Clear Sky Science · he
שיטה ליצירת אובייקטים גאוגרפיים במפות תמונת לוויין המבוססת על נתוני מפת וקטור בעזרת למידה עמוקה
למה חשוב לשנות את מה שמראות המפות
מפות מקוונות מרגישות לעתים קרובות כמו חלונות לעולם האמיתי, אבל מה שאתם רואים ממעל מעוצב בקפידה. מפות תמונת לוויין מוערכות כי הן נראות כמקומות אמיתיים, ובכל זאת לעתים נדרשת הסתרת מתקנים רגישים, ניקוי סצנות צפופות או הבטחת התאמה בין סוגי מפות שונים. מאמר זה מציג שיטה חדשה לעריכה אוטומטית של תמונות לוויין באמצעות בינה מלאכותית, כך שניתן להסיר, להוסיף, להזיז או לשנות צורת מבנים ודרכים כשהתמונה נותרת טבעית ומשכנעת. 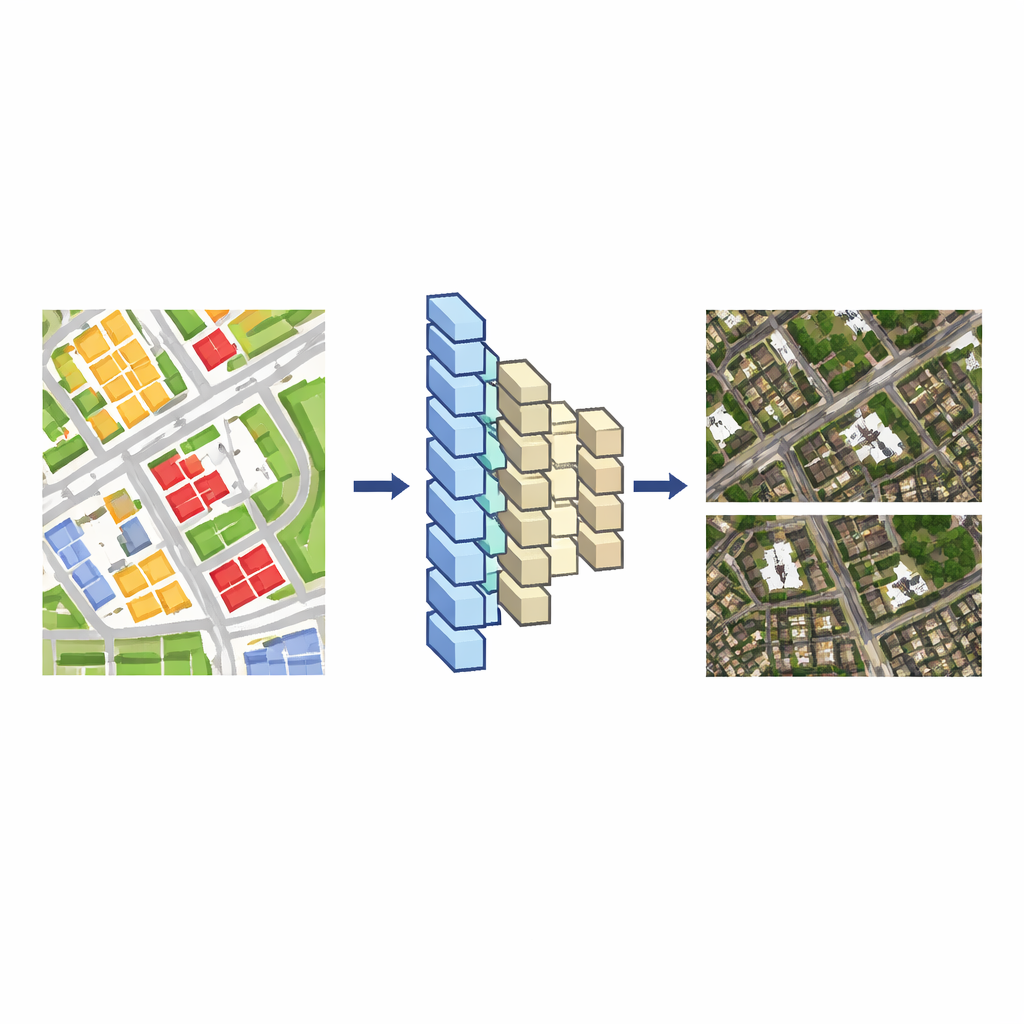
מציורים פשוטים לתצוגות מציאותיות
מערכות מפות מודרניות בדרך כלל מחזיקות שני סוגי נתונים גאוגרפיים. אחד הוא תמונת הלוויין עצמה, אריג צפוף של פיקסלים. השני הוא מפת וקטור, ציור נקי יותר המורכב מקווים וצורות שמסמנים דרכים, מבנים, נהרות ועוד. עריכת מפת הווקטור יחסית קלה, אך שינוי תמונת הלוויין התואמת בעבודת יד איטי ומייגע, משום שפיקסלי כל מבנה מתמזגים עם צללים, עצים ומבנים סמוכים. הרעיון המרכזי של המחברים הוא ללמד מודל למידה עמוקה לתרגם מהציורים הווקטוריים האלה לתמונות לוויין ריאליסטיות. ברגע שהמודל לומד את הקישור הזה, כל שינוי במפת הווקטור יכול להיות מומר אוטומטית לשינוי עקבי בתצוגת הלוויין.
ללמד בינה לדמות ערים
כדי לבנות את המתרגם הזה, החוקרים מתחילים באזורים שבהם מפת הווקטור ותמונת הלוויין מכסות את אותו אזור בקנה מידה דומה. הם חתכים את שניהם לריבוי אריחים קטנים, זוגות כל אריח וקטור לאריח תמונה תואם, ומשתמשים בזוגות אלה כנתוני אימון. רשת עצבית מקודדת–מפענחת — בדומה לכלים המשמשים לתרגום תמונה-לתמונה — לומדת כיצד סידור החסימות והקווים הצבעוניים באריח הווקטור קשור למשטחי גגות, רחובות וצמחייה באריח הלוויין. הם משווים שתי אדריכלויות רשת פופולריות, UNet++ ו-Pix2Pix, ומוצאים ש-Pix2Pix מייצרת תמונות דומות ללוויין שיותר תואמות למציאות ומתאמנת באופן אמין, לכן היא הופכת להיות המודל הבסיסי שלהם.
למקד את המודל במקומות לשינוי
למידה מהעיר כולה אינה מספיקה כשמטרתכם לשנות עצמים ספציפיים באופן נקי. כדי לחדד את מיומנות המודל סביב אזורים יעד, המחברים משתמשים בלמידת העברה. הם מוציאים אריחי אימון נוספים שמקיפים את המבנים או הדרכים שהם מתכננים לערוך ומריצים שלב אימון נוסף קצר שמשתמש רק בדוגמאות מקומיות אלה. שלב הכוונון העדין הזה משפר משמעותית את יכולת המודל לשחזר את השכונות הללו, מה שהופך את העריכות הבאות לחדות ומדויקות יותר. 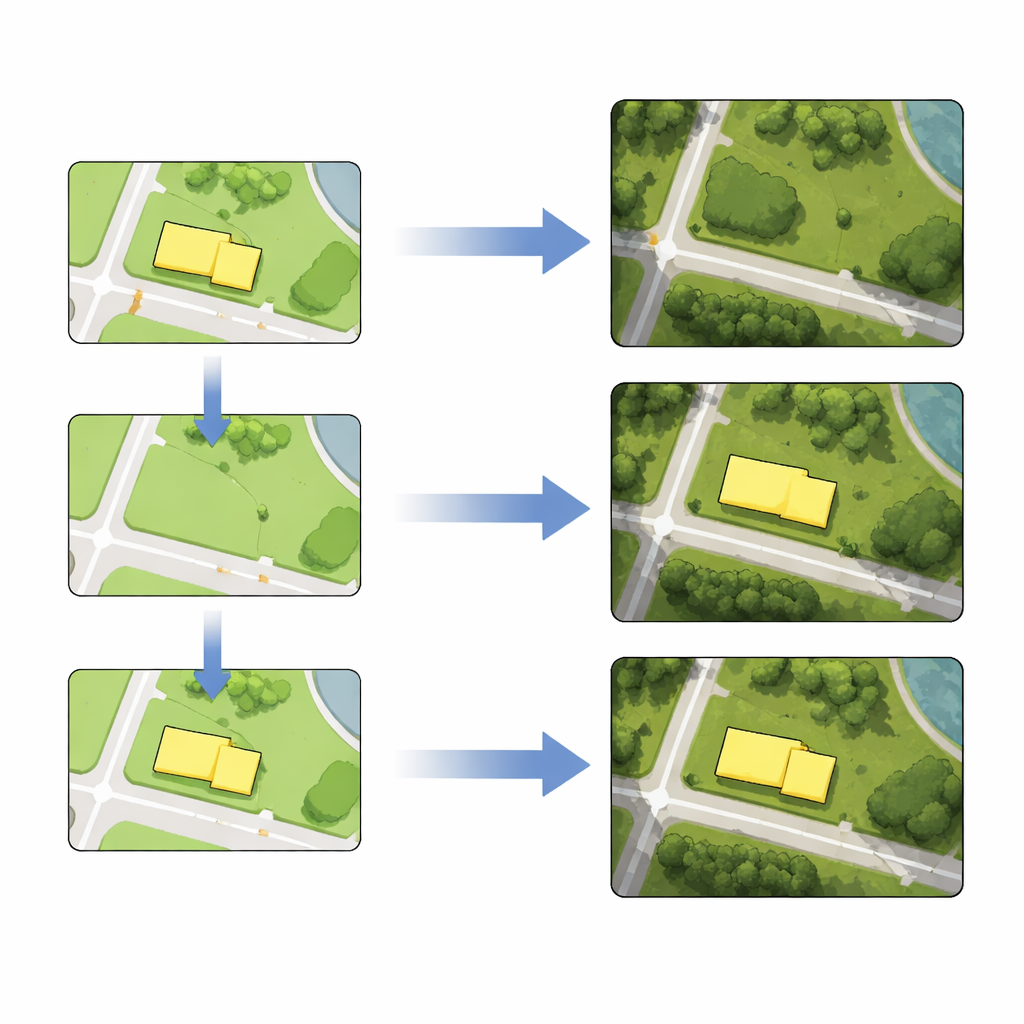
לערוך מבנים ודרכים כמו שכבות מפה
עם המודל המכוון במקום, יצירת מפות תמונת לוויין הופכת למתכון בשלושה שלבים. ראשית, ממפה עורכת את מפת הווקטור: מחיקת מבנה, שרטוט דרך חדשה, שינוי צורת בלוק או העתקת אובייקט למיקום חדש. שנית, האריחים הערוכים ממפת הווקטור מוזנים לרשת המאומנת, שמייצרת אריחי לוויין חדשים המשקפים את השינוי הרצוי תוך שמירה על פרטים וטקסטורות מסביב. שלישית, אריחים מיוצרים אלה מחליפים את אריחי התמונה המקוריים. באמצעות נתונים אמיתיים מברלין, המחברים מדגימים את ארבעת הפעולות — מחיקה, הכנסת אובייקט, עיוות והזזה — עבור טביעות רגל של מבנים וקווי דרך, או אחד אחד או בקבוצות. מדידות מראות שמיקומי האובייקטים הערוכים בתמונות המיוצרות שונים ממקביליהם הווקטוריים רק בכמה פיקסלים, דיוק שמקובל למשימות מיפוי רבות.
מה המשמעות של זה עבור מפות עתידיות
במילים פשוטות, המחקר מבהיר שבעת שה-AI לומד כיצד מפת וקטור ותמונות לוויין תואמות זו לזו, אפשר לערוך את הציור הפשוט ולתת למודל לצבוע מחדש תצוגה אווירית אמינה שתתאים. זה פותח אפשרות למפות תמונת לוויין שניתן להתאימן: להסתיר אתרים רגישים, להבהיר סצנות מורכבות או למזג מרחבים אמיתיים ודמיוניים כמו עולמות משחק וסביבות וירטואליות. בו בזמן, זה מדגיש את הכוח — והסיכון — של "גאוגרפיית דיפפייק", שבה תמונות אוויריות שנראות מציאותיות עלולות שלא להיות צילומים פשוטים של העולם כפי שהוא.
ציטוט: Du, J., Zeng, D., Cai, K. et al. A method for compiling satellite image map geographic objects based on vector map data via deep learning. Sci Rep 16, 9295 (2026). https://doi.org/10.1038/s41598-026-39096-0
מילות מפתח: תמונות לוויין, למידה עמוקה, עריכת מפות, חישה מרחוק, קרטוגרפיית דיפפייק