Clear Sky Science · he
מסגרת סיאמית CNN-RNN עם אגgregציה ברב-רמות לזיהוי אנשים מבוסס וידאו
מדוע מעקב אחר אנשים בין מצלמות חשוב
ערים מודרניות מכוסות במצלמות, אך המצלמות האלה לעתים רחוקות "מדברות" זו עם זו. כאשר אדם עובר מפינה לרכבת, מצלמות שונות תופסות אותו מזוויות חדשות, בתאורה שונה ולעתים דרך קהל. זיהוי אוטומטי שמדובר באותו אדם בקטעים שונים של וידאו — תהליך הנקרא זיהוי אנשים מבוסס וידאו — יכול לעזור לחקירות אחרי אירוע, לתמוך בחיפושים אחר נעדרים או לספק אנליטיקה במוקדים ציבוריים עמוסים. אבל לבצע זאת בדיוק וביעילות, במיוחד על חומרה צנועה, היא אתגר טכני משמעותי.
מוח פשוט יותר להתאמת אנשים בתנועה
מחקר זה מציג מערכת בינה מלאכותית קומפקטית המיועדת לקבוע האם שני קטעי וידאו קצרים מציגים את אותו אדם. במקום להשתמש במגמות של היום של רשתות עמוקות מאוד או רשתות מבוססות טרנספורמר, המחברים בונים על עיצוב חסכוני המשלב שני מרכיבים קלאסיים: רשת קונבולוציה שמנתחת כל פריים, ויחידת זיכרון ממושכת סגורה (GRU) שעוקבת אחר שינויים במראה לאורך זמן. שני הענפים הללו מסודרים בפריסת סיאמית — בעצם עותקים תאומים של אותה רשת שמשתפים את כל הפרמטרים הפנימיים. כל תואם מעבד רצף וידאו אחד, והמטרה היא שלמערכת יהיו חתימות פנימיות דומות עבור קטעים של אותו אדם וחתימות שונות עבור אנשים שונים.
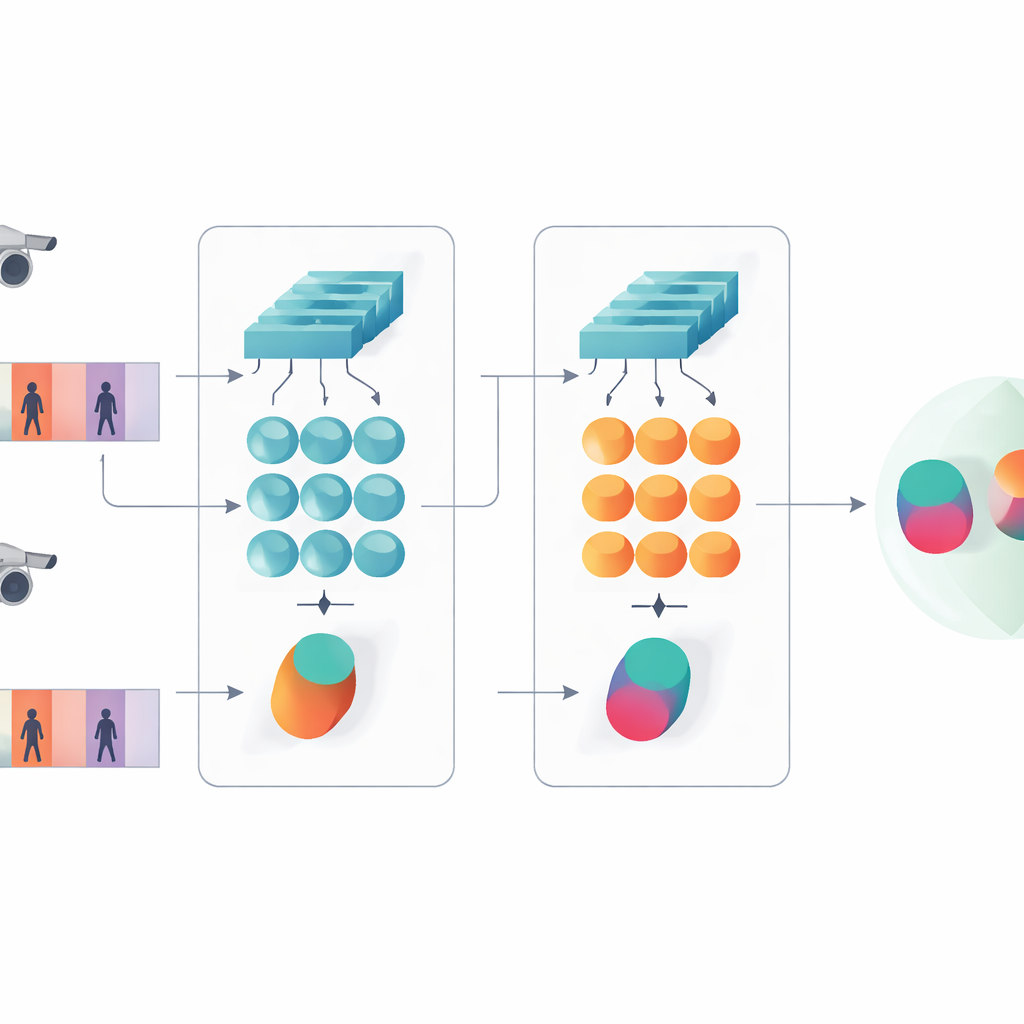
לראות גם פרטים וגם דפוסים לאורך זמן
רעיון מרכזי בעבודה הוא שהזיהוי לא צריך להישען רק על התכונות העמוקות וההפשטתיות ביותר של הרשת. השכבות המוקדמות עדיין מכילות פרטים חזותיים חדים כמו אריג של מעיל, פסים על מכנסיים או קווי מתאר של תיק גב — רמזים שעמידים לעתים קרובות לשינויי זווית מצלמה. המודל המוצע שומר לכן שתי רמות תיאור. ענף אחד מבצע פולי של התכונות משכבות מוקדמות על פני כל הפריימים כדי לתמצת מרקמים עדינים ודפוסים מקומיים. הענף השני מזין תכונות מאוחרות יותר ל-GRU, שמעקבת אחרי הרצף פריים אחר פריים ואז ממצעת את המצבים הפנימיים שלה על פני הזמן. שלב הממוצע הזה מונע הדגשה מופרזת של הפריימים האחרונים ולוכד במקום זאת תמונת קונצנזוס של איך האדם נראה ונע לאורך כל הקטע.
לאמן את הרשתות התאומות להסכים ולסווג
כדי ללמד את המערכת מה חשוב, המחברים משלבים שתי מטרות אימון. ראשית, אובייקטיב אימות מעודד את ענפי התאומים לייצר חתימות קרובות עבור סרטונים של אותו אדם וחתימות רחוקות עבור אנשים שונים. שנית, אובייקטיב סיווג מבקש מהרשת לשייך כל קטע אימון לזהות מסוימת. על ידי אופטימיזציה של שניהם בו-זמנית, וביצוע זה ברמות תכונה נמוכות וגבוהות, המודל לומד תיאורים פנימיים שהן מובחנות בין אנשים והן חסינות לרעש, להסתתרויות ולקטעים באיכות ירודה מדי פעם. העיצוב נשאר רדוד במונחי שכבות ופרמטרים, מה שעוזר להמנע מהתאמת יתר על מערכי וידאו יחסית קטנים.
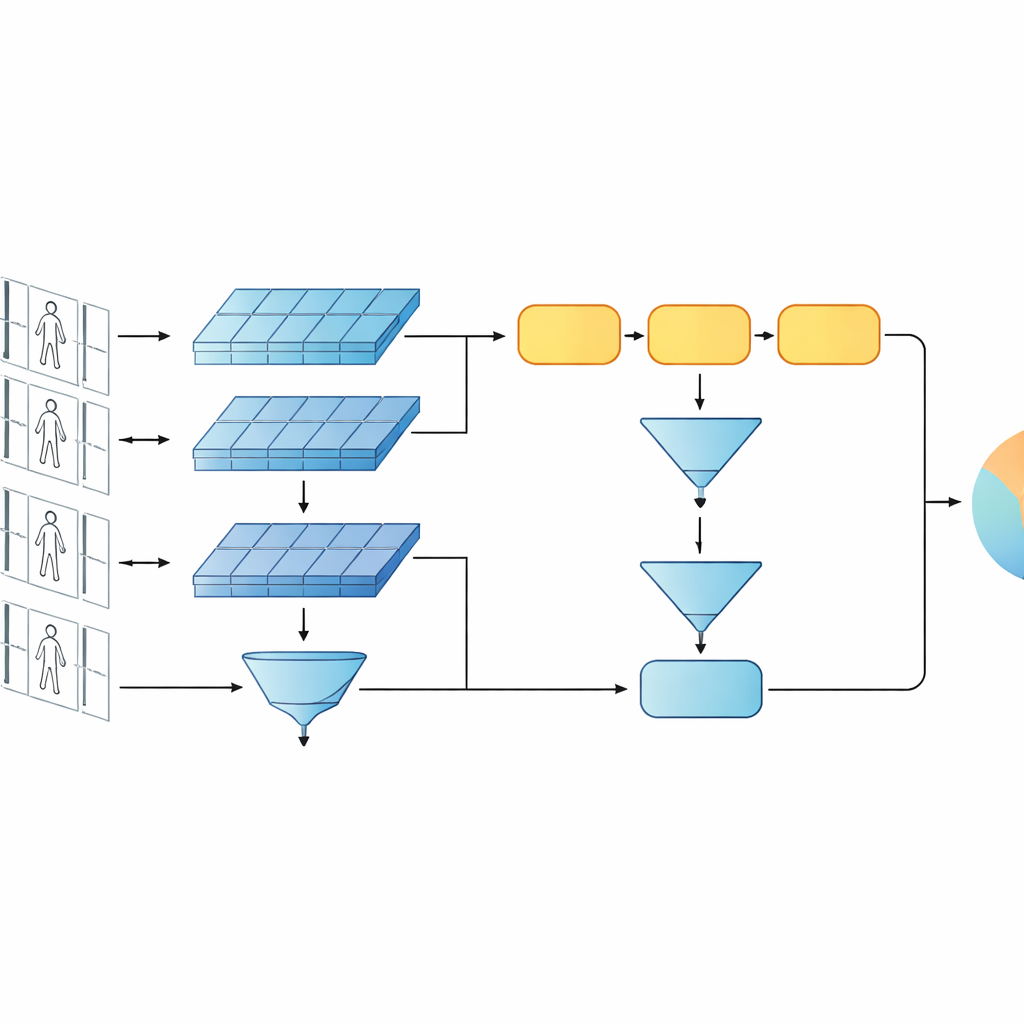
בדיקה על קטעי וידאו בסגנון מעקב אמיתי
המסגרת הוערכה על שני מאגרי וידאו נפוצים, PRID-2011 ו-iLIDS-VID, הכוללים רצפים קצרים של הליכה של מאות אנשים שצולמו מזוגות מצלמות בלתי חופפות. המחקר בוחן בקפידה בחירות עיצוב שונות: החלפת ה-GRU ביחידות חוזרות אחרות, שינוי מספר שכבות החוזרות, שינוי שיטות הפולי על פני הזמן, וכיבוי או הדלקת ענפים ברמת תכונה נמוכה או גבוהה. בבדיקות אלה, GRU חד-שכבתי עם פולי ממוצע והארכיטקטורה הרב-רמתית המלאה מספקים בעקביות את הדיוק הטוב ביותר. המודל משווה או עולה על ביצועי מערכות סיאמיות וחוזרות רבות ומוצג בתחרות גם עם עיצובים מבוססי קשב, תוך שימוש בהרבה פחות פרמטרים וחישוב.
יעילות לפריסות מעשיות
מעבר לדיוק, העבודה מדגישה מעשיות. כל הרשת מכילה רק כ-1 עד 2 מיליון פרמטרים ניתנים לאימון — סדרי גודל פחותים מרכבי עבות עמוקים נפוצים או טרנספורמרים — ודורשת חלק קטן מעלות החישוב שלהן לכל פריים. הדבר הופך אותה מתאימה יותר לפריסה על התקנים עם זיכרון ועיבוד מוגבלים, כגון שרתי קצה בקרבת מצלמות. ניסויים מראים גם שרצפי גלריה ארוכים יותר, שבהם המערכת רואה יותר פריימים של כל אדם מאוחסן, משפרים משמעותית את הזיהוי, אם כי עם עלייה ליניארית בעלות העיבוד. המחברים טוענים כי ארכיטקטורות קומפקטיות ומתוכננות בקפידה כאלה יכולות לספק זיהוי אנשים מהימן ללא תג המחיר הכבד של הדגמים הגדולים ביותר של היום.
מה המשמעות הזו למערכות מעקב יומיומיות
פשוטו כמשמעו, המאמר מדגים שעיצוב חכם יכול לגבור על גודל קיצוני: על ידי שילוב ניתוח תמונה רדוד, מודל רצף קל-משקל ותצפית דו-רמתית של דמיון חזותי, ניתן לעקוב מי הוא מי בין מצלמות באמינות גבוהה תוך שמירה על מודל קטן ומהיר. עבור מערכות עתידיות שצריכות לפעול על רבות מצלמות, לעתים עם תקציבי חומרה ואנרגיה צפופים, גישה יעילה ורב-רמתית כזו יכולה לסייע להביא אנליטיקה וידאו מתקדמת ואחראית לשימוש בעולם האמיתי.
ציטוט: Wang, YK., Pan, TM. & Sun, CP. A CNN-RNN Siamese framework with multi-level aggregation for video-based person re-identification. Sci Rep 16, 8224 (2026). https://doi.org/10.1038/s41598-026-39277-x
מילות מפתח: זיהוי מחדש של אנשים, שירותי מעקב בווידאו, רשתות עצביות סיאמיות, מודליזציה זמנית, למידה עמוקה יעילה