Clear Sky Science · he
מודלים לשוניים גדולים מגלים השפעות דמויות דאנינג–קרוגר בבדיקה עובדתית רב־לשונית
מדוע בדיקה עובדתית חכמה חשובה לכולם
מידע שגוי מתפשט היום במהירות רבה יותר מאי־פעם ומשפיע על האמונות של אנשים בנושאים של בריאות, פוליטיקה, מדע וחיי היומיום. פלטפורמות וחדרי חדשות רבים מתחילים להסתמך על בינה מלאכותית — ובייחוד על מודלים לשוניים גדולים (LLMs) — כדי לעזור לבדוק האם טענות ויראליות נכונות או שגויות. המחקר הזה שואל שאלה שנראית פשוטה אך קריטית: כשמאפשרים למערכות אלה לשפוט עובדות, כמה פעמים הן צודקות, עד כמה הן נראות בטוחות בעצמן והאם זה משתנה בין שפות ואזורים בעולם?
כיצד החוקרים בדקו את ה‑AI מול שמועות מהעולם האמיתי
במקום להמציא דוגמאות מלאכותיות, המחברים בנו את הבדיקות מתוך 5,000 טענות אמיתיות שחברות בדיקה עובדתית מקצועיות ברחבי העולם כבר חקרו. הטענות כיסו 47 שפות ובאו הן מהצפון הגלובלי והן מהדרום הגלובלי, ושקפו את המציאות העמוסה והרב־תרבותית של שמועות ברשת. נכללו רק הצהרות עם פסיקה ברורה של "נכון" או "שקר" — מוסכמות על ידי מספר בודקנים — כדי ליצור אמת בסיסית חזקה להשוואה.
לאחר מכן הריצו תשעה מודלים לשוניים נפוצים, ממערכות קטנות בקוד פתוח ועד מסחריות מתקדמות, על כל טענה. כדי לשקף כיצד אנשים אכן מדברים עם צ׳אטבוטים, רוב ההנחיות היו שאלות פשוטות כמו "האם זה נכון?" או "האם זה שקר?", בניסוח השפה של הטענה. מערך רביעי, בסגנון מקצועי יותר, השתמש בהוראה מפורטת באנגלית שהפכה את המודל לבודק עובדות ודרשה פלט מובנה. אנוטטורים אנושיים קראו בקפידה את תשובות המודלים וסווגו אותן כטוענות שהטענה נכונה, שקרית, או מסרבות לתת פסיקה ברורה.
לא רק צודק או טועה — גם מתי לומר "אני לא יודע"
הצוות עשה יותר מאשר לספור הצלחות וכישלונות. הם השתמשו בשלושה מדדים מרכזיים לכידת התנהגות המודלים. ראשית, "דיוק סלקטיבי" בחן כמה פעמים המודל היה נכון כאשר הוא התייצב וקבע שטענה היא נכונה או שקרית. שנית, "דיוק ידידותי-הימנעות" ראה בכך מקובל ואפילו רצוי שהמודל יודה בחוסר ודאות במקום לנחש — דבר חיוני בתחומים רגישים כמו רפואה או בחירות. שלישית, "שיעור הבטחון" עקב כמה פעמים המודל נתן תשובה מוחלטת, כמדד גס לאופן שבו הוא התנהג בביטחון.
ההנחיה בסגנון מקצועי, עם הדרכה שלב־אחר־שלב, שיפרה בעקביות את הדיוק בכל המודלים. אבל היא גם חשפה פשרה: מודלים קטנים הפכו לעתים למוחלטים יותר מבלי להיות אמינים יותר, בעוד שמודלים גדולים השתמשו במבנה כדי לתת פחות תשובות אך טובות יותר. הנחיות יומיומיות בסגנון שיחה הניבו התנהגות זהירה יותר, במיוחד במודלים חלשים, אך גם הורידו במידה מסוימת את הדיוק שלהם.
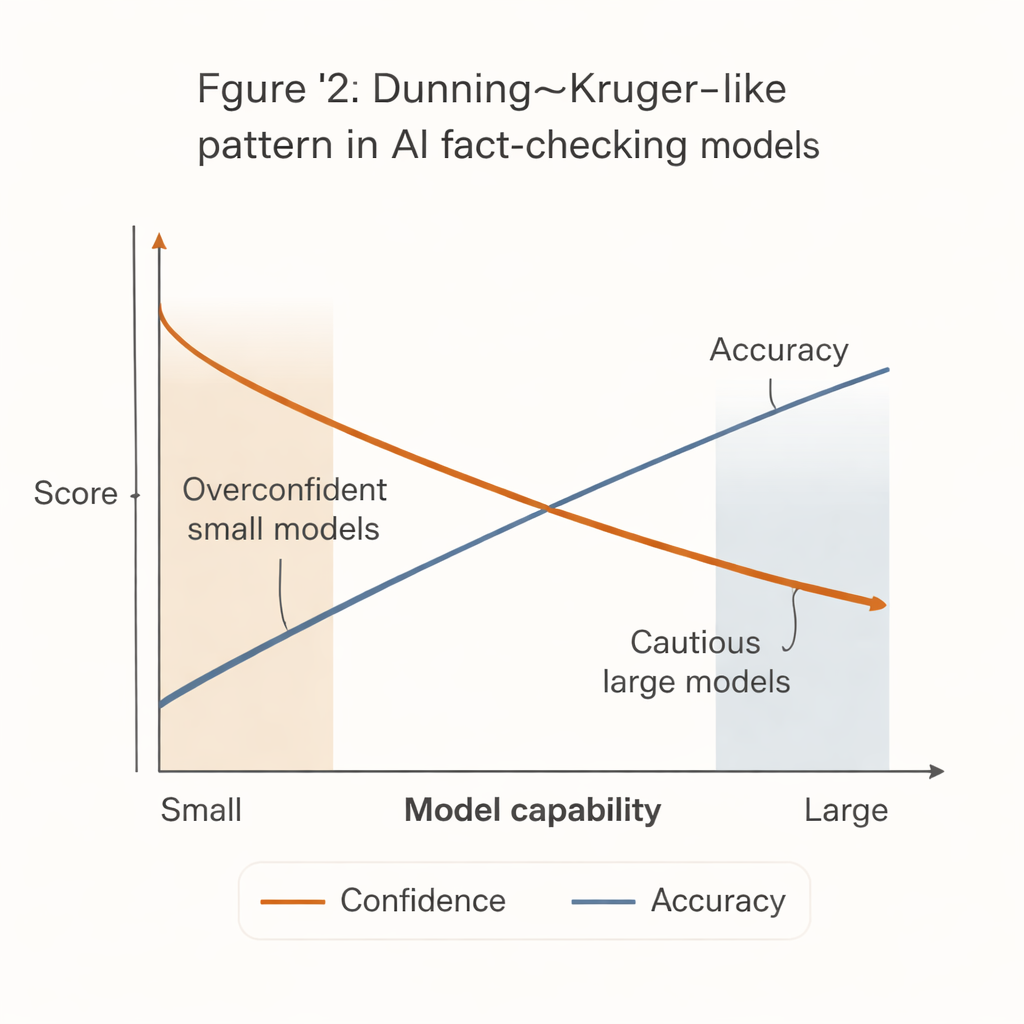
כאשר מערכות פחות יכולות מתנהגות בביטחון רב יותר
נוצר דפוס בולט המשקף את אפקט דאנינג–קרוגר המוכר מפסיכולוגיה אנושית: המערכות הפחות יכולות נראו הכי בטוחות בעצמן. מודלים קטנים וזולים נטו להנפיק פסיקות קשוחות על מרבית הטענות, אך עם דיוק נמוך משמעותית. לעומת זאת, המודלים החזקים ביותר — כגון גרסאות GPT מתקדמות — היו מדויקים בהרבה כאשר התחייבו, אך נוטים בהרבה להימנע מלהכריע, במיוחד בטענות קשות או עמומות.
פער ה"ביטחון–מומחיות" הזה יש לו השלכות בעולם האמיתי. חדרי חדשות, ארגוני חברה אזרחית ומערכי בדיקה מקומיים רבים שאין להם משאבים לא יכולים להרשות לעצמם את מערכות ה‑AI החזקות ביותר. הם נוטים לאמץ מודלים קטנים וזולים שנראים תקיפים אך טועים בתדירות גבוהה יותר. אם כלים אלה ישולבו בעבודה שוטפת או במערכות מתן חוק קהילתיות בלי זהירות נאותה, הם עלולים דווקא להגביר את המידע השגוי על‑ידי יצירת בדיקות עובדתיות בטוחות אך שגויות.
ביצועים לא שווים בין שפות ואזורים
המחקר גם מראה שמערכות אלה אינן מתפקדות שווה לכולם. במספר שפות מרכזיות, המודלים בדרך כלל היו הטובים ביותר בטענות באנגלית וקצת פחות בפורטוגזית והינדי. מודלים גדולים נטו להגיב בזהירות רבה יותר בשפות שאינן אנגלית, אך עדיין התעלו על מודלים קטנים מבחינת דיוק. כאשר המחברים השוו טענות הקשורות לצפון הגלובלי ולדרום הגלובלי, רוב המודלים התקשו יותר על אלה של הדרום. במערכות קטנות נותרו ביטחוניות בעוד שהדיוק ירד, בעוד שמודלים גדולים הראו ירידה גדולה יותר בשיעור הבטחון אך ירידה קטנה יותר בנכונות, מה שמרמז שהם חשים בחוסר הוודאות שלהם ומסתייגים.
מתי־כלי אמין בעתיד של בינה אמינה
ללא־מומחה, המסר המרכזי ברור: בודקי העובדות המבוססי AI של היום רחוקים מלהיות שווים, והנגישים ביותר עלולים להיות המטעה ביותר. מודלים חזקים יכולים להיות זהירים ומדויקים, אך הם יקרים ולעתים מהססים יותר מדי. מודלים חלשים נועזים אך סביר שיהיו שגויים יותר, במיוחד מחוץ לאנגלית ובסיפורים מהדרום הגלובלי. המחברים טוענים שיש להשתמש ב‑AI כתמיכה ולא להחליף בו את הבודקים האנושיים, וכי החלטות מדיניות ועיצוב צריכות לדחוף לכיוון כיול טוב יותר — ללמד מערכות מתי לשתוק — ולגישה הוגנת לכלים איכותיים. אחרת, אותה טכנולוגיה שנבנתה להילחם במידע שגוי עלולה להעמיק את אי־השוויון במידע שהיא אמורה לפתור.
ציטוט: Qazi, I.A., Khan, Z., Ghani, A. et al. Large language models show Dunning-Kruger-like effects in multilingual fact-checking. Sci Rep 16, 7594 (2026). https://doi.org/10.1038/s41598-026-39046-w
מילות מפתח: מידע שגוי, בדיקה עובדתית, מודלים לשוניים גדולים, ביטחון מלאכותי, הטייה רב־לשונית