Clear Sky Science · he
מודל ויז'ן-שפה רפואי תלת־ממדי יעיל-נתונים המשתמש רק בקודד דו־ממדי
עזרה חכמה יותר מסריקות תלת־ממדיות
כשרופאים קוראים סריקות CT או MRI, הם לא מסתכלים רק על תמונות בודדות — הם מרכיבים בראשם מאות פרוסות כדי להבין בעיה בתלת־ממד. ללמד מחשבים לעשות את אותו הדבר עשוי לתמוך באבחונים מהירים ועקביים יותר ובדיווחים ברורים יותר למטופלים. אבל מערכות בינה מלאכותית נוכחיות המטפלות בסריקות תלת־ממדיות נוטות להיות "רעבות־נתונים" — הן זקוקות למאגרי נתונים עצומים ומסומנים בקפידה שלרוב בתי חולים אין. מאמר זה מציג דרך להשיג הבנה ברמת תלת־ממד מתוך טכנולוגיית תמונה דו־ממדית קיימת, ומבטיח כלים רבי־עוצמה שקל וזול יותר לבנות ולפרוס.
מדוע סריקות תלת־ממד קשות לבינה מלאכותית
מערכות מודרניות של "ויז'ן–שפה" כבר מסוגלות להסתכל על תמונה רפואית דו־ממדית ולענות על שאלות או לנסח דוח בשפה טבעית. הרחבת היכולת הזו לנפחים תלת־ממדיים הייתה מאפשרת ל-AI להסיק מסקנות על איברים שלמים ופגעים עדינים שמתגלעים רק כשהרואים הרבה פרוסות יחד. הבעיה היא שרוב המערכות התלת־ממדיות מבוססות כיום על קודדי תמונה תלת־ממדיים מיוחדים המותאמים מאפס על אוספים עצומים של סריקות מסומנות. מאגרי נתונים כאלה נדירים, יקרים לסימון, ולעתים קרובות קשורים למרכזים בעלי משאבים, מה שמגביל מי יכול להפיק מהם תועלת. במקביל, ההתייחסות לכל פרוסה כאל תמונה דו־ממדית נפרדת מטילה לצד את הרצף הטבעי בין הפרוסות וטובעת את המודל במידע חזרתי.
להשתמש במומחה דו־ממדי לעבודת תלת־ממד
המחברים מציעים מסלול שונה: במקום לאמן קודד תלת־ממדי חדש, הם ממחזרים מודל תמונה רפואי דו־ממדי חזק שכבר אומן על מיליוני תמונות מסומנות מהספרות הרפואית. הם קודם חותכים כל סריקה תלת־ממדית לפרוסות בודדות ומאפשרים למודל הדו־ממדי לחלץ תכונות מפורטות מכל פרוסה. לאחר מכן הם מקצצים בקפידה את העודף: מכיוון שפרוסות סמוכות בסריקה לרוב דומות כמעט לחלוטין, בדיקת דמיון יכולה להסיר רבות מהכפילויות תוך שמירה על התצוגות המידע־עשירות ביותר. שלב זה כשלעצמו מצמצם את כמות הנתונים שהשלבים הבאים צריכים לטפל בה, ללא צורך בסריקות מסומנות נוספות.
לבנות מחדש את הסיפור התלת־ממדי מחלקים
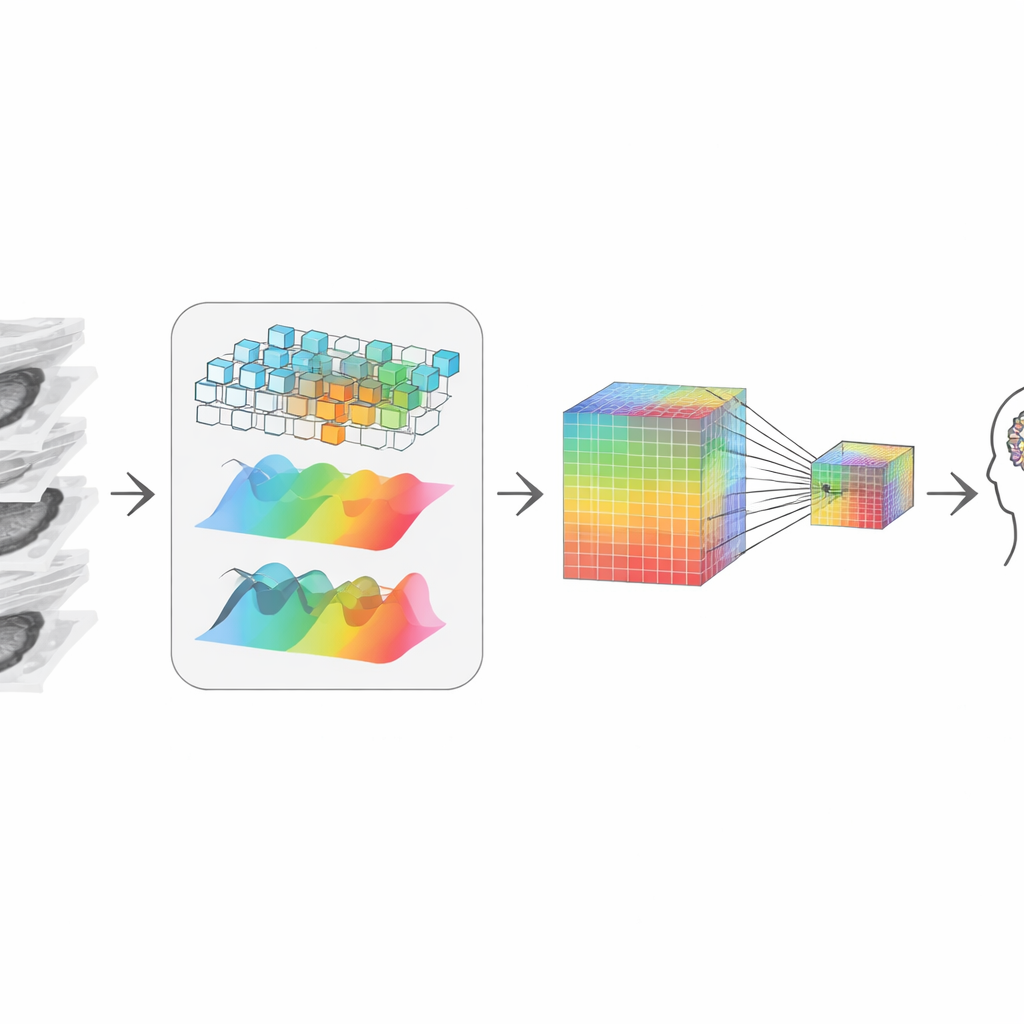
לאחר הקיצוץ, המערכת צריכה "לתפור מחדש" את הפרוסות הנותרות לתמונה תלת־ממדית אחידה. המחברים עושים זאת על ידי שילוב שתי תצפיות משלימות של הנתונים. מסלול אחד מתמקד בצורות ובקצוות מקומיים, כמו זכוכית מגדלת הנעה דרך הנפח, רגיש לגבולות חדים ומרקמים. המסלול השני ממיר את הנתונים לתצפית בתדרים, המתאימה ללכידת דפוסים רחבים ומבנה טווח־ארוך על פני הפרוסות — איך גידול מתפשט או כיצד צורת האיבר בצורתה הכללית. שלב מיזוג אדפטיבי לומד כמה להסתמך על כל תצפית בכל נקודה, ומפיק ייצוג המכבד גם פרטים דקים וגם הקשר גלובלי, אף על פי שהתחיל מפרוסות דו־ממדיות.
שמירה על רמזים זעירים תוך דחיסה
כדי לתקשר עם מודל שפה גדול — החלק שמגיב לשאלות וכותב דוחות — המידע הוויזואלי צריך להיות דחוס למספר צנוע של טוקנים, או "מילים ויזואליות". הקטנה פשוטה תטשטש אותות זעירים אך קריטיים, כמו הסתיידויות קטנות או שינויים מרקמיים עדינים שחשובים לאבחון. כדי למנוע זאת, המחברים יוצרים ייצוג בעל שני מסלולים: אחד שומר גרסה ברזולוציה גבוהה ועשירה בפרטים, והשני הוא גרסה קטנה וזולה יותר חישובית. מנגנון קשב מאפשר לכל נקודה בגרסה הקטנה "להסתכל אחורה" לגרסה הגדולה ולשאוב את הפרטים החדים ביותר הזמינים. התוצאה היא סיכום ויזואלי קומפקטי שממשיך לשאת את הרמזים שהרדיאולוג ישים עליהם לב, ושנמסר לאחר מכן למודל השפה לצורך היסק.
הוכחה במשימות רפואיות אמיתיות
כדי לבדוק את העיצוב שלהם, החוקרים העריכו אותו על סטנדרטים תלת־ממדיים ציבוריים השואלים שתי שאלות עיקריות: האם המערכת יכולה לכתוב תיאורים מדויקים בסגנון רדיולוגי של סריקות תלת־ממד, והאם היא יכולה לענות על שאלות לגבי מה שנראה בהן? הגישה שלהם, על אף שמעולם לא אימנה קודד ייעודי לתלת־ממד, עלתה על מספר מודלים מבוססי תלת־ממד חזקים בשתי המשימות. היא הפיקה דוחות מדויקים ועשירים מבחינה קלינית יותר וענתה על שאלות בדיוק גבוה יותר, כולל שאלות קשות לגבי האיבר המדויק, החריגה או המיקום המעורב. היא גם פעלה מהר יותר ודרשה הרבה פחות נתוני אימון תלת־ממדיים, והכלילה היטב לסוגי סריקה שונים כמו MRI ו-PET.
מה משמעות הדבר לטיפול בעתיד
במילים פשוטות, עבודה זו מראה שאין צורך להתחיל מאפס עם מודלים תלת־ממדיים רעבי־נתונים כדי לקבל סיוע איכותי מ‑AI בסריקות נפחיות. על ידי מחזור חכם של מומחה דו־ממדי חזק, בחירה קפדנית של פרוסות מידע ומשחזור התמונה התלת־ממדית תוך שמירה על פרטים זעירים, המחברים משיגים ביצועים בשיא התחום עם הרבה פחות נתונים וחישוב. אם תיאומץ באופן נרחב, גישה כזו עשויה להפוך סיוע AI מתקדם — כמו דוחות טובים יותר, הסברים ברורים יותר וטריאז׳ אמין יותר — לנגיש יותר לבתי חולים ומרפאות חסרי משאבי נתונים עצומים, ולהקרב ניתוח הדמיה מתוחכם לשגרת הפרקטיקה הקלינית.
ציטוט: Lian, Y., Xie, Y., Jiang, Y. et al. A data-efficient 3D medical vision-language model using only a 2D encoder. Sci Rep 16, 8809 (2026). https://doi.org/10.1038/s41598-026-39526-z
מילות מפתח: הדמיה רפואית תלת־ממדית, מודלי ויז'ן-שפה, בינה מלאכותית ברדיולוגיה, למידה יעילה-נתונים, ניתוח CT ו-MRI