Clear Sky Science · he
חיזוי ממוסך בטופולוגיית תנועה של שלד ולמידת ניגודיות לזיהוי פעולות אנושיות בלמידה ללא השגחה
להורות למחשבים לקרוא שפת גוף
מצלמות דלת חכמות ועד כלי שיקום חכמים — מערכות מודרניות רבות צריכות להבין מה אנשים עושים רק על ידי צפייה בתנועותיהם. אבל אימון מחשבים לזהות פעולות אנושיות בדרך כלל דורש מערכי נתונים עצומים ומסומנים בזהירות, שבהם כל מחווה, בעיטה או לחיצת יד מתויגים ביד. המחקר הזה מציע דרך שבה מכונות לומדות מתוך נתוני תנועה גולמיים בלבד, באמצעות שלד הגוף הנע — ללא תוויות, ללא פרצופים וללא וידאו בצבע מלא — מה שעושה את זיהוי הפעולות מדויק יותר, פרטי יותר ופחות תלוי בתיעוד יקר שנעשה בידי אדם.
מדוע שלדים מספיקים
במקום לנתח פריימים של וידאו מלאים, השיטה פועלת עם נתוני שלד תלת-ממדיים: הקואורדינטות של מפרקים מרכזיים כמו כתפיים, מרפקים, ירכיים וברכיים לאורך זמן. מבט חיסרוני זה של הגוף מציע מספר יתרונות. הוא עוקף במידה רבה סוגיות פרטיות כי פרצופים ובגדים מוסרים, והוא קומפקטי מספיק לעיבוד יעיל גם בהקלטות ארוכות. שלדים גם חסינים לריבוי רעשים ברקע ושינויים בתאורה שמבלבלים מערכות מבוססות וידאו רגילות. עם זאת, רוב הגישות הקיימות המבוססות על שלדים עדיין תלויות במידה רבה בדוגמאות מתוייגות ומתקשות לתפוס במלואן כיצד המפרקים נעים ביחד בפעולות מסובכות ומתואמות.
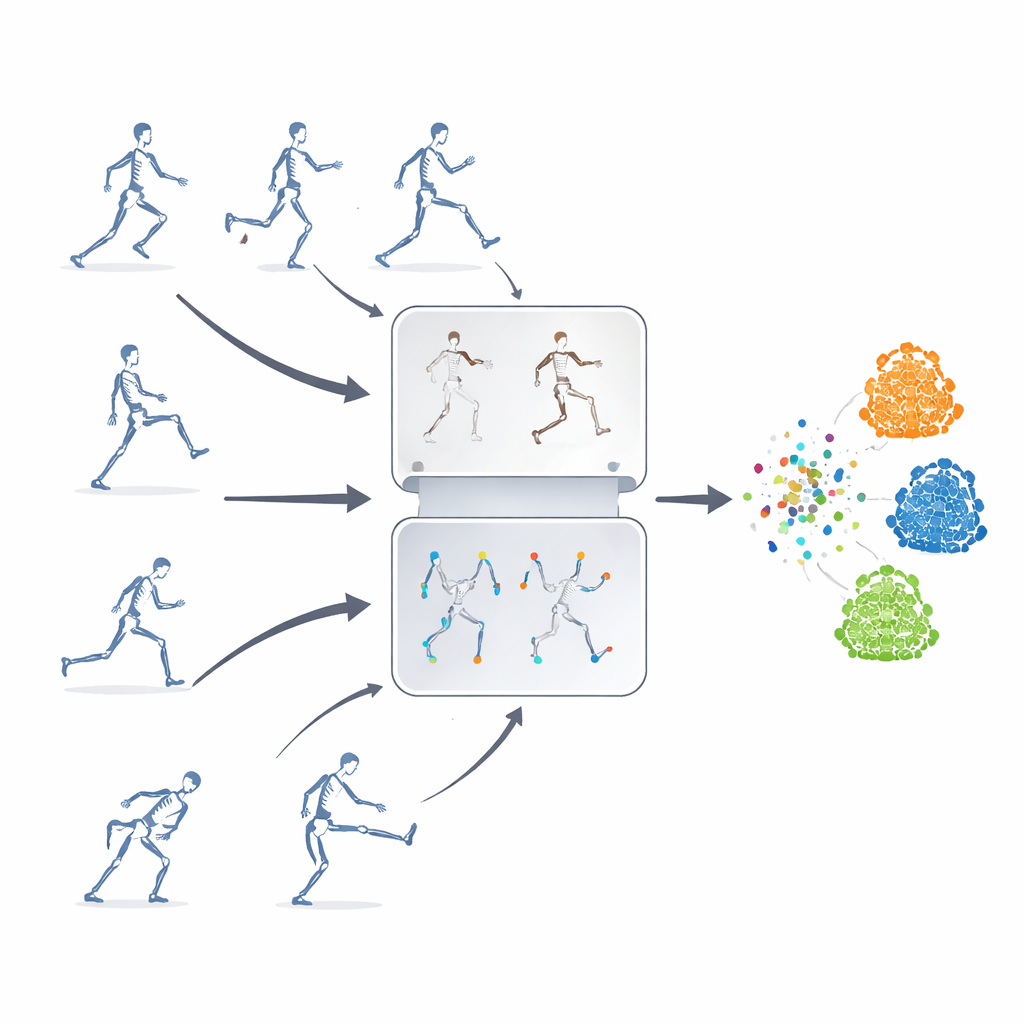
לימוד בלי תוויות
המחברים מציעים מסגרת למידה ללא השגחה, כלומר המערכת מלמדת את עצמה מתוך רצפי שלד ללא תיוג. הרעיון המרכזי שלהם הוא לשלב שתי אסטרטגיות חזקות שבדרך כלל משמשות בנפרד. האחת היא "חיזוי במצב מוסך" (masked prediction), שבה חלק מנתוני השלד מוסתרים בכוונה כך שהמודל חייב לנחש את התנועה החסרה מן ההקשר הנותר. השניה היא "למידת ניגודיות" (contrastive learning), שבה מציגים למודל מספר גרסאות משונוֹת של אותה פעולה ומאמנים אותו לזהות שגרסאות אלה מייצגות את אותה תנועה בסיסית. על ידי שילוב שיטות אלה, המערכת לומדת גם פרטים עדינים של תנועת המפרקים וגם את המשמעות הרחבה של הפעולה.
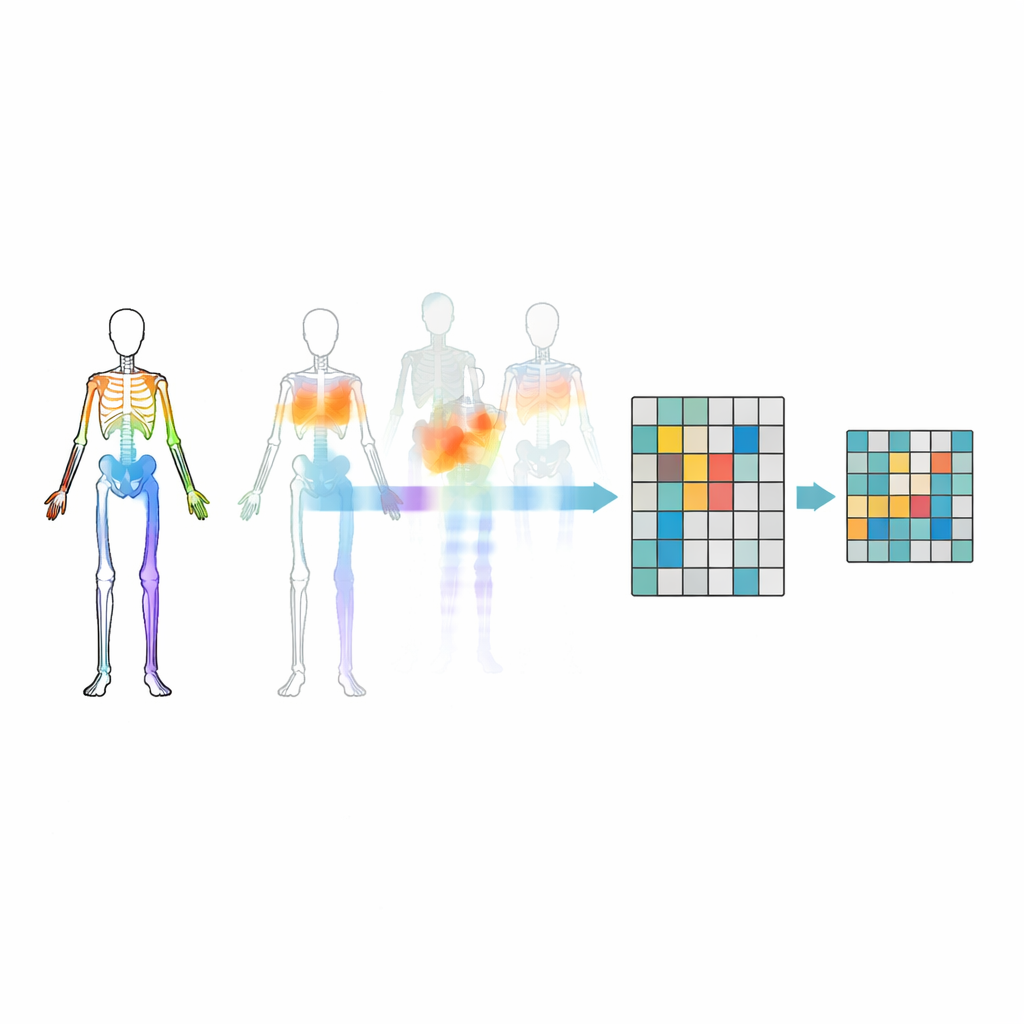
להסתיר את המפרקים הנכונים
סתם להסתיר מפרקים אקראיים לא מספיק — המודל עלול להתעלם מקשרים חשובים בין חלקי הגוף או להתמקד בתנועה הברורה ביותר. כדי למנוע זאת, החוקרים מציגים אסטרטגיית הסתרה המבוססת על טופולוגיית התנועה. הם מקבצים מפרקים לאזורים משמעותיים בגוף כגון זרועות, רגליים וגזע, ואז מודדים עד כמה כל אזור נע לאורך זמן. החלטות ההסתרה מונחות הן על ידי המבנה של הגוף והן על ידי עוצמת התנועה בכל אזור, כך שלפעמים חלקים פעילים מאוד מוסתרים והמודל נאלץ להסיק אותם מן שאר הגוף. הסתרה מכוונת זו מסייעת למערכת ללמוד כיצד המפרקים משתפים פעולה במהלך פעולות, במקום רק לזכור כמה תנועות בוהקות.
להאריך פעולות בדרכים רבות
כדי לאמן את החלק של הלמידה הניגודית, אותו רצף שלד מקורי מומר ל"מבטי" שפע שונים. חלק מהשינויים עדינים, כגון חיתוך חלון הזמן או עיוות קל של המסלול, בעוד שאחרים קיצוניים יותר, כולל היפוכים, סיבובים ורעש חזק יותר. רמות ההגברה המרובות הללו חושפות את המודל למגוון עשיר של דפוסי תנועה ומעודדות אותו להתמקד במבנה הליבה של פעולה במקום בפרטים שטחיים. במקביל, מודול שמוביל לירידת תכונות מודרכת במסלולים עוקב אחר אילו תכונות תנועה המודל סומך עליהן ביותר ומדכא אותן בכוונה במהלך האימון. על ידי הסרה זמנית של הרמזים המועדפים שלו, המערכת נדחפת למצוא רמזי גיבוי וללמוד ייצוגים כלליים ומעבירים יותר.
כמה טוב זה עובד?
המסגרת נבדקה בשלושה מערכי מבחן ציבוריים גדולים של פעולות אנושיות תלת-ממדיות, המכסים התנהגויות יומיומיות, תנועות הקשורות לרפואה ואינטראקציות בין אנשים. למרות שהיא משתמשת רק בנתוני מפרקי שלד וברשת עצבית חוזרת יחסית קלת משקל, השיטה משווה או עולה על רבות מהמערכות המתקדמות שמשתמשות בקלטים או ארכיטקטורות מורכבות יותר. היא חזקה במיוחד כשתיוגים נדירים או כשחלקי גוף מכוסים — מצבים הנפוצים בעולם האמיתי. אף על פי שהיכולת שלה להעביר ידע בין מערכי נתונים שונים מאוד עדיין יכולה להשתפר, הגישה מצמצמת משמעותית את הפער בין אימון מתוייג ללא מתוייג לזיהוי פעולות.
מה זה אומר למערכות בעולם האמיתי
ללא-מומחה, המסקנה היא שעבודה זו מראה כיצד מחשבים יכולים להשתפר משמעותית בקריאת שפת גוף אנושית ללא הדרכה מפורשת על משמעות כל תנועה. על ידי הסתרה וחיתוך חכם של נתוני שלד במהלך האימון, המודל לומד דפוסי תנועה חסינים שמחזיקים מעמד בתנאי תאורה גרועים, רעש חזותי או מפרקים חסרים, ועושה זאת עם הרבה פחות תוויות שמספקים בני אדם. זה פותח פתח למערכות זיהוי פעולות פרטיות, מדרגיות ומתאימות יותר לשימושים החל ממוניטורינג ביתי ואימון ספורט ועד שיקום רפואי ואינטראקציה בין אדם-רובוט.
ציטוט: Hui, Y., Li, F., Hu, X. et al. Skeleton motion topology-masked prediction and contrastive learning for self-supervised human action recognition. Sci Rep 16, 8100 (2026). https://doi.org/10.1038/s41598-026-39330-9
מילות מפתח: זיהוי פעולות אנושיות, נתוני שלד תלת-ממדיים, למידה ללא השגחה, למידת ניגודיות, ניתוח תנועה