Clear Sky Science · he
שיטה לטיפול בנתונים לא מאוזנים באמצעות הזזת גבול
מדוע מקרים נדירים חשובים בנתונים היומיומיים
מפשיעת הונאות בבנקים ואבחון רפואי ועד חיזוי נטישת לקוחות — הרבה מההחלטות שאנו מבקשים ממחשבים לקבל תלויות בזיהוי אירועים נדירים אך קריטיים. ברוב מערכי הנתונים האמיתיים, המקרים החשובים הללו מועטים בהרבה בהשוואה למקרים השגרתיים. מודל שרואה בעיקר "עסקים כרגיל" עלול להיות עיוור למצבים שאותם אנו רוצים לזהות ביותר. המאמר מציג דרך חדשה לאזן מחדש נתונים מוטים כאלה, כך שאלגוריתמים ילמדו לתת תשומת לב ראויה למקרים הנדירים ובעלי ההשפעה הגדולה.
המכשול החבוי של נתונים לא מאוזנים
כאשר סוג אחד של דוגמאות עולה בהרבה על סוג אחר, שיטות למידת מכונה סטנדרטיות נוטות להתמקד ברוב ולהזניח את המיעוט. מערכת לחיזוי נטישה, למשל, עלולה לסווג כמעט את כולם כלקוחות נאמנים ועדיין להציג דיוק גבוה, פשוט מפני שמספר הנטישים בפועל קטן מאוד. בעיות דומות מופיעות בזיהוי תאונות, ניטור הונאות וסינון רפואי, שבהן מקרים חיוביים נדירים אך יקרי ערך להחמיץ. דרכים מסורתיות לתיקון הבעיה נחלקות לשני כיוונים: להתאים את אלגוריתם הלמידה כך ש"ידאג" יותר למיעוט, או לעצב מחדש את הנתונים עצמם על‑ידי הסרת חלק ממקרי הרוב (undersampling) או יצירת דוגמאות מיעוט נוספות (oversampling). כלים פופולריים של הגדלת דגימות כמו SMOTE מייצרים דוגמאות סינתטיות של המיעוט, אך הם עלולים, ללא כוונה, להציף את אזור הגבול העדין שבו הכיתות נפגשות.
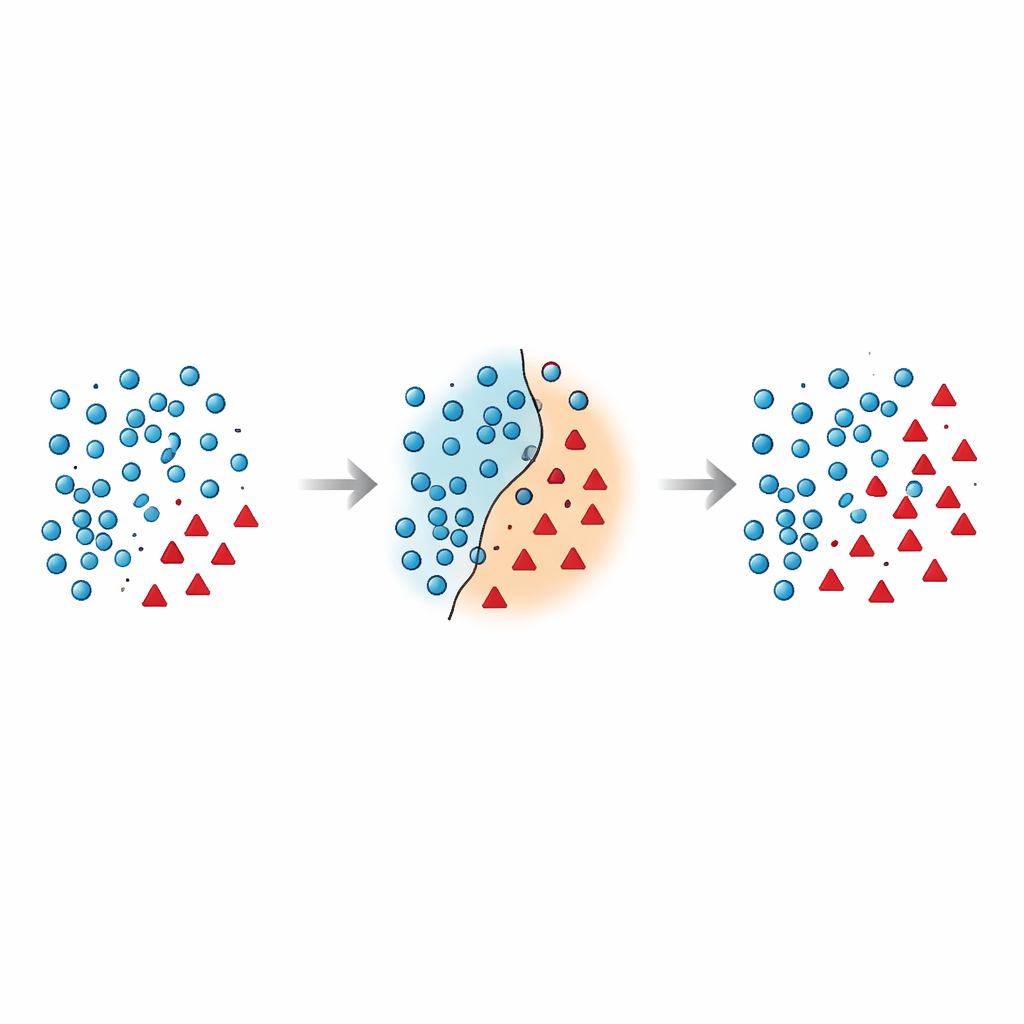
מדוע הגבול בין הקבוצות כה שביר
המחברים טוענים שהטעויות המסוכנות ביותר קורות בקרבת גבול ההחלטה — האזור שבו דוגמאות הרוב והמיעוט חופפות במרחב התכונות. טכניקות רבות קיימות מוסיפות נקודות סינתטיות באזור המסוכן הזה מבלי לנקות אותו, או מוחקות נתונים באופן אגרסיבי ובכך מסירות בטעות דוגמאות אינפורמטיביות. מחקרים אחרונים ניסו להתמודד עם הבעיה באמצעות מגבלות גיאומטריות, הערכות צפיפות מקומיות או מסנני רעש, אך רוב השיטות עדיין מטפלות בנקודות המיעוט במקום ואינן שוקלות מחדש כיצד יש לטפל בנקודות הרוב הסמוכות לגבול. זה מותיר בעיה מתמשכת: דגימות חופפות ורועשות שמבלבלות את הממיין ומובילות לחיזויים לא יציבים, במיוחד על נתונים חדשים.
דרך דו‑שלבית לסדר את הגבול
המאמר מציג Borderline Shifting Oversampling (BSO), שיטת עיצוב נתונים בשתי פאזות שמכוונת במפורש לאזור הגבול הבעייתי. תחילה, השיטה סורקת את השכונה של כל דוגמת רוב כדי להחליט האם היא נמצאת באזור בטוח, על הגבול, או במקום שנראה כנוטה לטעות (רעש). נקודות רוב המוקפות בשכני מיעוט או שיוחסו למיעוט או שסומנו כרעש והוסרו — מה שמנקה ומזיז את הגבול כך שישקף טוב יותר את הדפוס היסודי. בשלב השני השיטה מייצרת נקודות מיעוט סינתטיות באמצעות אינטרפולציה בסגנון SMOTE, אך רק סביב דוגמאות מיעוט הקרובות לגבול המתוקן. בכך שהיא מרוכזת ביצירת נתונים חדשים באזורים המועילים ביותר וממנעת הוספת נקודות ברורות ורועשות, BSO בונה סט אימון שגם מאוזן יותר בגודלו וגם נקי יותר במבנהו.
מבחן השיטה בשטח
כדי לבדוק עד כמה זה פועל בפועל, החוקרים העריכו את BSO על פני 30 מערכי נתונים בינוניים עם דרגות שונות של חוסר איזון וחפיפה. הם השוו אותה עם שבע חלופות נפוצות, כולל דגימה אקראית עודפת וחסרה (Random Over‑ and Under‑Sampling), SMOTE, Borderline‑SMOTE, NearMiss ושתי שיטות היברידיות המשלבות הגדלת דגימות עם ניקוי רעש (SMOTE‑Tomek ו‑SMOTE‑ENN). שלושה ממיינים נפוצים — Support Vector Machines, Naïve Bayes ו‑Random Forests — נותחו על כל סט נתונים שעבר דגימה מחדש. במקום להסתמך על דיוק גולמי, המחקר השתמש במדדים המעניקים תמונה עשירה יותר במצבי חוסר איזון, כגון מדד F1, G‑mean, זיהוי (recall), דיוק (precision) ושטח מתחת לעקומת ה‑ROC (AUC). כמעט בכל מערכי הנתונים והממיינים, BSO סיפקה ציונים גבוהים או שווים ובמקביל הראתה פחות שונות, כלומר יתרונותיה היו עקביים ולא תלויים במודל או בהגדרה מסוימת.
מה זה אומר עבור החלטות בעולם האמיתי
באופן יומיומי, גישת Borderline Shifting פועלת כמו עורך מדויק לנתונים מבולגנים: היא מנקה דוגמאות מבלבלות שממוקמות קרוב לקו ההפרדה בין הכיתות ואז מוסיפה בדיוק את כמות דוגמאות המיעוט הריאליסטיות במקומות הנכונים. התוצאה היא שאלגוריתמי הלמידה משתפרים בזיהוי אירועים נדירים אך חשובים מבלי להטעות על‑ידי חפיפות רועשות. ליישומים כמו זיהוי הונאות, חיזוי תאונות או טריאז' רפואי — שבהם החמצת מקרה מיעוט עלולה להיות יקרת תוצאה — שיטה זו מציעה דרך מעשית להפוך מודלים לצדקיים, רגישים ואמינים יותר, תוך הוספת עומס חישובי מינימלי יחסית.
ציטוט: Malhat, M.G., Elsobky, A.M., Keshk, A.E. et al. An approach for handling imbalanced datasets using borderline shifting. Sci Rep 16, 8264 (2026). https://doi.org/10.1038/s41598-026-39118-x
מילות מפתח: חוסר איזון בכיתות, הגדלת דגימות, גבול החלטה, זיהוי אנומליות, חוסן למידת מכונה