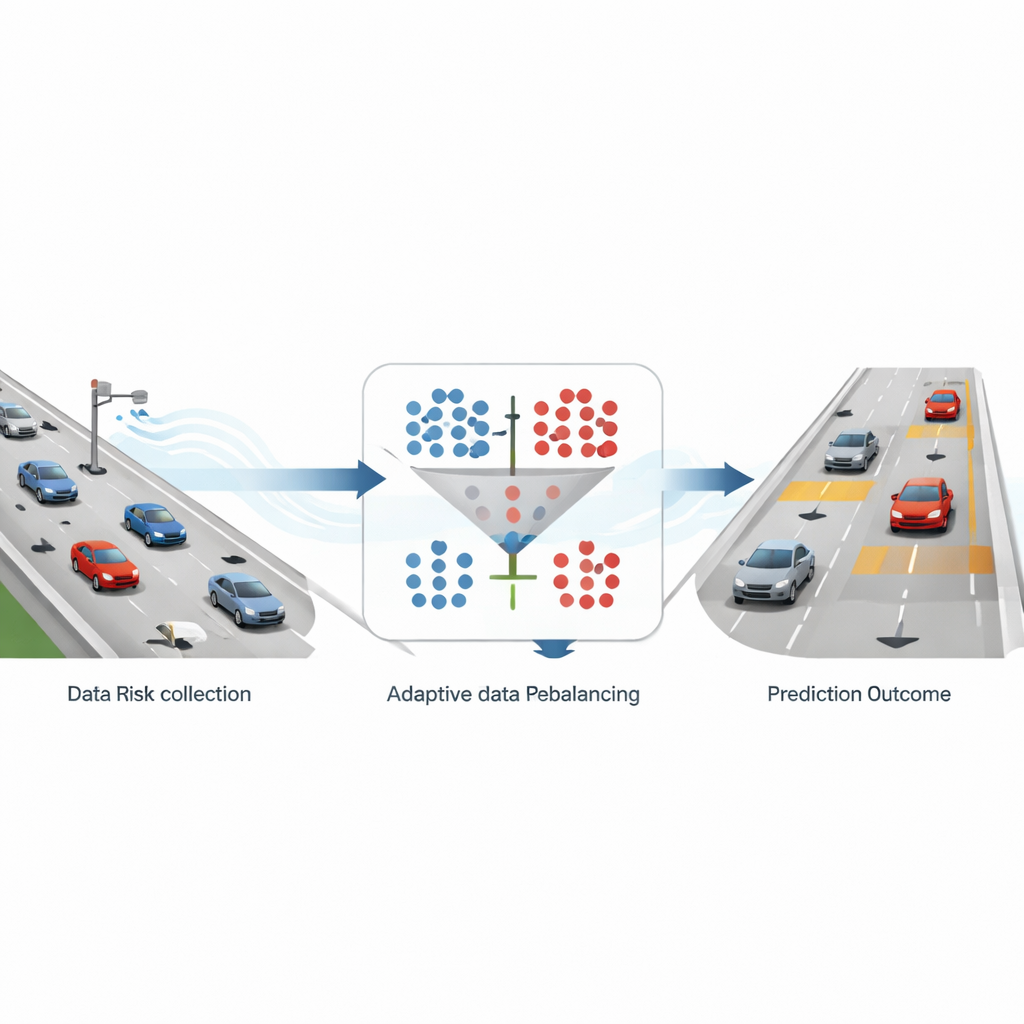
כיצד תנועה אמיתית מומרת לאותות אזהרה
החוקרים בונים את המסגרת שלהם על נתוני מסלולים מפורטים בכבישים מהירים ממאגר נתונים גדול המבוסס על רחפנים שצילמו קטעי כביש בגרמניה. מיקום ומהירות של כל רכב מתועדים פעמים רבות בשנייה לאורך מקטעים של כביש שש-נתיבי. מהרקורד התנועתי העשיר הזה הצוות מחשב מדד בטיחות נפוץ שנקרא זמן עד התנגשות, שמעריך כמה זמן ייקח לרכב עוקב לפגוע ברכב שלפניו אם שניהם ימשיכו במצבם הנוכחי. כאשר זמן זה יורד מתחת לשלוש שניות, המצב מתויג כ"סיכון גבוה"; אחרת הוא מוגדר כ"ללא סיכון". לאחר ריכוז מדדים אלה בפרוסות של 10 שניות והתמקדות בכבישים שש-נתיביים, הם מגיעים לכדי בערך תשעה דגימות בטוחות על כל דגימה מסוכנת, מערך נתונים מוטה שמחקה את תנאי הכביש המהיר במציאות.
תיקון ההטיה בלי לאבד את החשוב
כדי להתמודד עם ההטיה הזו, המחקר משווה שתי אסטרטגיות נפוצות. האחת, שנקראת oversampling, מוסיפה דוגמאות נוספות של מצבים מסוכנים נדירים על ידי יצירת דגימות סינתטיות הדומות למקרים מסוכנים אמיתיים. השנייה, undersampling, מצמצמת את המקרים הרבים הבטוחים על ידי סילוק אקראי של חלק מהם. הכותבים משתמשים בשיטת oversampling פופולרית (SMOTE) ובשיטת undersampling אקראית פשוטה, ומיישמים אותן ביחסים קבועים שונים בין דגימות בטוחות למסוכנות—1:1, 2:1, 3:1, ו-4:1. לאחר מכן הם מזינים הן את מערכי הנתונים המקוריים והן את המותאמים לארבעה מודלים לחיזוי: שתי גישות מסורתיות של למידת מכונה ושני מודלים של למידה עמוקה שמתמחים בטיפול בסדרות זמן. באמצעות בדיקת כל הצירופים הללו הם יכולים לראות כיצד דרכים שונות לאיזון הנתונים משנה את יכולת המערכת לאתר סיכון תוך שמירה על זיהוי מצבים בטוחים.
מאפשרים לאלגוריתם לחפש את נקודת האיזון האופטימלית
במקום להניח שמספרים שווים של דגימות בטוחות ומסוכנות הם הטובים ביותר, החוקרים מאתרים באמצעות אלגוריתם גנטי—שיטת חיפוש בהשראת אבולוציה—את איזון הנתונים היעיל ביותר. מאיץ זה מתאים את יחס הבטוחות אל מול המסוכנות בטווח ריאלי בין 1:1 ל-4:1, מייצר שוב ושוב יחסים מועמדים, מעריך אותם ומלטש אותם לאורך מאות איטרציות. באופן מכריע, הוא לא מסתכל רק על דיוק החיזוי: הוא גם מתחשב בזמן שהמודל לוקח לאימון ולחזויים, משקף את הדרישות בזמן אמת של מרכזי בקרה תעבורתיים. כדי לשלב בצדק מדדי דיוק וזמן חישוב, כל המודדים מנורמלים לפני שהם מאוחדים לציון "כושר" יחיד שהאלגוריתם מנסה למזער.
מה המודלים לומדים על סיכון בכביש
לאורך הניסויים הרבים, דפוס אחד בולט. איזון הנתונים משפר את חיזוי הסיכון יחסית להשארת ההטיה המקורית, ו-oversampling עם דגימות מסוכנות סינתטיות נוטה לעבוד טוב יותר מאשר השלכת דוגמאות בטוחות. יחס של 2:1 בין בטוחות למסוכנות נותן את הביצועים הטובים ביותר מבין ההגדרות הקבועות, ומציג ביצועים טובים יותר מהבחירה הנפוצה 1:1. כאשר האלגוריתם הגנטי מורשה לכוונן יחס זה, הוא מגיע לערכים מעט לא שווים אך מיטביים—כ≈2.3:1 עבור oversampling וכ≈2.7:1 עבור undersampling. בין מודלי החיזוי, סוג ספציפי של רשת עצבית חוזרת הידוע כ-gated recurrent unit מניב בעקביות את התוצאות החזקות ביותר, במיוחד כשהוא משולב עם oversampling ואופטימיזציה. המודלים גם מגלים שמשכי המהירות הממוצעים של כלי הרכב לפני ואחרי נקודה בכביש הם אינפורמטיביים יותר לגבי סיכון מאשר ספירות פשוטות של רכבים.
בדיקת יציבות והכנה לעולם האמיתי
מכיוון ששיטות אופטימיזציה עלולות לעיתים להיתקע בפתרונות מטעות, הכותבים בודקים כיצד החיפוש שלהם מתנהג לאורך זמן. הם מראים כי ציוני הכושר יורדים בהדרגה ולבסוף מתייצבים, מה שמרמז שהאלגוריתם מתכנס ליחסים יציבים ואיכותיים במקום לנדוד בין פתרונות. לאחר מכן הם מזיזים קלות את היחסים שנבחרו למעלה ולמטה באחוזים בודדים כדי לראות האם הביצועים קורסים. בפועל הדיוק יורד רק במעט בשינויים קטנים, מה שמצביע על כך שהמערכת חסינה ולא מכווננת יתר על המידה להגדרה בודדת ושברירית. עם זאת, כאשר חלק הנתונים שמור לניסוי גדל מאוד, המודלים נעשים רגישים יותר, מה שמדגיש את הצורך בנתוני אימון עשירים מספיק.
מה משמעות הדבר לכבישים בטוחים וחכמים יותר
במונחים יום־יומיים, המחקר מראה שלהעניק למחשבים את היכולת לזהות סכנה בכביש לא מבוסס רק על מודלים חכמים; זה תלוי גם בהזנתם בתמונה הוגנת של אירועים נדירים אך קריטיים. על ידי כוונון מדוד של כמות הדוגמאות הבטוחות והמסוכנות שמשתמשים בהן לאימון—ואת מתן אלגוריתם אדפטיבי שמוצא את הפשרה הטובה ביותר בין דיוק ומהירות—המסגרת המוצעת הופכת את חיזוי הסיכון בכבישים בזמן אמת לאמין יותר ומעשי יותר. סוכנויות תנועה יכולות לשלב גישה זו במערכות שמנתחות נתוני חיישנים תעבורתיים ומנפיקות אזהרות מוקדמות לגבי התנגשות מאחור צפויה, ובכך לסייע בהכוונת התראות לנהגים, פריסת משטרות או אסטרטגיות בלימת חירום אוטומטיות. בעוד שהעבודה הוצגה על כבישי מהירות גרמניים בתנאי מזג אוויר טובים, הרעיון הבסיסי של איזון נתונים אדפטיבי מציע מתכון כללי לשיפור חיזוי בטיחות בכל מקום שבו אירועים מסוכנים נדירים אך חשובים מדי שלא לפספס.
ציטוט: Chen, S., Cui, B. & Chang, A. An adaptive data rebalancing framework for real-time traffic risk prediction. Sci Rep 16, 8882 (2026). https://doi.org/10.1038/s41598-026-39539-8
מילות מפתח: בטיחות תנועה, חיזוי סיכון תאונות, נתונים לא מאוזנים, למידת מכונה, מסלולים בכבישים בין-עירוניים