Clear Sky Science · he
מסגרת יציבה להמרת טקסט לשאילתות SQL בשפה טבעית עם אסטרטגיות דינמיות מבוססות מודלי שפה גדולים
הפיכת שאלות יומיומיות לתשובות מבסיס נתונים
ארגונים מודרניים מצויים בעומס של נתונים, אך רוב האנשים אינם דוברים את השפה הטכנית הנדרשת לשאול אותה. מאמר זה מציג את TriSQL, מערכת שמאפשרת למשתמשים לשאול שאלות בשפה פשוטה ולהפוך אותן באופן אוטומטי לפקודות מדויקות למסדי נתונים. על ידי ניהול קפדני של האופן שבו מודלים גדולים של שפה מתמודדים עם מורכבות, המסגרת שואפת להפוך את הגישה לנתונים ליותר מדויקת ומהימנה, גם עבור השאלות הקשות ביותר.
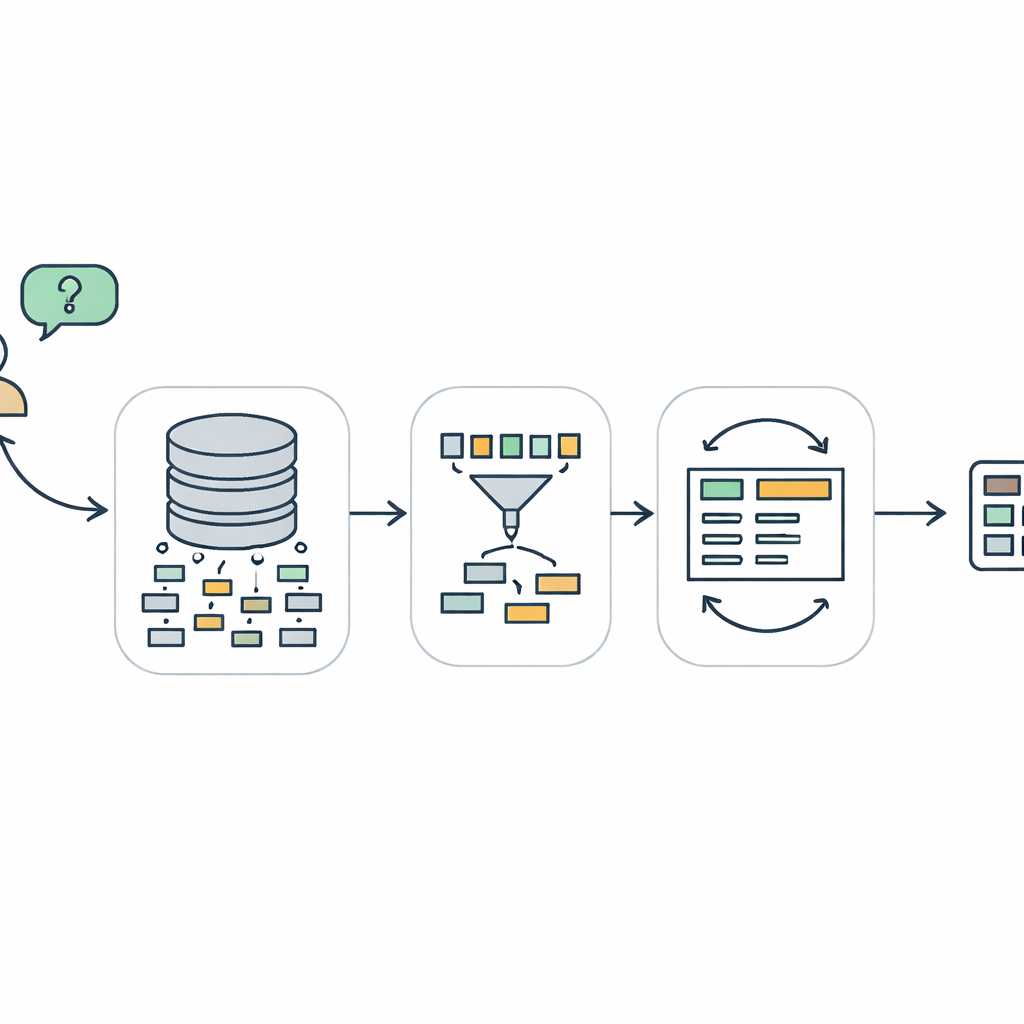
למה דיבור עם מסדי נתונים כל כך קשה
כאשר מישהו מקליד שאלה כמו «אילו לקוחות קנו יותר מחמש מוצרים בחודש שעבר?», המחשב צריך לתרגם זאת ל-SQL, השפה המיוחדת שבה משתמשים רוב מסדי הנתונים. המשימה הזו, שנקראת text-to-SQL, נשמעת פשוטה אך היא מפתיעה במורכבותה. המערכת חייבת להבין מה המשתמש רוצה, למצוא את הטבלאות והעמודות הרלוונטיות בתוך מסד נתונים שלעיתים גדול ומבולגן, ואז לבנות שאילתה שהיא גם תקנית מבחינה תחבירית וגם נאמנה לכוונה המקורית. מערכות קודמות, כולל כאלו שמונעות על ידי מודלים גדולים של שפה, נוטות להיכשל כאשר השאלות מערבות טבלאות רבות, לוגיקה מקוננת או תנאים עדינים. הן עלולות לייצר שאילתות שנראות דומות לנכונות אך אינן ניתנות להרצה או מחזירות תוצאות שגויות בעת ביצוען.
נתיב בשלוש שלבים מהשאלה לשאילתה
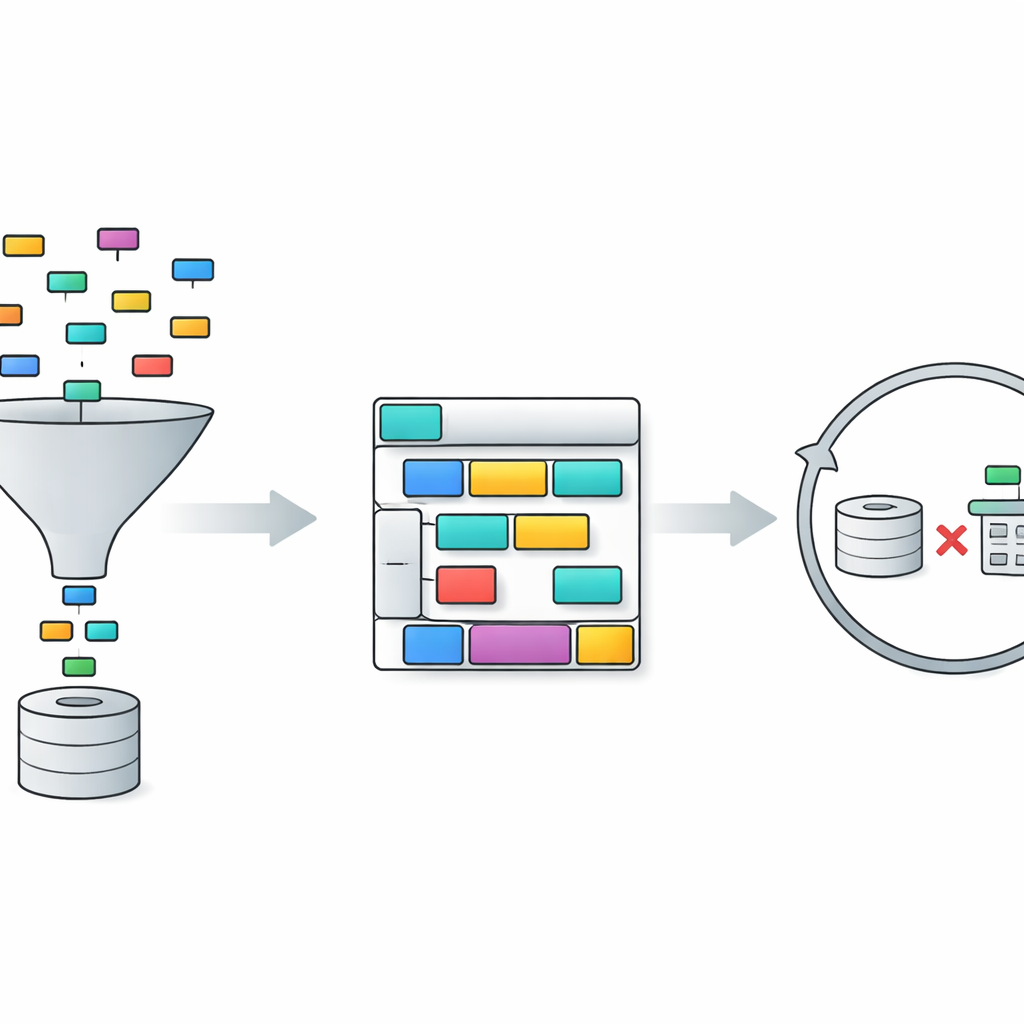
TriSQL מתמודדת עם הבעיות האלה באמצעות צינור עבודה בעל שלושה שלבים. ראשית, בורר מונחה-שאלה בודק את מילות המשתמש ואת מבנה מסד הנתונים המלא ומחליט אילו טבלאות ועמודות באמת רלוונטיות. במקום לחשוף את סכמת המסד כולה למודל השפה באופן עיוור, הוא מצמצם את התצוגה רק לחלקים שחשובים. שנית, מחולל בעל מודעות-למבנה מתכנן את צורת שאילתת ה-SQL לפני מילוי הפרטים. הוא תחילה מסמן שלד ברמה גבוהה—אילו סקלוזים נדרשים וכיצד הם משתלבים—ואז מכניס טבלאות ספציפיות, חיבורים ותנאים. הגישה הזו של "מבנה קודם, תוכן לאחר מכן" מסייעת לשמור על הדקדוק הנוקשה של SQL, במיוחד עבור שאילתות ארוכות ומסועפות. לבסוף, משפר המודע למורכבות בודק ומשפר את השאילתה ההתחלתית, תוך שימוש באסטרטגיות שונות בהתאם לקושי הנתפס של השאלה.
התאמת המאמץ לקושי השאלה
שלב השיפור הוא המקום שבו TriSQL עושה שימוש חדשני במיוחד במודלים גדולים של שפה. המערכת מדרגת עד כמה כל שאלה וטיוטת שאילתה מורכבים, תוך שקלול גורמים כגון מספר הטבלאות שמצורפות, עומק ההגדרה המקוננת וסוגי המגבלות המשמשות. במקרים פשוטים היא מבצעת רק תיקונים קלים, כגון תיקון שגיאות תחביר קטנות. במקרים בינוניים היא מארגנת מחדש סעיפים ומוודאת שהשאילתה תואמת את הסכמה שנבחרה. במקרים התובעניים ביותר היא מפעילה את מודל השפה להיגיון מעמיק יותר, לעתים מפרקת את הבעיה לתת-משימות ומריצה שאילתות אלטרנטיביות. באופן קריטי, TriSQL מריצה הן את השאילתה המקורית והן את זו המשופרת נגד מסד הנתונים ומשתמשת בהתנהגותן—האם הן רצות, כמה זמן לוקח להן ומה הן מחזירות—כדי להחליט איזו גירסה לשמור או האם לנסות סבב שיפור נוסף.
בחינת המערכת במבחן
כדי לבדוק עד כמה TriSQL טובה, המחברים בוחנים אותה על אבן-יסוד מקובלת בשם Spider, יחד עם כמה וריאנטים קשים יותר שמכניסים ידע תחומי, תבניות משפטיות בלתי שגרתיות ומבני שאילתות ריאליסטיים יותר. הם מודדים שני דברים: "התאמה מדויקת" (exact match), שבודקת האם מחרוזת ה-SQL שנוצרה זהה לנוסח ייחוס שכתב אדם, ו"דיוק ביצוע" (execution accuracy), שבודק האם היא אכן מייצרת את התשובה הנכונה בזמן הריצה. על פני מערכי המבחן הללו, TriSQL משיגה את דיוק הביצוע הגבוה ביותר שדווח עד כה תוך שמירה על התאמה מדויקת ברמה תחרותית עם המערכות הטובות ביותר הקודמות. היא גם חסונה יותר: כאשר השאלות נעשות מקלות לקשות במיוחד, הביצועים של TriSQL נופלים בהרבה מתון יותר מאשר של שיטות מתחרות. ניסויים נוספים על מערך נתונים מעולם ניהול רשת חשמל אמיתית מראים שהמסגרת יכולה לטפל לא רק בשליפת נתונים, אלא גם בפקודות הוספה, עדכון, מחיקה ויצירת טבלאות. התאמות ראשוניות למסדי נתונים גרפים (Cypher) ולצינורות MongoDB מרמזות כי העיצוב התלת-שלבי יכול להתרחב מעבר ל-SQL הקלאסי.
מה זה אומר לשימוש יומיומי בנתונים
פשוטו כמשמעו, עבודה זו מקרבת אותנו לעולם שבו אנשים יכולים לשוחח עם מסדי נתונים מורכבים בקלות כזו שבה הם משוחחים כיום עם מנועי חיפוש. על ידי בחירה מדויקת של החלקים במסד הנתונים שיש להתחשב בהם, על ידי תכנון מבנה השאילתה לפני מילוי הפרטים, ועל ידי התאמת השימוש במודלים גדולים של שפה לפי קושי כל שאלה, TriSQL מייצרת שאילתות שסביר יותר שירוצו כהלכה ויחזירו את התוצאות המיועדות. אמנם עדיין נותרו אתגרים—כמו טיפול בשאלות עמומות ובמסדי נתונים בלתי מוכרים—המחקר מראה שעיצוב מתוכנן ומודולרי יכול להפוך ממשקי שפה טבעית לנתונים לעוצמתיים וניתנים לחיזוי יותר עבור משתמשים יומיומיים.
ציטוט: Su, X., Gu, Y., Wang, P. et al. A robust natural language text-to-SQL generation framework with dynamic strategies based on LLMs. Sci Rep 16, 7892 (2026). https://doi.org/10.1038/s41598-026-39128-9
מילות מפתח: text-to-SQL, ממשקים בשפה טבעית, שאילתות למסדי נתונים, מודלים גדולים של שפה, חוסן שאילתות