Clear Sky Science · he
רשת עצבית קונבולוציונלית מקצה‑אל‑קצה לשידור תמונות מאובטח דרך הצפנה משולבת וסטגוןוגרפיה
מדוע חשוב להחביא תמונות בתוך תמונות
כל יום, בתי חולים, בנקים ואנשים פרטיים שולחים כמות עצומה של תמונות באינטרנט — מסריקות רפואיות דרך תעודות זהות ועד תמונות משפחתיות. שמירה על פרטיות התמונות האלה בדרך כלל משמעותה לערבל אותן בהצפנה, מה שגורם להן להראות כ'רעש' אקראי, או להחביא אותן בתוך תמונה אחרת, טריק שנקרא סטגנוגרפיה. לכל גישה יש חולשה: תמונות מוצפנות מושכות תשומת לב, ותמונות מוחבאות עלולות להיחשף על‑ידי ניתוח מתוחכם. מאמר זה מציג מערכת למידה עמוקה חדשה שמשלבת בין שתי הרעיונות, במטרה לשלוח תמונות סודיות שנראות טבעיות לעין האנושית ועדיין קשות לפיצוח עבור תוקפים.
הבעיה בשיטות ההגנה הנוכחיות
כלי הצפנה מסורתיים כמו AES ו‑DES חזקים מתמטית, אך הם הופכים תמונה לחסימת רעש חזותי שמודיעה במפורש "כאן מסתתר משהו חשוב". הסטגנוגרפיה הקלאסית עושה את ההפך: היא טומנת מידע בפרטים העדינים של תמונה שנראית רגילה, אך לעיתים ללא הגנה קריפטוגרפית חזקה. אם תוקף יזהה את הטריק, ההודעה המוחבאת עשויה להיות קלה לשליפה. שיטות חדשות מבוססות־למידה עמוקה שיפרו או את ההצפנה או את ההחבאה, אך רובן מתייחסות אליהן כשתי שלבים נפרדים. ההפרדה הזו מבזה משאבי חישוב ועלולה לאפשר לשגיאות משלב אחד לפגוע בשלב השני. המחברים טוענים שחסר מערכת יחידה שמתחנכת מקצה‑אל‑קצה כיצד להסתיר ולהגן על תמונות בו‑זמנית.
"מוח" יחיד שמערבל ומסתיר
החוקרים מתכננים רשת עצבית קונבולוציונלית מקצה‑אל‑קצה — במובן זה צינור עיבוד תמונה שניתן לאמן — שמקבלת שתי תמונות: תמונת "כיסוי" רגילה ותמונה "סודית" שיש להגן עליה. תחילה, מודול מיוחד שנקרא KeyMixer הופך את התמונה הסודית באמצעות מפתחות מספריים הניתנים לאימון. שלא כמו צפנים קבועים ומתוכננים ידנית, ה‑KeyMixer לומד שינויים התלויים בתוכן — בטקסטורות ובצורות שבתמונה — ומייצר מעוותים עדינים ולא בולטים. לאחר מכן, רשת Encoder משלבת בעדינות את הסוד המומר לתוך תמונת הכיסוי, ויוצרת "מיכל" שתמונה זו עדיין אמורה להיראות טבעית. בצד המקבל, רשת Decoder מתאימה לוקחת רק את תמונת המיכל ומשחזרת את הסוד המוחבא, בלי צורך במפתחות נוספים או במידע צדדי בזמן השחזור.
ללמד את הרשת לאזן בין סודיות למראה
אימון המערכת דורש להשיג שתי מטרות במקביל: לשמור על מראה המיכל קרוב חזותית לכיסוי המקורי, ולשחזר את התמונה הסודית בדיוק מירבי. המחברים עושים זאת באמצעות אסטרטגיית פונקציית אובדן כפולה שמענישה הן שינויים בולטים בכיסוי והן שגיאות בשחזור הסוד. הם משתמשים בערכת תמונות טבעיות מקובלת כתקן, מאגר STL‑10, ומיישמים טריקים סטנדרטיים של הרחבת נתונים כגון החלפות והטלות קטנות כדי שהרשת תראה סצנות מגוונות. במהלך האימון, המודל משתפר בהדרגה עד ששתי המטרות מתייצבות, מה שמראה שהוא מסוגל למצוא פשרה מעשית בין חוסר הראות לשחזור נאמן.
עד כמה התמונות המוחבאות שורדות
כדי להעריך איכות, הצוות מודד עד כמה תמונות המיכל דומות לכיסויים, ועד כמה הסודות המשוחזרים תואמים למקור, באמצעות מדדי איכות תמונה מקובלים. על תמונות המבחן, השיטה משיגה דמיון מבני גבוה הן לכיסוי והן לסוד, עם ערכים מעל 0.90, כלומר שהצורות והפרטים נשמרים ברובם. התמונות הסודיות במיוחד מגיעות לדמיון גבוה מאוד, מה שמעיד על שחזור תפיסתי כמעט מושלם. בהשוואה לכמה מערכות סטגנוגרפיה מודרניות מבוססות למידה עמוקה וצינורות היברידיים, המודל המקצה‑אל‑קצה החדש מספק את השחזור הטוב ביותר של תמונת הסוד, גם אם חלק מהמתחרים משמרים במעט טוב יותר את הכיסוי. בדיקות סטטיסטיות של התפלגויות פיקסלים, אקראיות ורגישות לשינויים מרמזות שהתמכנים אינם חושפים רמזים בולטים לכך שמשהו מוחבא.
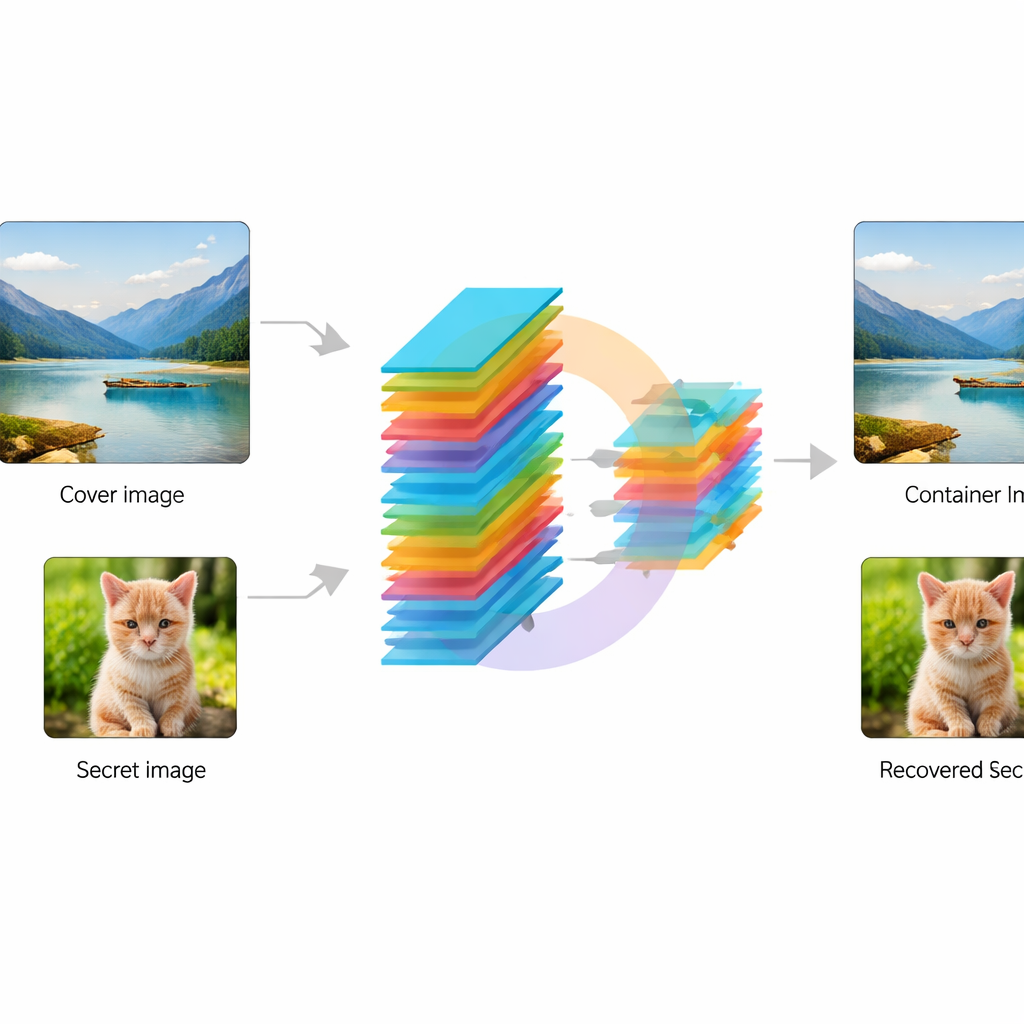
מה זה עשוי להעיד לגבי פרטיות יומיומית
במילים פשוטות, עבודה זו מראה שמודל למידה עמוקה יחיד יכול ללמוד גם להסתיר וגם להגן על תמונות כך שניתן לשחזר תמונה מוחבאת בבהירות גבוהה, בעוד שהתמונה המשותפת עדיין נראית רגילה. במקום לחבר הצפנה וסטגנוגרפיה בשרשור מגושם, המערכת לומדת פשרה חלקה בין עדינות חזותית ובין אבטחה. אף על פי שהיא כרגע דורשת חומרה חזקה ובדיקות נוספות נגד מתקפות מתקדמות, הגישה מצביעה על כלים עתידיים שיכולים לאבטח בשקט סריקות רפואיות, תמונות אישיות או תמונות רגישות אחרות בתקשורת שגרתית באינטרנט, מבלי להודיע שמשהו סודי קיים כלל.
ציטוט: Iqbal, A., Sattar, H., Shafi, U.F. et al. An end-to-end convolutional neural network for secure image transmission via joint encryption and steganography. Sci Rep 16, 8228 (2026). https://doi.org/10.1038/s41598-026-39351-4
מילות מפתח: אבטחת תמונות, סטגנוגרפיה, למידה עמוקה, הצפנה עצבית, הגנת פרטיות